

物理AI的「原生」时刻:原力灵机发布具身大模型DM0
物理AI的「原生」时刻:原力灵机发布具身大模型DM0当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
来自主题: AI技术研报
6079 点击 2026-03-11 15:04
当前,大语言模型(LLMs)和视觉语言模型(VLMs)在语义领域的成功未能直接迁移至物理机器人,归根结底在于其互联网原生的基因。
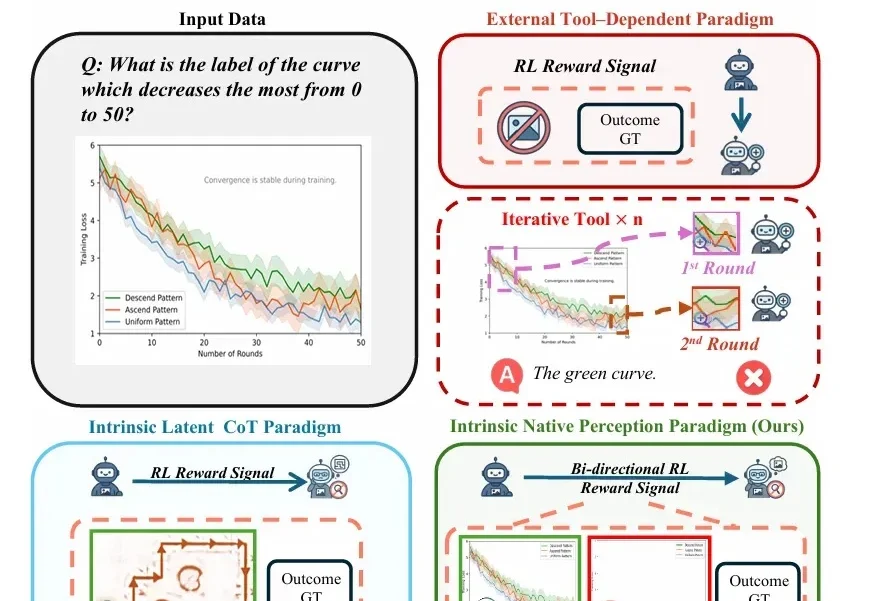
随着视觉-语言模型(VLM)推理能力不断增强,一个隐蔽的问题逐渐浮现: 很多错误不是推理没做好,而是“看错了”。
准备回家过年了吗?有没有感觉今年回家比去年还堵?据说今年春运流量再创新高,官方预计40天内人员流动量将达95亿人次,其中多数人仍然选择自驾出行,占比达到了8成,人次超过70亿。
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。

这一框架可用于集成额外文本、语音和视觉等多种模态。
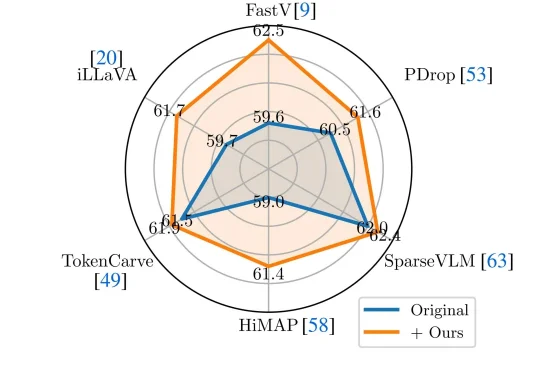
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。
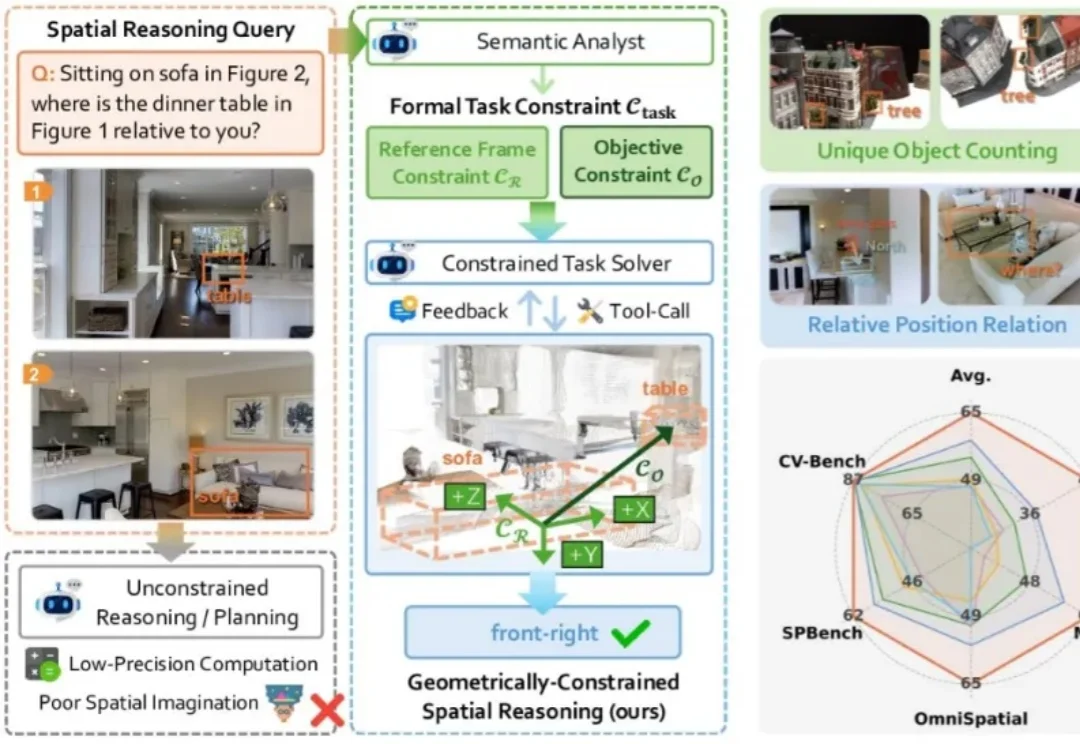
现有的视觉大模型普遍存在「语义-几何鸿沟」(Semantic-to-Geometric Gap),不仅分不清东南西北,更难以处理精确的空间量化任务。例如问「你坐在沙发上时,餐桌在你的哪一侧?」,VLM 常常答错。

