
Nile创始人戴灏庄,帮品牌在Agent世界开店
Nile创始人戴灏庄,帮品牌在Agent世界开店Nile(https://nile.shop),这家15人的创业公司,想要帮助解决这个问题。他们要为品牌构建一个“AI原生后端”,让商家拥有属于自己的、能面向任何Agent做分发的“品牌智能体”。
来自主题: AI资讯
8906 点击 2026-07-17 14:57
 搜索
搜索
Nile(https://nile.shop),这家15人的创业公司,想要帮助解决这个问题。他们要为品牌构建一个“AI原生后端”,让商家拥有属于自己的、能面向任何Agent做分发的“品牌智能体”。

最近,我和一位来北京融资,做出海营销 Agent 的创业者聊天。

昨天那篇文章,我说了一下我现在用Agent的日常。
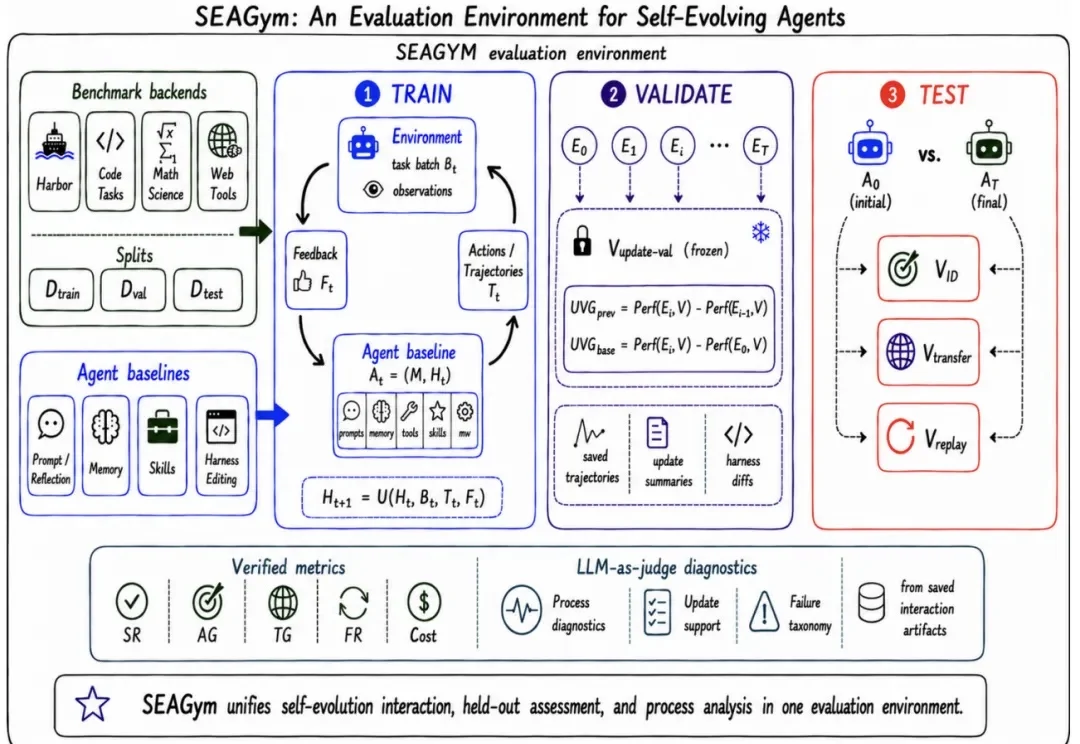
近日,翁荔发布长文 《Harness Engineering for Self-Improvement》,系统梳理了 harness engineering 在 AI 自我改进中的作用。

Raft是一个很神奇的AI产品。当它还叫Slock的时候,我认为这主要是一个投资人自嗨产物。除了极少数自己充了Claude、Codex会员,同时本地电脑还有Opencode、Pi等一系列Agent的极致变态电子佬用户,没人需要一个AI群聊。
作为国内深耕消费赛道落地最快的 Agent 原生团队之一,数宗 Digit Master 凭借自研 DM Agent OS,已携手雅诗兰黛、阳狮、博报堂、7-Eleven等全球头部快消品牌、广告集团完成规模化商业落地。团队在真实业务场景中,精准切中传统行业长期存在的核心痛点
据三位知情人士透露,开源 Hermes Agent 背后的初创公司 Nous Research 正在敲定由 Robot Ventures 领投的新一轮融资,USV 及其他知名投资者也有重要参与,估值为 15 亿美元。知情人士称,该公司至少筹集 7500 万美元,并吸引了大量投资者的高度关注。

当 Agent 走向生产,云与数据库需要被一起重新考虑。

最近一段时间,越来越多人开始讨论一个词:Loop。刚开始看到这个说法,我也觉得有点抽象。Agent 本身不就会反复思考、调用工具、修改代码吗?为什么还要专门设计一个 Loop?周末两天看完 Claude Code 团队写的一篇文章,我才发现,这件事其实没有那么玄乎。

国产Coding模型杀疯了!实测1分20秒闭环真实Bug,1395行代码徒手捏出《我的世界》,长程工程能力直逼Opus 4.8,不用再当AI保姆了。这款装入CC的AI,就是快手发布的KAT-Coder-Pro V2.5,一款旗舰级的Agentic Coding模型。