奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式
奖励模型也能Scaling!上海AI Lab突破强化学习短板,提出策略判别学习新范式强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
来自主题: AI技术研报
8314 点击 2025-07-12 11:51
 搜索
搜索
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
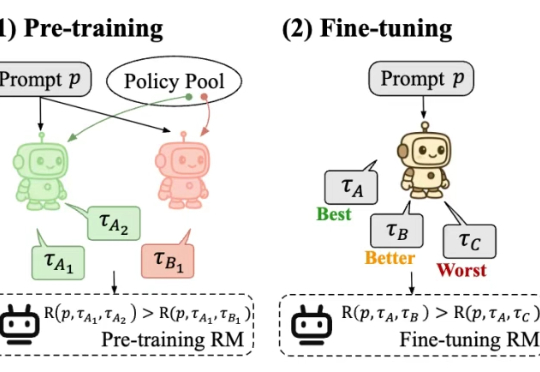
最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

新晋AI编程冠军DeepSWE来了!仅通过纯强化学习拿下基准测试59%的准确率,凭啥?7大算法细节首次全公开。
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
2017 年,一篇《Attention Is All You Need》论文成为 AI 发展的一个重要分水岭,其中提出的 Transformer 依然是现今主流语言模型的基础范式。尤其是在基于 Transformer 的语言模型的 Scaling Law 得到实验验证后,AI 领域的发展更是进入了快车道。
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。
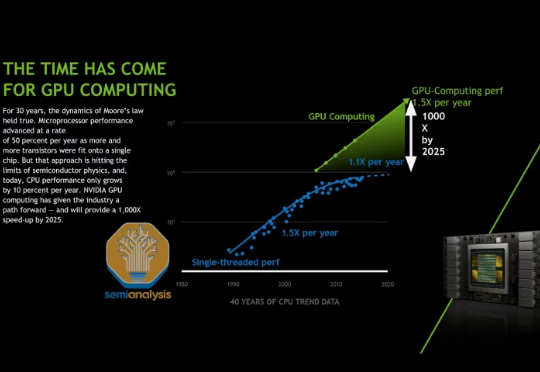
在我们去年 AI Scaling Laws article from late last year中,我们探讨了多层 AI 扩展定律如何持续推动 AI 行业向前发展,使得模型能力的增长速度超过了摩尔定律,并且单位 token 成本也相应地迅速降低。
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。

CVPR 2025,自动驾驶传来重大进展: Scaling Law,首次在这条赛道被验证!