
超越OpenAI,中国00后团队攻破「记忆」难题!打造下一个AI互联网时刻
超越OpenAI,中国00后团队攻破「记忆」难题!打造下一个AI互联网时刻80年前,阿根廷作家博尔赫斯写过一个寓言,叫《博闻强记的富内斯》。博尔赫斯笔下的富内斯,拥有过目不忘、堪称完美的记忆,却无法思考,因为思考依赖于遗忘和抽象。
来自主题: AI技术研报
9285 点击 2026-07-15 14:34
 搜索
搜索
80年前,阿根廷作家博尔赫斯写过一个寓言,叫《博闻强记的富内斯》。博尔赫斯笔下的富内斯,拥有过目不忘、堪称完美的记忆,却无法思考,因为思考依赖于遗忘和抽象。

施耐德电气(Schneider Electric SE)同意以 31 亿美元全现金交易收购 Cognite,以扩大其工业数据与 AI 软件业务。这也是欧洲工厂加速现代化浪潮中的一项重要布局。这家法国能源管理设备制造商计划将 Cognite 与旗下工业软件业务 Aveva 进行整合。
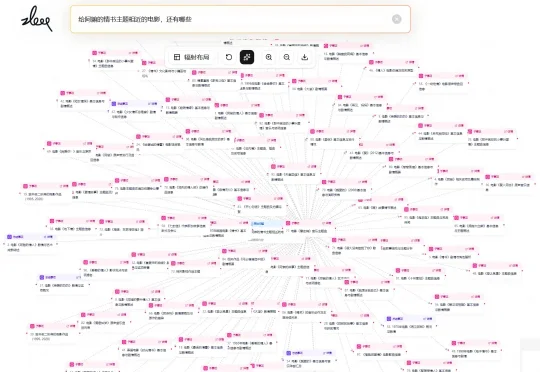
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。
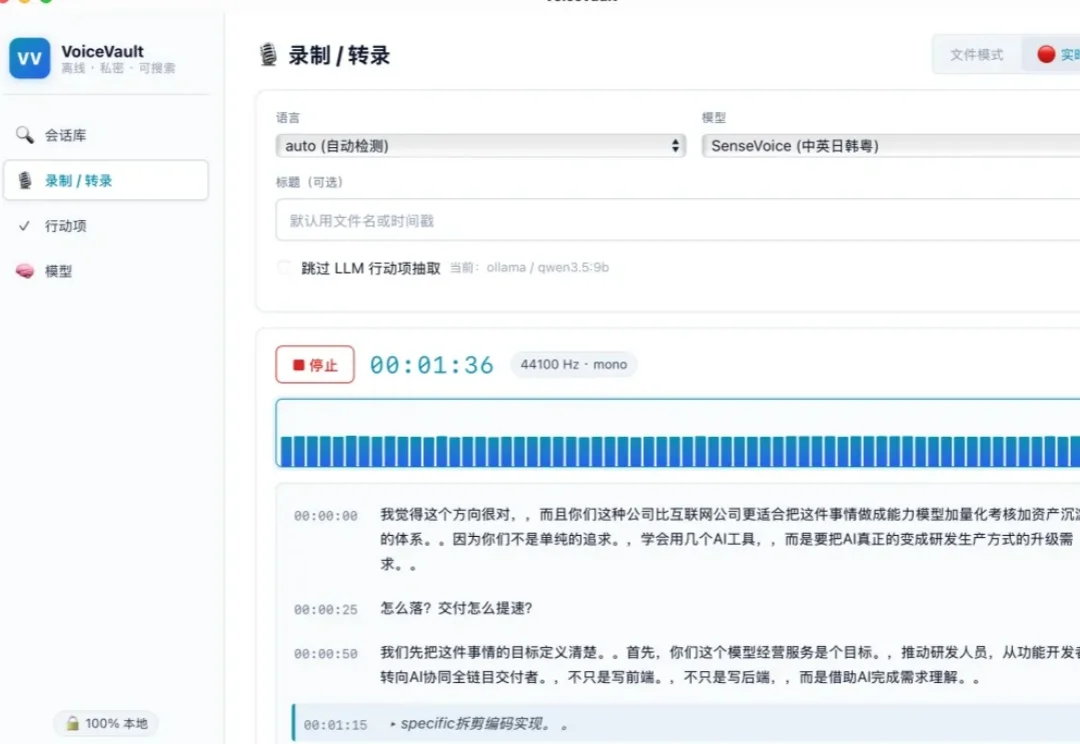
把 VoiceVault 的转录引擎从 Whisper 迁移到 FunASR(sherpa-onnx),中文识别速度提升 3x,不再需要 500MB 的模型文件。但"切个后端"这件听起来很简单的事,让我在 GitHub Release 的 404、Tauri 白屏、trait object 生命周期和 CSP 策略里翻滚了一整天。

刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。

全球首个AI游戏社区Aippy近日完成数千万美元首轮融资,由歌未资本(Glowill Capital)投资,投后估值达到2.5亿美元(约合17亿元人民币)。该产品由港股上市公司赤子城科技(以下简称“赤子城”)孵化,掌舵人Evan(叶椿建)是赤子城联合创始人,

光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。
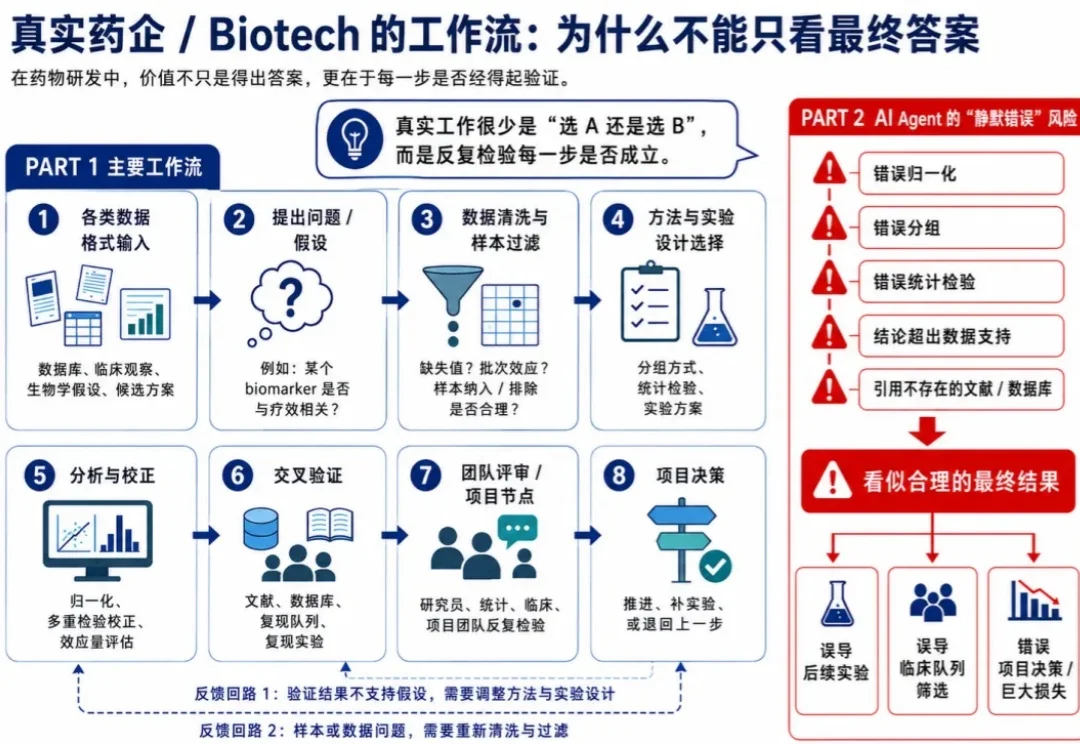
xbench,就是红杉自己弄的那个中立评测lab,刚刚又整了个新活:让 AI 做药企的数据分析,跟人类实习生比个高低,然后遥遥领先的赢了
AI 圈现在招人,连岗位名字都透着点不寻常。

Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。