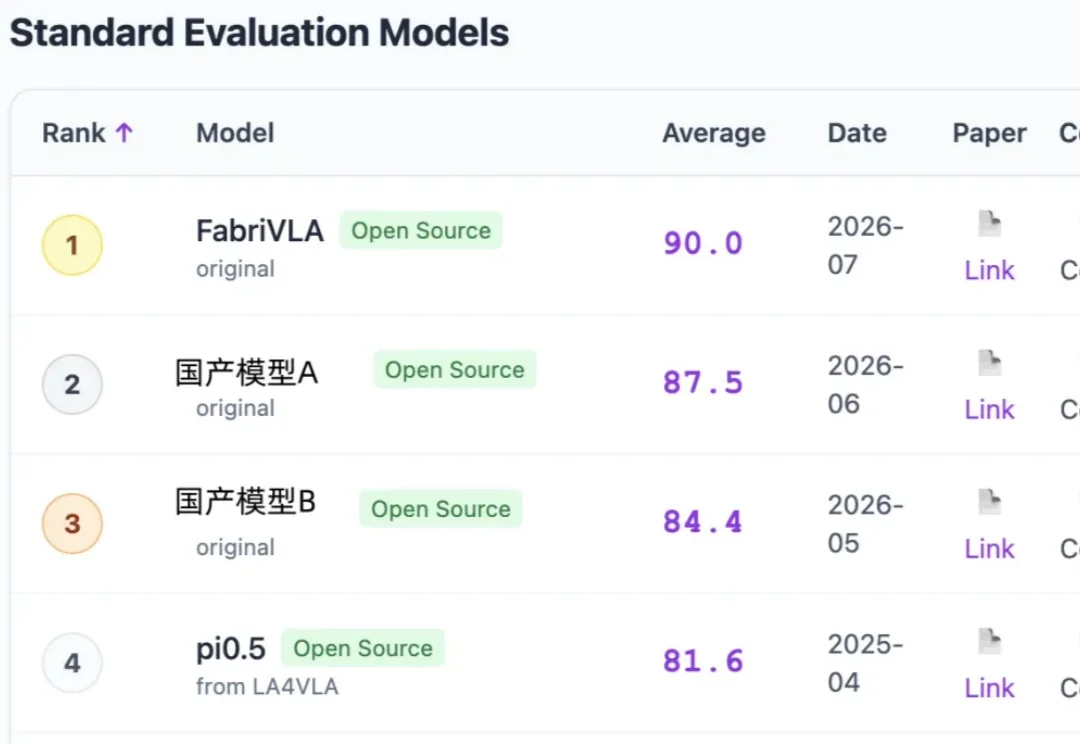
超越π0,中国团队用1B参数模型登顶具身智能榜单
超越π0,中国团队用1B参数模型登顶具身智能榜单谁能想到,在全球具身智能操作能力的顶级榜单上,打败海外标杆模型π0的,居然是一个只有1B级参数的轻量级模型。
来自主题: AI资讯
8868 点击 2026-07-23 16:33
 搜索
搜索
谁能想到,在全球具身智能操作能力的顶级榜单上,打败海外标杆模型π0的,居然是一个只有1B级参数的轻量级模型。
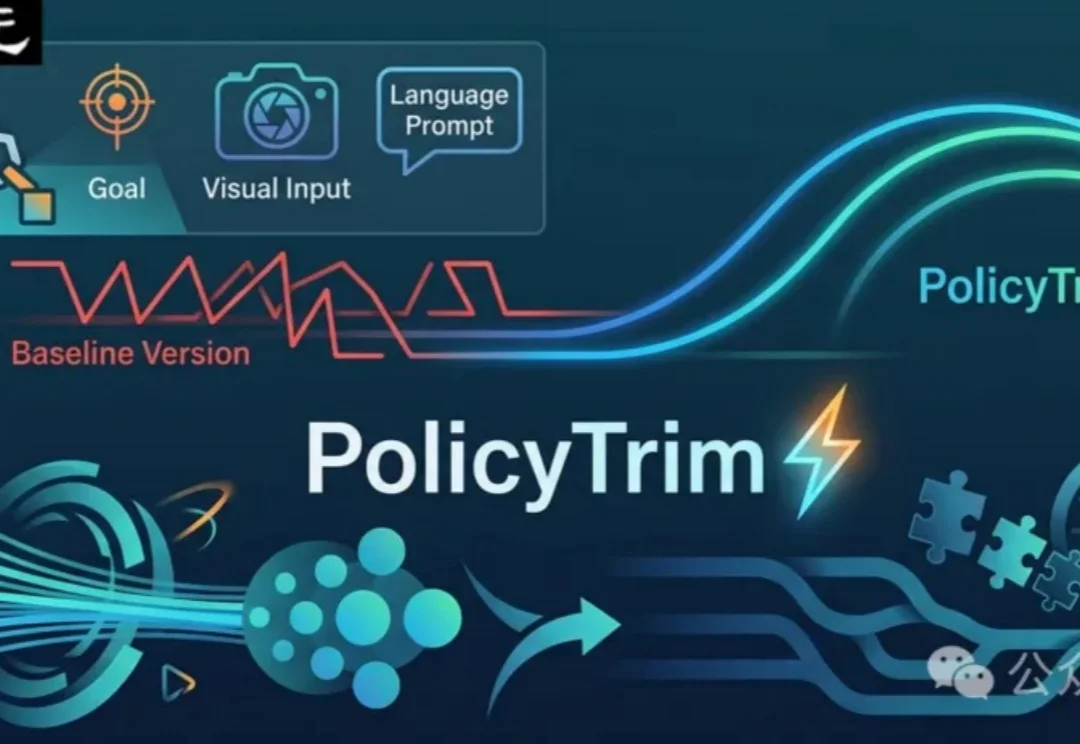
VLA模型已经会做任务,但真实机器人还是慢!PolicyTrim是一种优化VLA机器人执行效率的方法,无需重新训练。它通过扩展可靠动作序列并减少冗余步骤,帮助机器人更直接完成任务,提升整体速度。

