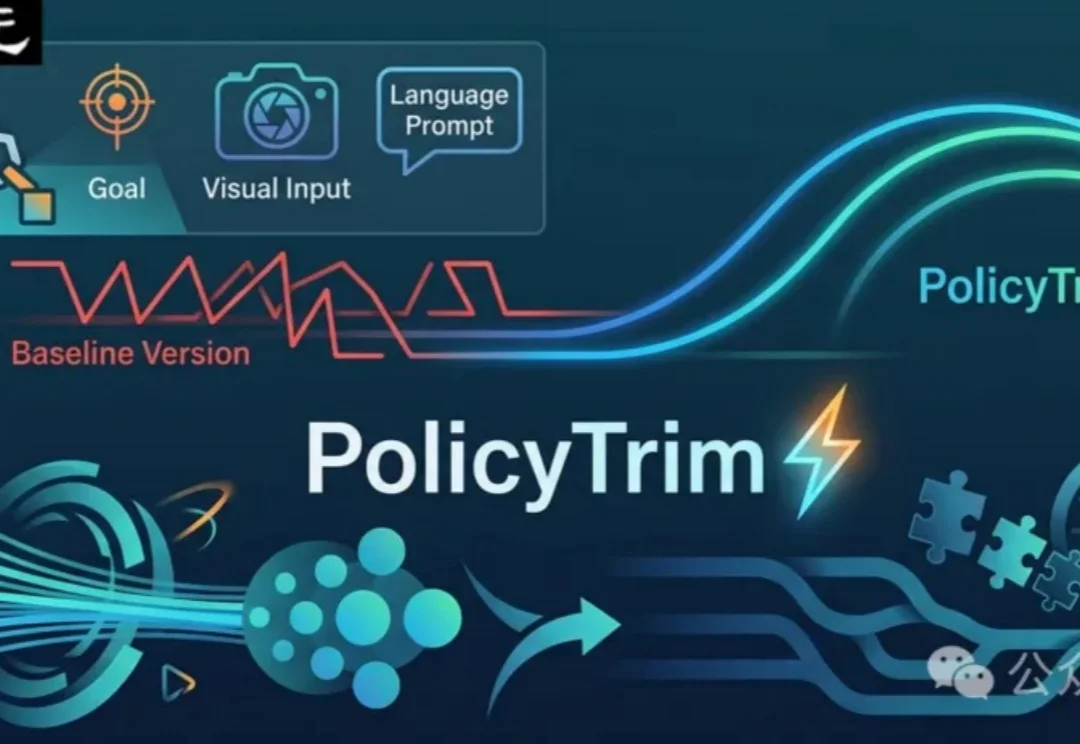
5.83倍加速!PolicyTrim:让VLA机器人少走弯路、更快完成任务
5.83倍加速!PolicyTrim:让VLA机器人少走弯路、更快完成任务VLA模型已经会做任务,但真实机器人还是慢!PolicyTrim是一种优化VLA机器人执行效率的方法,无需重新训练。它通过扩展可靠动作序列并减少冗余步骤,帮助机器人更直接完成任务,提升整体速度。
来自主题: AI技术研报
6086 点击 2026-07-22 10:09
 搜索
搜索
VLA模型已经会做任务,但真实机器人还是慢!PolicyTrim是一种优化VLA机器人执行效率的方法,无需重新训练。它通过扩展可靠动作序列并减少冗余步骤,帮助机器人更直接完成任务,提升整体速度。

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
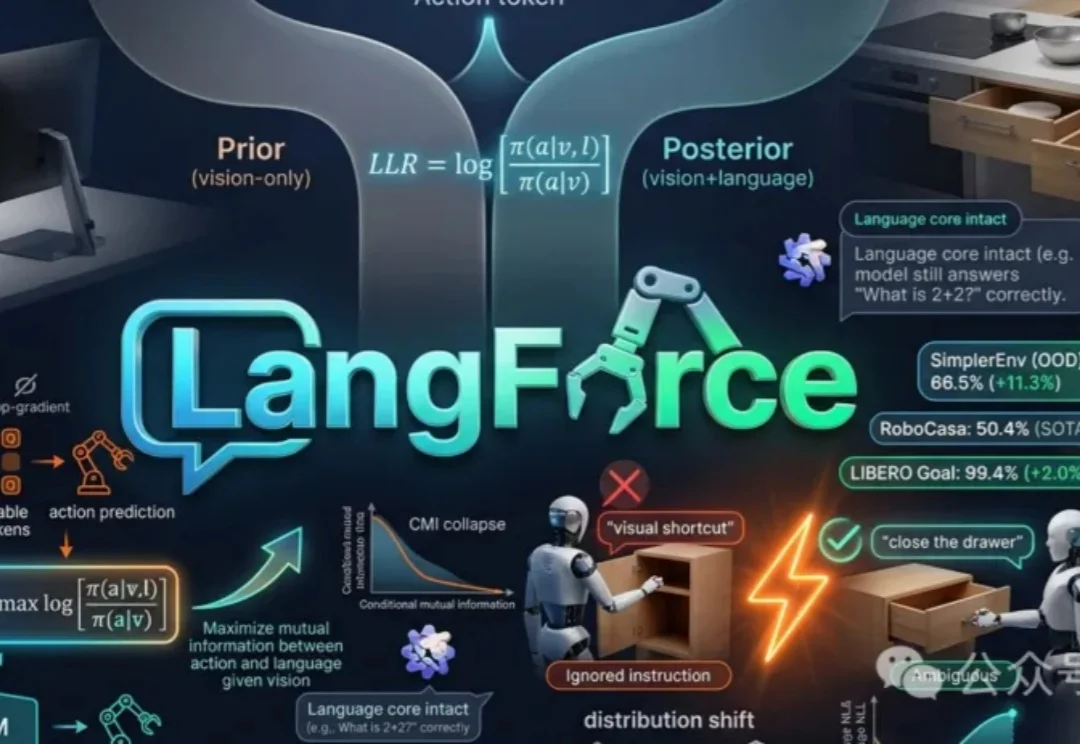
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。

