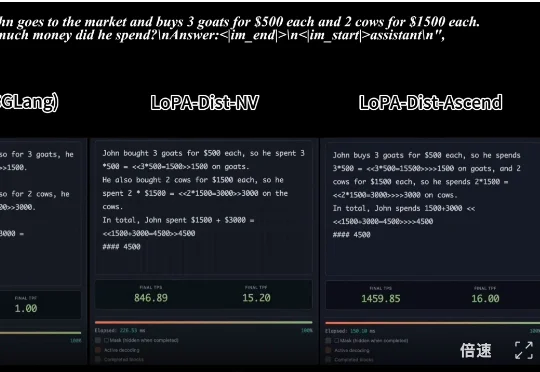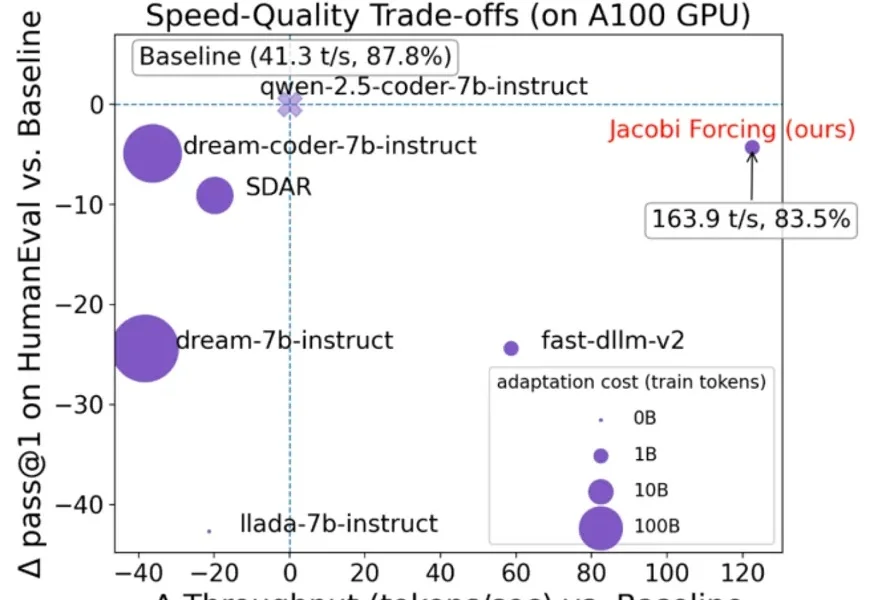
继2025推理模型之后,2026「递归模型」RLM要火了。
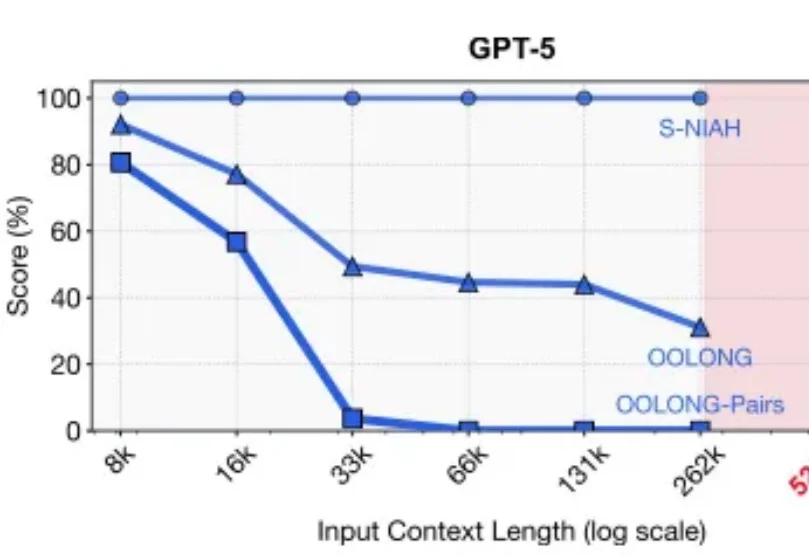
继2025推理模型之后,2026「递归模型」RLM要火了。2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。
来自主题: AI技术研报
6997 点击 2026-01-04 11:43