一项机器人拼搭长城的展示火爆全网。从彩排现场的照片来看,围观者已经里三层外三层。原力灵机联合阶跃星辰,用 6 台机器人挑战 15 小时连续作业,搭建完成一座包含超 8 万个零件的长城模型 —— 最小组件不到 1 厘米宽,成品长 3.5 米、宽 1.5 米、高 1.1 米。其中 4 台桌面机器人负责精细零件的拼装,2 台轮式机器人 Apex 负责将拼装完成的组件运输、组装。
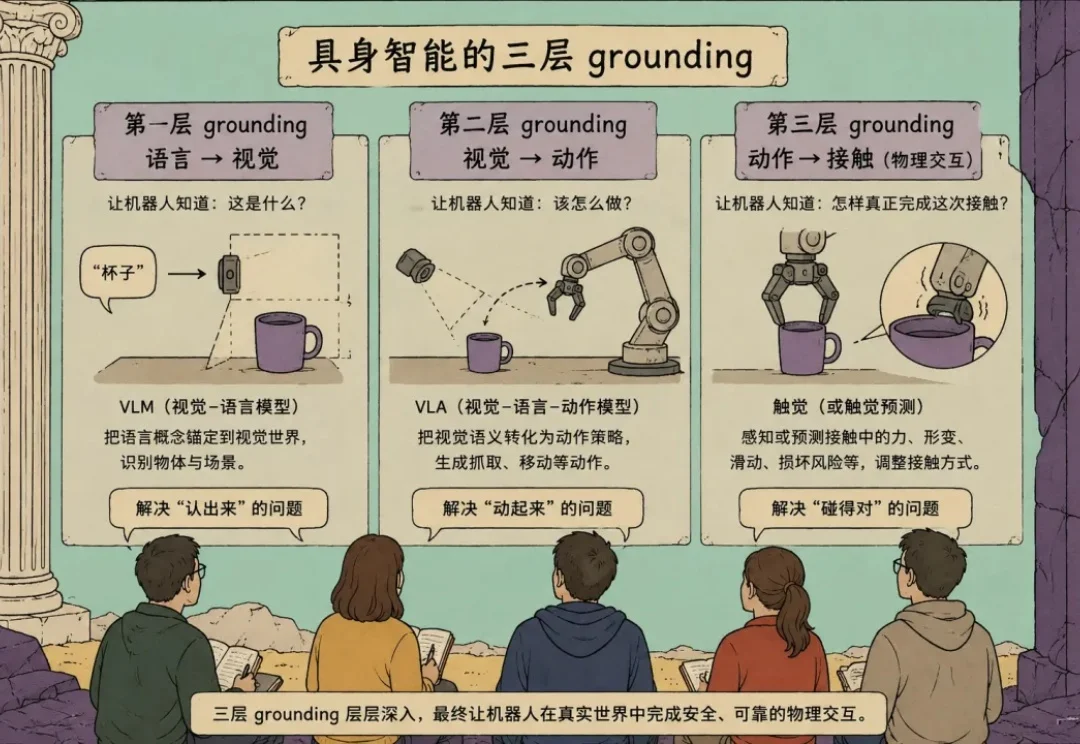
机器人,也开始拥有“触觉想象力”了。

音乐和视频之间那道墙,好像被打破了。 上个月,一个做独立音乐的朋友找我吃饭,聊到新歌宣发的事,愁得不行。 歌写好了,录完了,混音也做了,但到了要发的时候才发现,没有视觉内容。 发网易云?光秃秃一个音频

今天原力灵机正式发布的 DM0.5 往前推进了一步。它不只是继续提高某些固定任务上的表现,而是围绕真实世界里的泛化问题做了一次系统突。 