港科大Apple新研究:Tokens使用量减少,模型推理还更强了
港科大Apple新研究:Tokens使用量减少,模型推理还更强了1+1等于几?
来自主题: AI技术研报
8716 点击 2025-05-28 15:03
 搜索
搜索
1+1等于几?
是的,秘塔AI搜索推出了全新“极速”模型。通过在GPU上进行kernel fusion,以及在CPU上进行动态编译优化,我们在单张H800 GPU上实现了最高400 tokens/秒的响应速度,大部分问题2秒内就能答完。

谷歌又放新大招了,将图像生成常用的“扩散技术”引入语言模型,12秒能生成1万tokens。
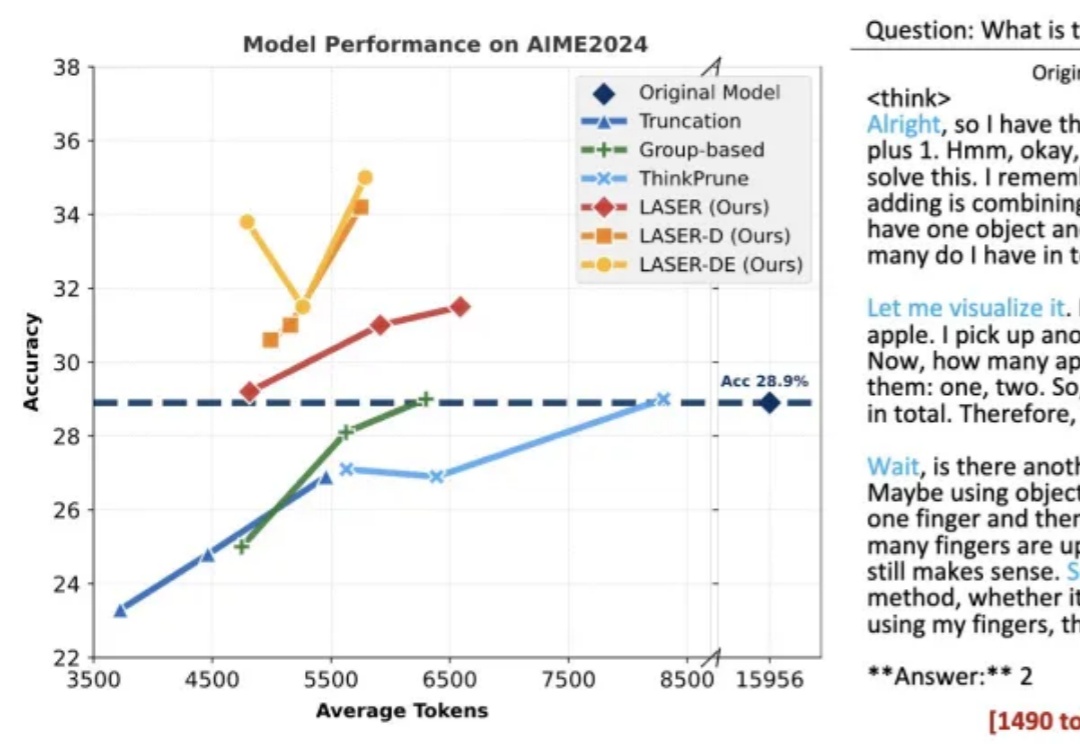
在当前大模型推理愈发复杂的时代,如何快速、高效地产生超长文本,成为了模型部署与优化中的一大核心挑战。
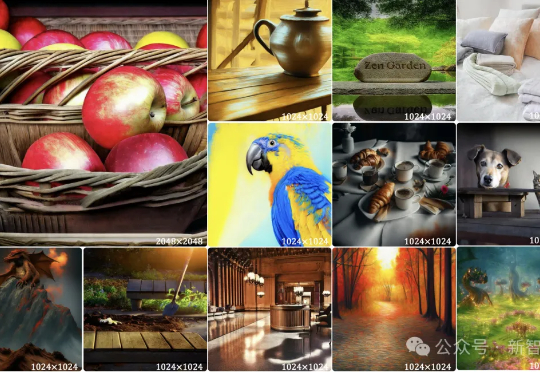
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:沉思模型GLM-Z1-Rumination 推理模型GLM-Z1-Air 基座模型GLM-4-Air-0414
