
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文Spotlight
AI生成的图片正在反向对齐人类的审美?ICML 2026观点论文SpotlightUBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
来自主题: AI技术研报
6825 点击 2026-06-25 10:03
 搜索
搜索
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
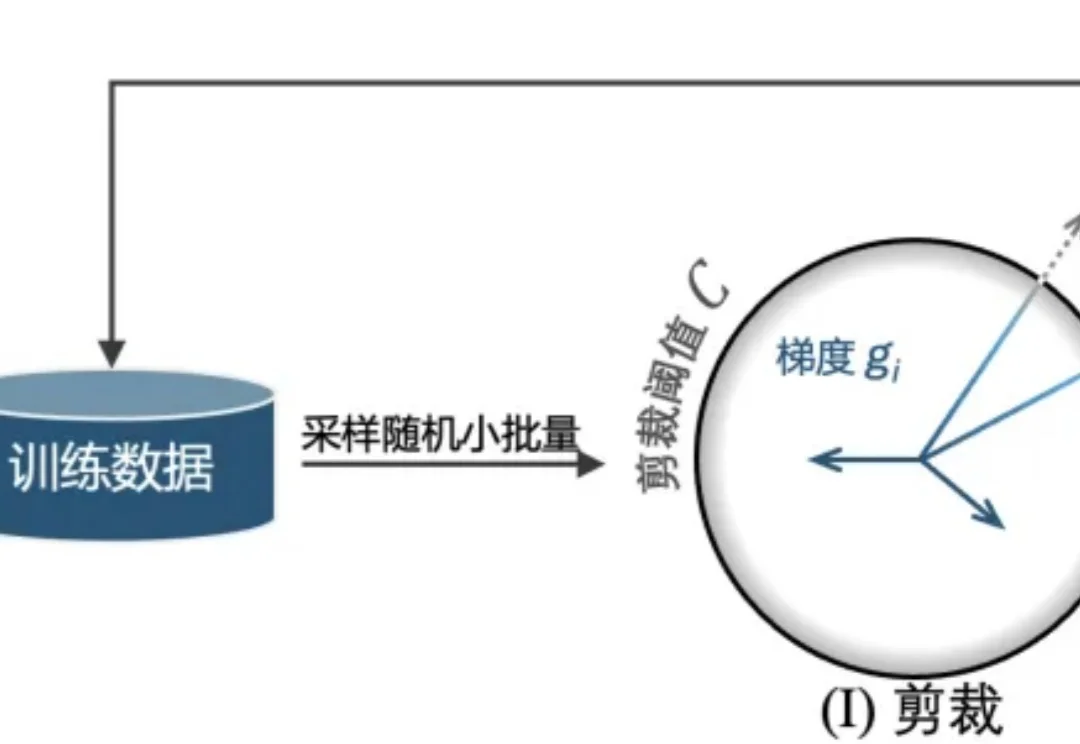
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
被ICML 2026接收为Spotlight!