大模型能写代码、解奥数,却连幼儿园小班都考不过?简单的连线找垃圾桶、数积木,人类一眼即知,AI却因为无法用语言「描述」视觉信息而集体翻车。大模型到底「懂不懂」,这个评测基准给出答案。
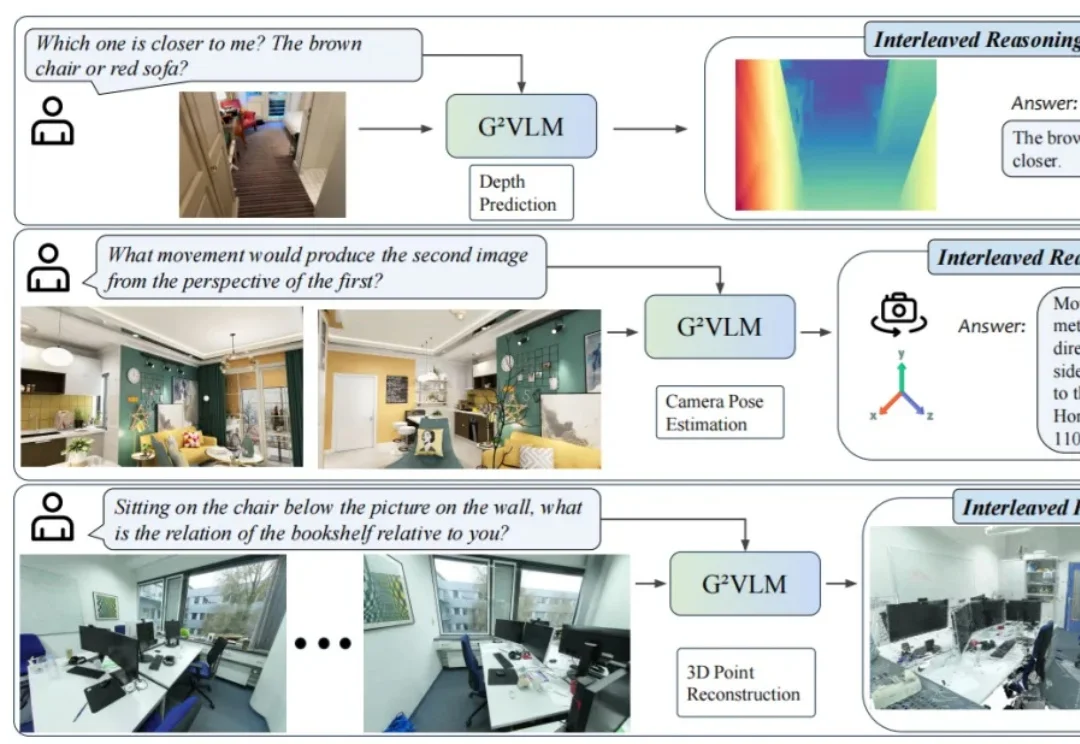
近日,24 岁的 00 后博士生胡文博和所在团队造出一款名为 G²VLM 的超级 AI 模型,它是一位拥有空间超能力的视觉语言小能手,不仅能从普通的平面图片中精准地重建出三维世界,还能像人类一样进行复杂的空间思考和空间推理。

大家还记得Mira Murati吗?那个曾经主导ChatGPT开发的“AI女王”,OpenAI的前CTO,2024年突然离职后,让整个科技圈炸锅!短短几个月,融资20亿美元,估值飙到120亿美元,现在更传出新一轮融资目标直冲500亿美元!这速度,这手笔,简直是AI界的“神话”!而最近的重磅炸弹来了:他们的首款产品Tinker正式全面开放!不再需要等待名单,人人可用!