6款通用大模型在保险行业的能力PK测评报告 |ZionAI实验室大模型测评
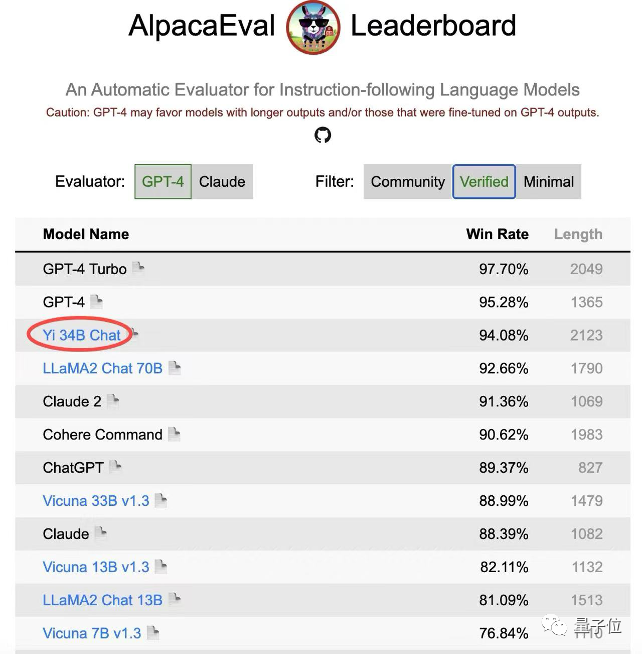
6款通用大模型在保险行业的能力PK测评报告 |ZionAI实验室大模型测评参照SuperCLUE(中文通用大模型综合性测评基准)框架专门定制了1000道题目集,一一测试了ChatGPT4、 智谱chatGLM-4、Baichuan2-Turbo、百度ERNIE-Bot 4.0、Yi-34B-chat、llama 2等模型在保险业务上的表现。
来自主题: AI资讯
10844 点击 2024-03-07 10:34