如果深入分析,就会发现 DM0.5 这几个核心提升,都是想解决一个问题:如何让具身模型从可控环境里的能力演示,走向开放环境里的稳定执行。

当机器人后空翻刷屏时,代表小脑已经在快速进展。但你是否意识到,让机器人真正干活卡脖子的从来不是小脑,而是大脑?蚂蚁灵波刚刚开源的LingBot-VLA2.0,用同一套模型「驯服」了20种的机器人构型。行业终于有人开始认真算重复适配成本这笔账了。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。
最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。
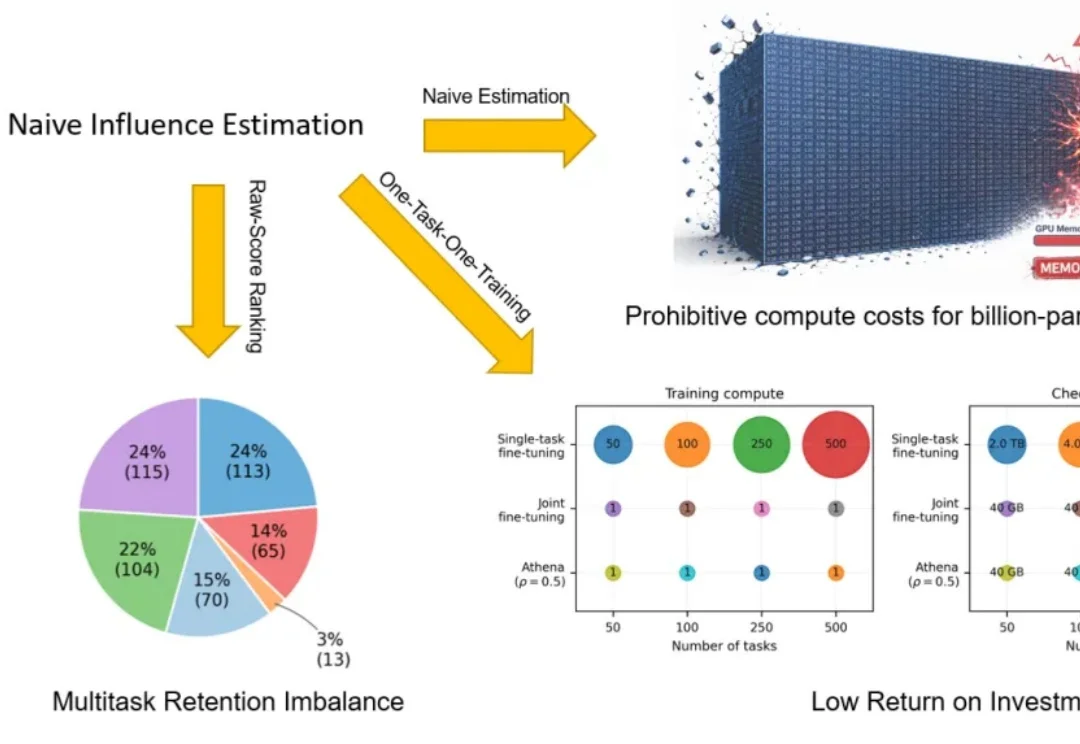
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。