
AI人的文明祭祀:清明节烧 Token 指南
AI人的文明祭祀:清明节烧 Token 指南先人用你烧的 token 跑完了推理,生成了一段回复,可以通过托梦返回给你。 今天是清明节。 每年这个时候,我都会想同一个问题:纸钱这玩意儿得有多毛啊? 这么多年,全国十几亿人往那边烧纸钱,面额还越来
来自主题: AI资讯
9939 点击 2026-04-06 10:21
 搜索
搜索
先人用你烧的 token 跑完了推理,生成了一段回复,可以通过托梦返回给你。 今天是清明节。 每年这个时候,我都会想同一个问题:纸钱这玩意儿得有多毛啊? 这么多年,全国十几亿人往那边烧纸钱,面额还越来

Agent 时代,我们需要正确的计费和工程设计哲学,这是 Xiaomi MiMo 大模型负责人罗福莉刚刚在 X 上发表的观点。前两天,我们报道了一则消息 ——Anthropic 宣布,即日起,Claude Pro 和 Max 订阅用户,不得再将订阅额度用于 OpenClaw 等第三方 Agent 框架。想继续用?那就必须切换到按用量付费的 API。
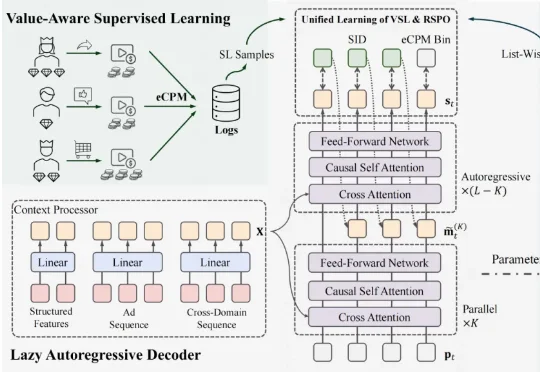
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。

2025 年以来,大模型的能力边界被不断刷新。但对于大多数开发者和用户而言,“用得起”仍然是比“好不好用”更前置的问题。按量计费的模式下,每一次调用都伴随着对成本的不确定。 我们不希望这样。我们相信—

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。

甲骨文凌晨突发裁员,不是愚人节玩笑。

DigClaw 创始团队意识到,快速变革的AI时代下,利用大模型捕捉并处理这些商业“弱信号”成为可能,而这将彻底重构 B2B 获客的基础设施。2025 年,DigClaw 正式起航,试图用 AI 重构信息基础设施,用商业“弱信号”识别“你在什么阶段、什么业务、什么场景之下需要什么产品”,并转化为 B2B 企业可落地的商业阿尔法。

我自己用 Coding Plan 也有一段时间了,最开始只是为了省点 API 钱,后来各家陆续推出固定月费套餐,我发现选起来比想象中复杂。Codex、Claude Code、Cline、OpenClaw 这些工具让开发者越来越习惯用自然语言驱动代码生成和任务执行,但高频调用带来的 API 成本也成了一笔固定开销。

腾讯已上市两款类龙虾产品,即将上市的至少还有4款;

过去数月,AI 领域很难绕开一个名字 ——OpenClaw。这个项目在极短时间内获得了爆发式关注:数十万星标、惊人的 Token 消耗,以及几乎所有大厂的快速跟进。从表面上看,它像是又一个现象级 AI 产品;但如果进一步审视,一个更值得思考的问题随之浮现 ——OpenClaw 的出现,究竟意味着什么?它真的是一次技术突破,还是某种更深层变化的信号?