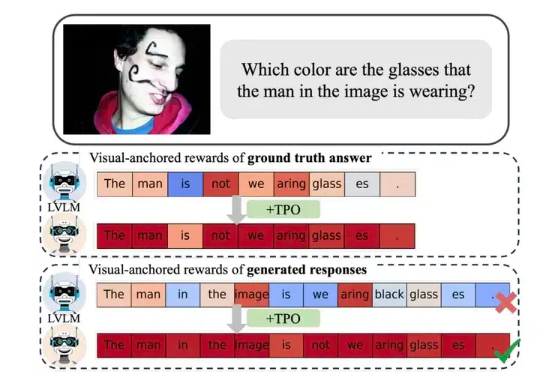
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
来自主题: AI技术研报
8144 点击 2025-01-19 14:51
 搜索
搜索
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
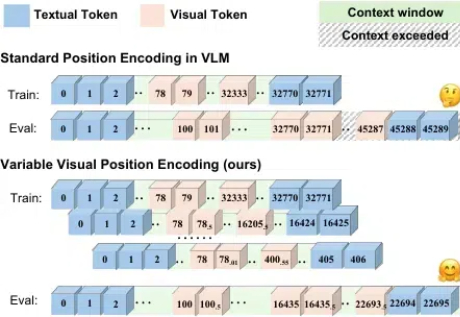
随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
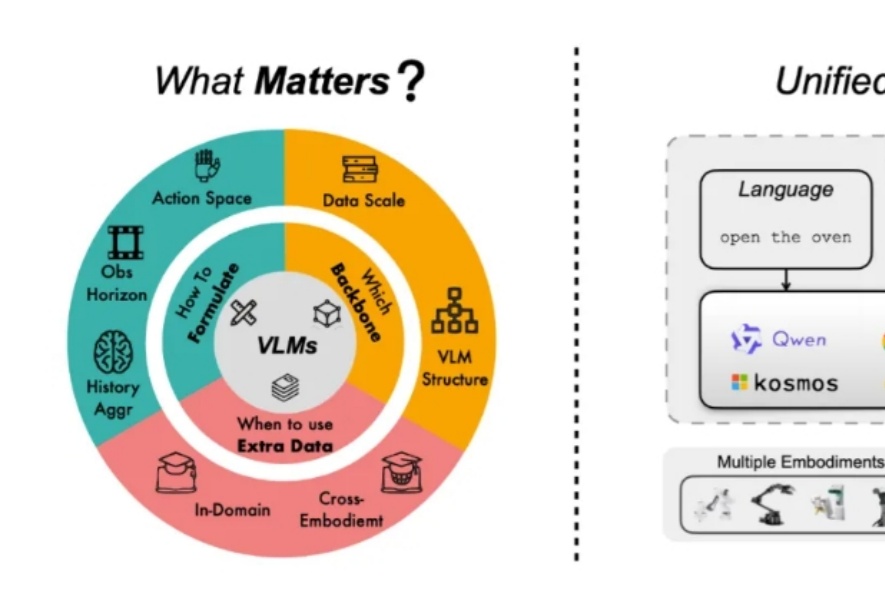
近年来,视觉语言基础模型(Vision Language Models, VLMs)大放异彩,在多模态理解和推理上展现出了超强能力。现在,更加酷炫的视觉语言动作模型(Vision-Language-Action Models, VLAs)来了!通过为 VLMs 加上动作预测模块,VLAs 不仅能 “看” 懂和 “说” 清,还能 “动” 起来,为机器人领域开启了新玩法!

