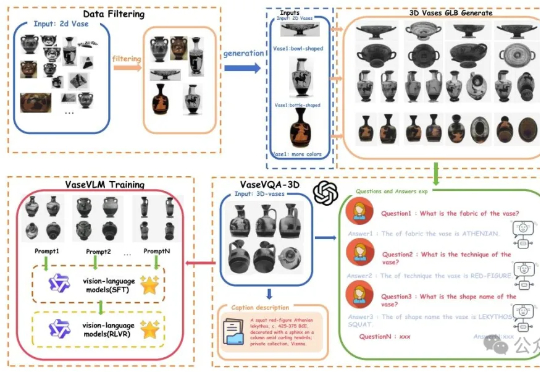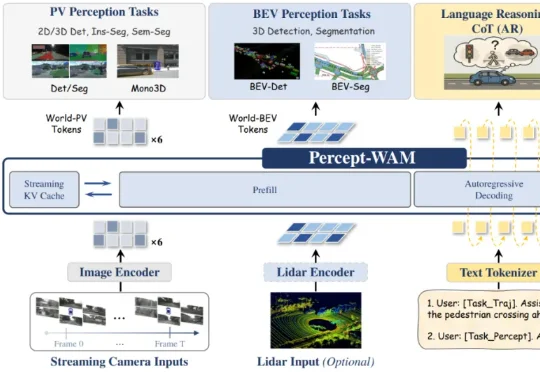
Percept-WAM:真正「看懂世界」的自动驾驶大脑,感知到行动的一体化模型
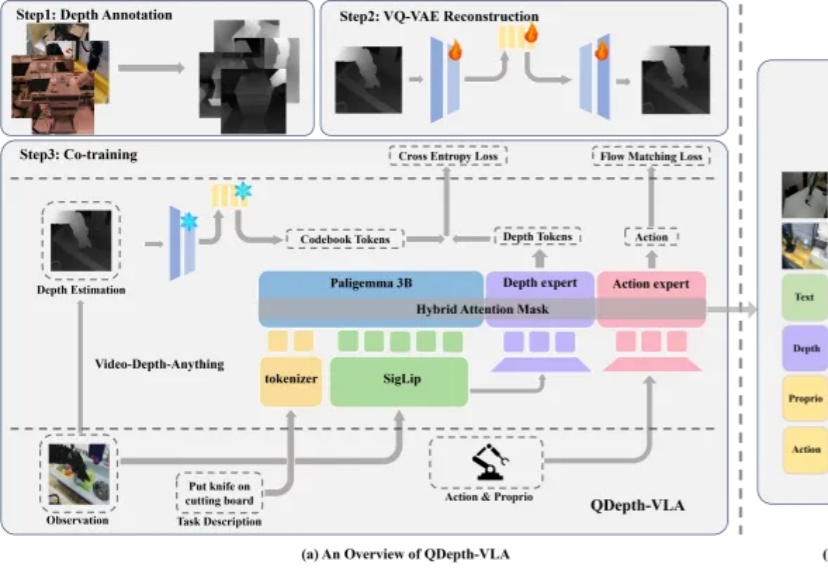
Percept-WAM:真正「看懂世界」的自动驾驶大脑,感知到行动的一体化模型近日,来自引望智能与复旦大学的研究团队联合提出了一个面向自动驾驶的新一代大模型 ——Percept-WAM(Perception-Enhanced World–Awareness–Action Model)。该模型旨在在一个统一的大模型中,将「看见世界(Perception)」「理解世界(World–Awareness)」和「驱动车辆行动(Action)」真正打通,形成一条从感知到决策的完整链路。
来自主题: AI技术研报
6944 点击 2025-12-10 14:33