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。
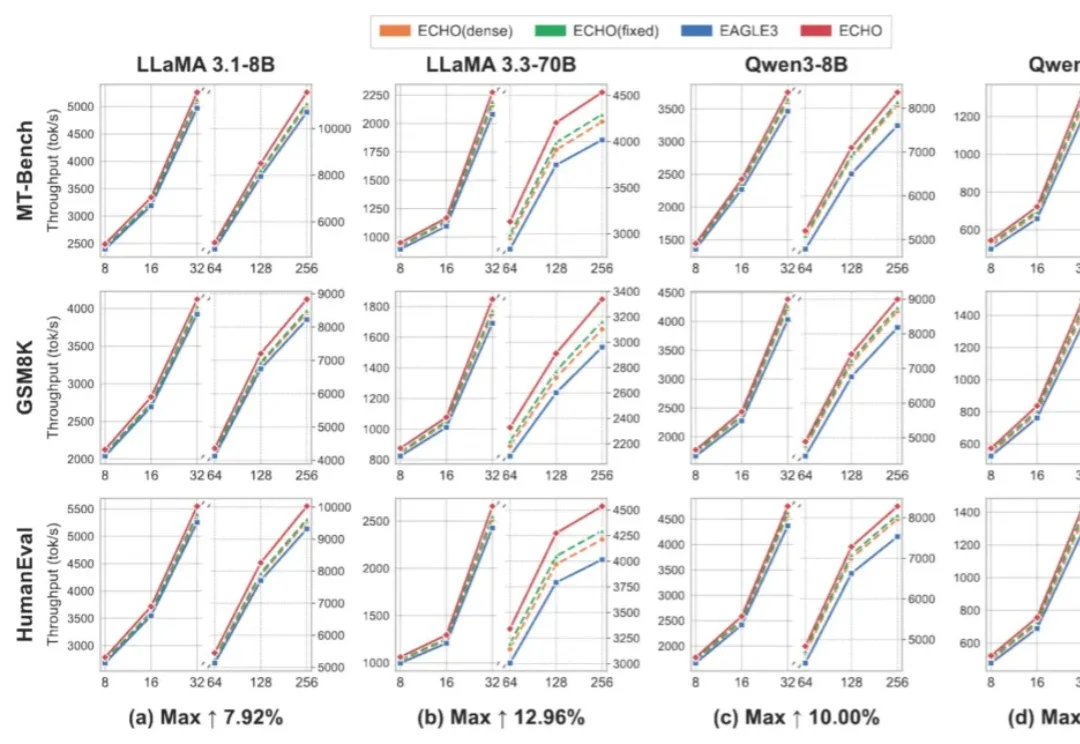
随着大模型参数规模持续扩大,推理成本已经成为生产级 LLM 服务的核心瓶颈。投机解码(Speculative Decoding, SD)通过「小模型 draft + 大模型 verify」的方式,将多个候选 token 放到一次目标模型前向中并行验证,从而缓解自回归解码的串行瓶颈。

当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。

在视觉处理任务中,Vision Transformers(ViTs)已发展成为主流架构。然而,近期研究表明,ViT 模型的密集特征中会出现部分与局部语义不一致的伪影(artifact),进而削弱模型在精细定位类任务中的性能表现。