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
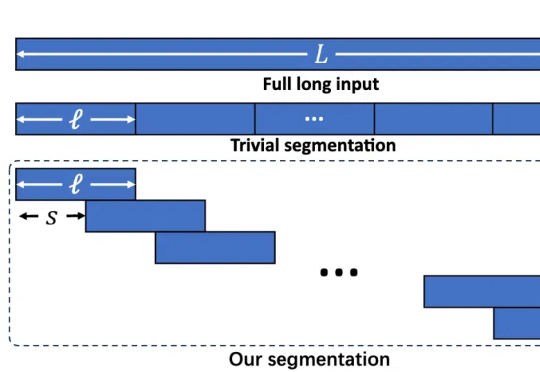
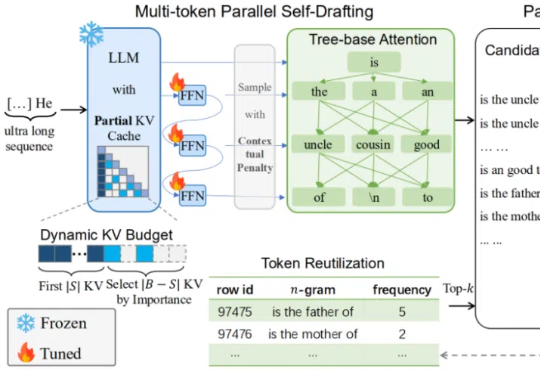
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。
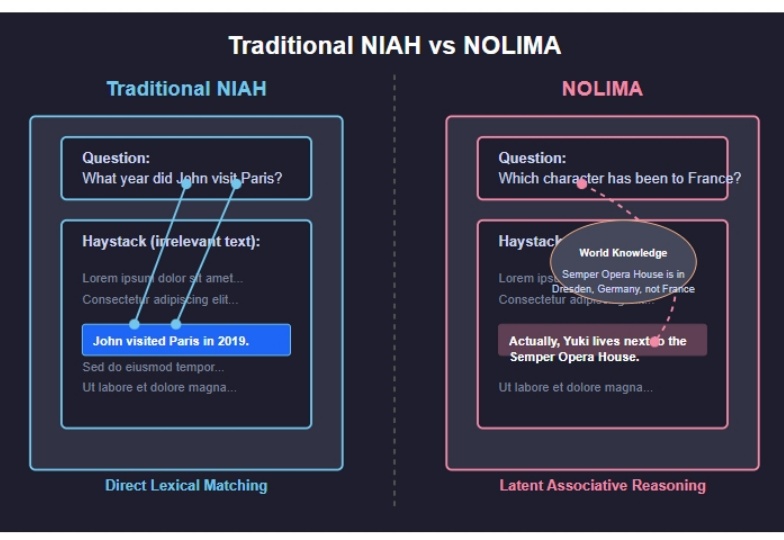
2025 年 2 月发布的 NoLiMA 是一种大语言模型(LLM)长文本理解能力评估方法。不同于传统“大海捞针”(Needle-in-a-Haystack, NIAH)测试依赖关键词匹配的做法,它最大的特点是 通过精心设计问题和关键信息,迫使模型进行深层语义理解和推理,才能从长文本中找到答案。
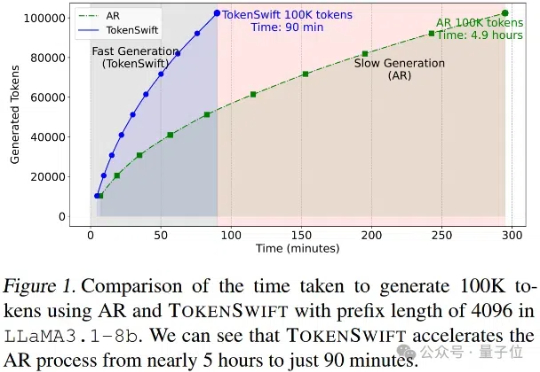
大语言模型长序列文本生成效率新突破——生成10万Token的文本,传统自回归模型需要近5个小时,现在仅需90分钟!