这个月,具身智能领域又卷出新高度:硅谷独角兽公司 Generalist AI 发布全新一代基础模型 GEN-1,将机器人包装手机、折纸箱这些活的平均成功率直接拉到了创纪录的 99%,折纸箱的速度更是飙到了以前的三倍(34s vs 12.1s)。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。

LaST₀团队 投稿 量子位 | 公众号 QbitAI 近日,至简动力、北京大学、香港中文大学、北京人形机器人创新中心提出了一种名为LaST₀的全新隐空间推理VLA模型,在基于Transformer混
对于电子产品,我们已然习惯了「出厂即巅峰」的设定:开箱的那一刻往往就是性能的顶点,随后的每一天都在折旧。
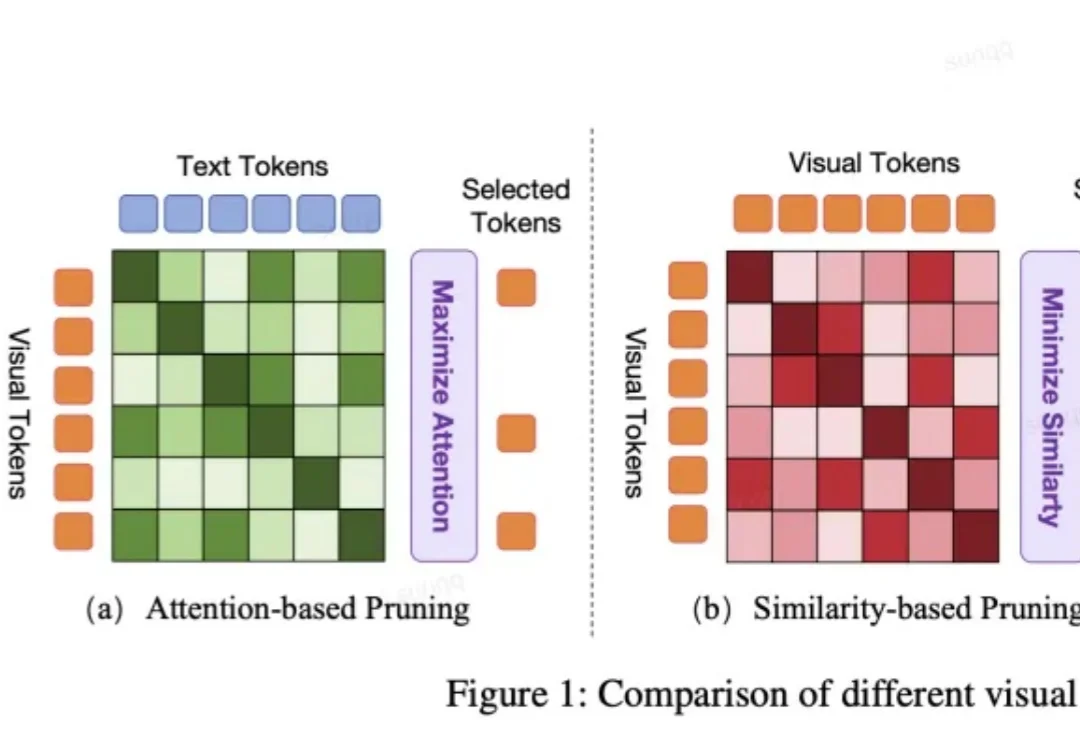
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。

VLA模型性能暴涨300%,背后训练数据还首次实现90%由世界模型生成。