因此,如何在不耗费大量计算资源的前提下,保留 ViT 模型预训练核心信息并消除密集特征中的伪影?
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。

在三维视觉领域,3D Gaussian Splatting (3DGS) 是近年来大热的三维场景建模方法。它通过成千上万的高斯球在空间中“泼洒”,拼合成一个高质量的三维世界,就像是把一片空白的舞台,用彩色的光斑和粒子逐渐铺满,最后呈现出一幅立体的画卷。
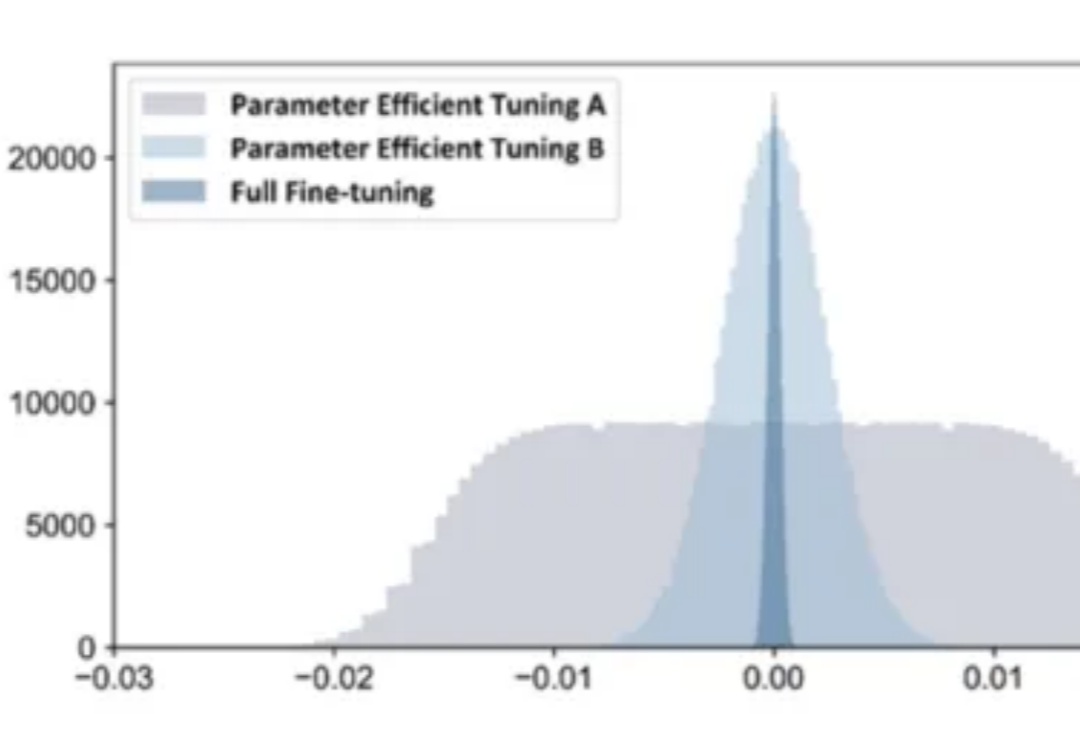
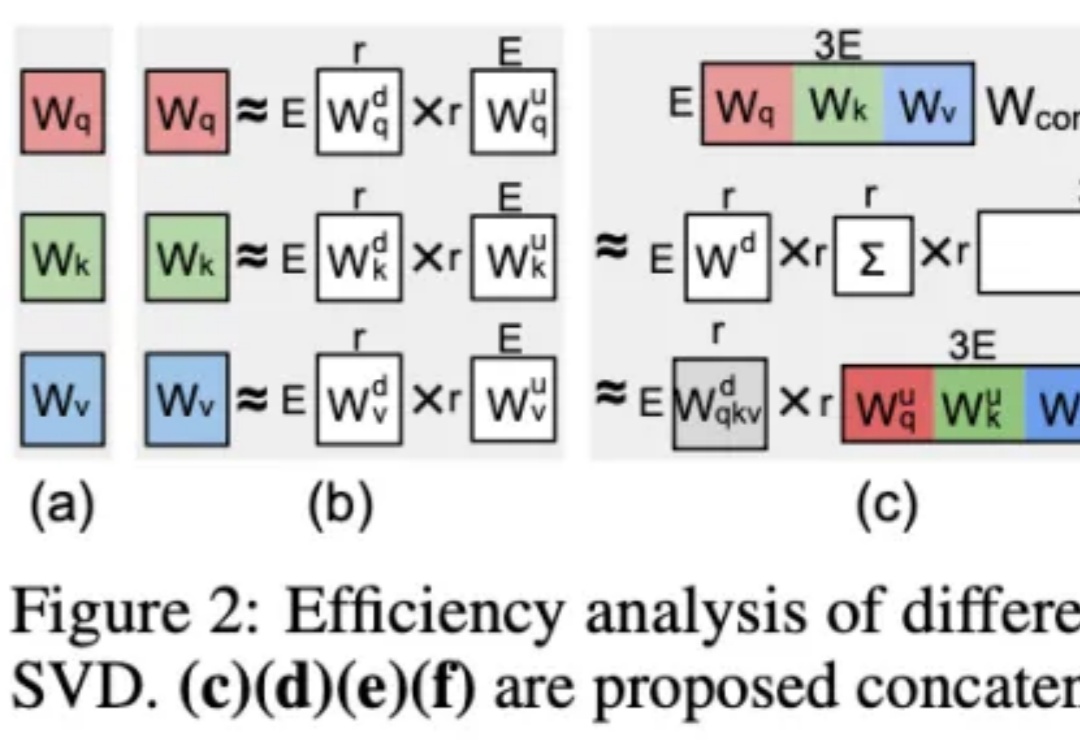
在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。