北大新作EvoVLA:大幅降低机器人幻觉,长序列成功率暴涨10%
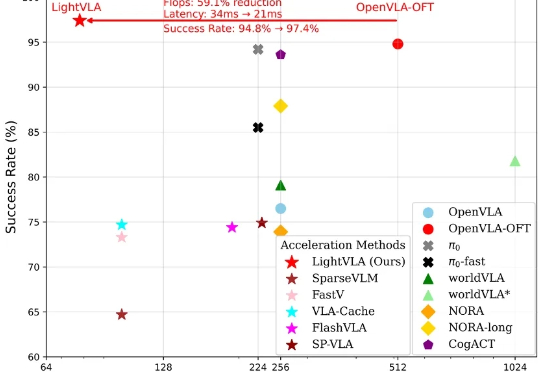
北大新作EvoVLA:大幅降低机器人幻觉,长序列成功率暴涨10%具身智能的「ChatGPT时刻」还没到,机器人的「幻觉」却先来了?在需要几十步操作的长序列任务中,现有的VLA模型经常「假装在干活」,误以为任务完成。针对这一痛点,北京大学团队提出自进化VLA框架EvoVLA。该模型利用Gemini生成「硬负样本」进行对比学习,配合几何探索与长程记忆,在复杂任务基准Discoverse-L上将成功率提升了10.2%,并将幻觉率从38.5%大幅降至14.8%。
来自主题: AI技术研报
9255 点击 2025-11-29 09:58