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。
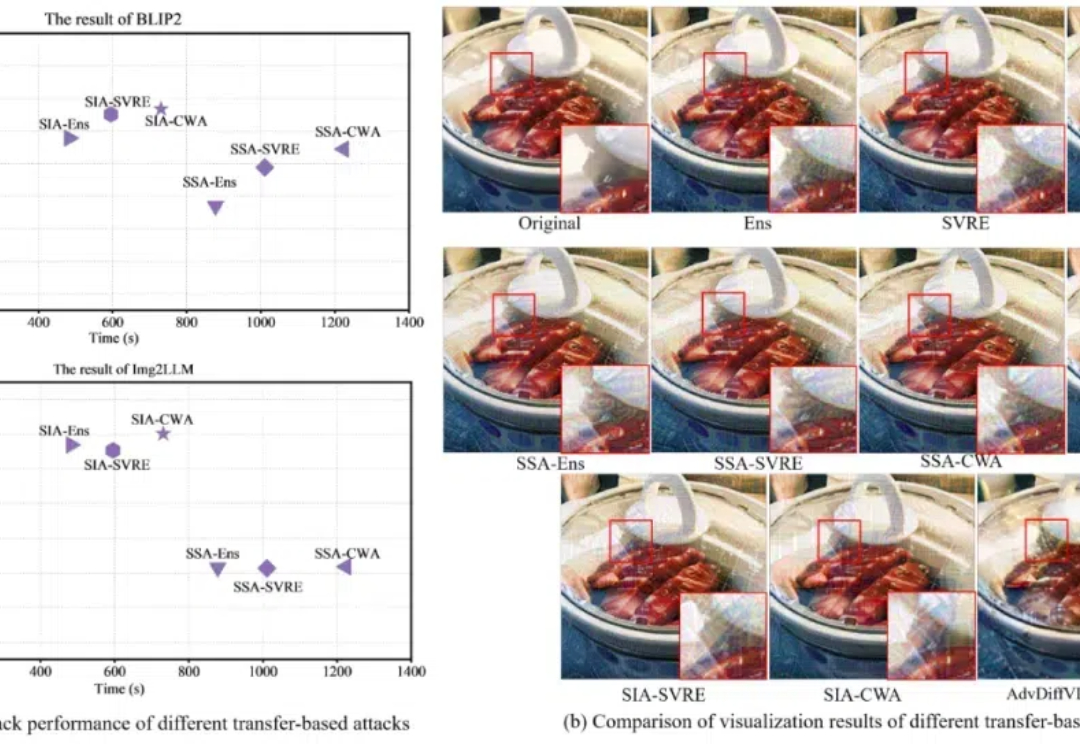
对抗攻击,特别是基于迁移的有目标攻击,可以用于评估大型视觉语言模型(VLMs)的对抗鲁棒性,从而在部署前更全面地检查潜在的安全漏洞。然而,现有的基于迁移的对抗攻击由于需要大量迭代和复杂的方法结构,导致成本较高

随着基础模型(如VLMs,例如Minimax、Qwen-V)和尖端图像生成技术(如Flux 1.1)的快速发展,我们正进入一个创造性可能性的新纪元。结合像T5这样的模型以增强对潜在空间中文本提示的理解,这些工具使得生产广告级别的关键视觉(KVs)成为可能,且具有显著的真实感。

一个5月份完成训练的大模型,无法对《黑神话·悟空》游戏内容相关问题给出准确回答。
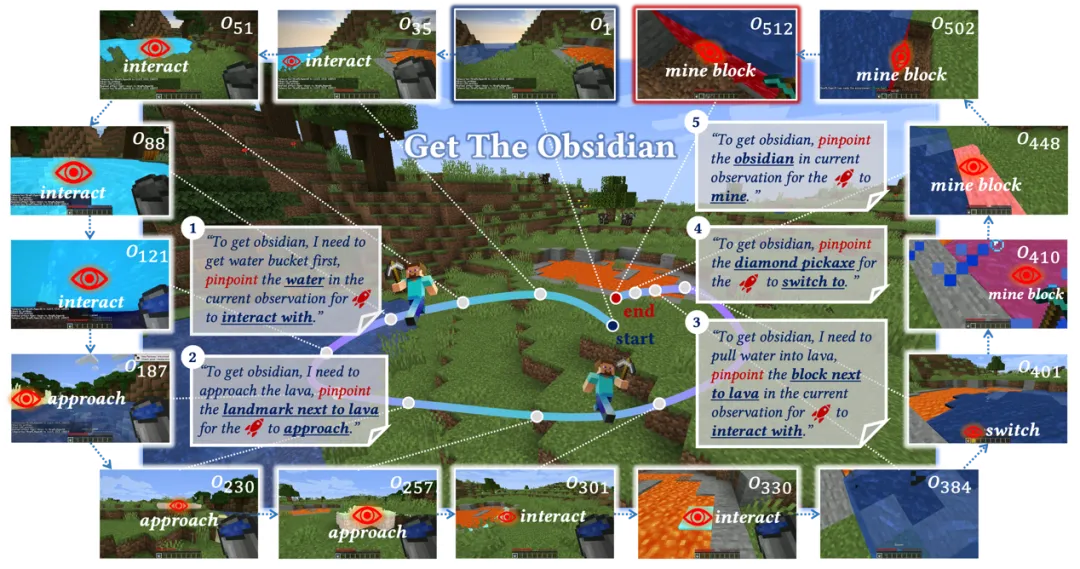
在游戏和机器人研究领域,让智能体在开放世界环境中实现有效的交互,一直是令人兴奋却困难重重的挑战。

本文提出了一种名为MedUnA的方法,旨在解决医疗图像分类中因缺乏标注数据而导致的监督学习挑战。MedUnA利用视觉-语言模型(VLMs)中的视觉与文本对齐特性,通过无监督学习来适应医疗图像分类任务。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。