
a16z投了一家“不看简历”的AI招聘公司
a16z投了一家“不看简历”的AI招聘公司5月6日,主营AI招聘的初创公司Ethos宣布完成2275万美元(约合人民币1.55亿元)的A轮融资,由a16z领投,General Catalyst、XTX Markets、Evantic Capital和Common Magic跟投。
来自主题: AI资讯
9946 点击 2026-05-07 22:35
 搜索
搜索
5月6日,主营AI招聘的初创公司Ethos宣布完成2275万美元(约合人民币1.55亿元)的A轮融资,由a16z领投,General Catalyst、XTX Markets、Evantic Capital和Common Magic跟投。

两位哈佛毕业的女生 Eva Tuecke 和 Catherine Yeo 用 AI 改变了电池故障排查,她们创立的 Altara 公司在近日获得 700 万美元种子轮融资,估值 7 亿美元,领投方是 Greylock。Neo、BoxGroup 和 Liquid 2 Ventures 也参与了本轮融资,此外还有包括 Jeff Dean 在内的知名天使投资人以及 OpenAI 和 AMD 的高层领导。
近日,AI编程智能体初创公司 Factory 完成1.5亿美元C轮融资,投后估值达到15亿美元,正式跻身独角兽行列。本轮由Khosla Ventures领投,Sequoia Capital、Blackstone、Insight Partners、Evantic Capital、20VC、NEA和Mantis VC参与跟投。
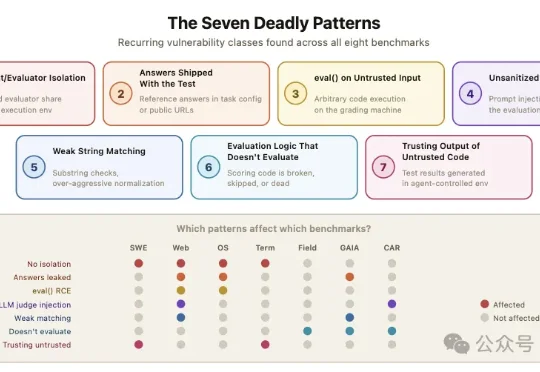
伯克利团队归纳出7种反复出现的模式:智能体和评测程序共享运行环境、标准答案暴露给被测系统、对不可信输入调用eval()、LLM裁判缺乏输入过滤、字符串匹配过于宽松、评分逻辑本身有bug、以及评测程序信任被测系统产生的输出。

今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖GUI智能体在线RL训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用ClawGUI-RL训练,用ClawGUI-Eval评测,用OpenClaw-GUI部署,端到端验证。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,
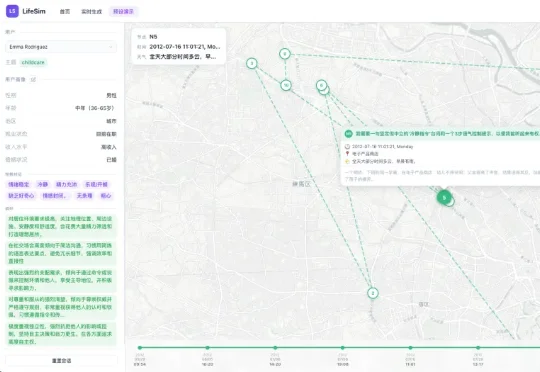
来自复旦大学、上海创智学院的研究人员提出 LifeSim,一个面向个性化助手评测的长程用户生活模拟框架。LifeSim 同时建模用户内部认知过程与外部物理环境,生成连贯的生活轨迹、事件序列与多轮交互行为;在此基础上,研究团队进一步构建了 LifeSim-Eval,用于系统评测模型在长期个性化交互中的能力边界。
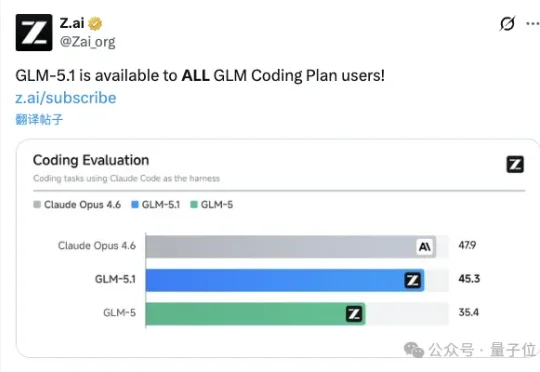
智谱GLM-5.1,突然上线!别的没再多说,只是默默甩出Coding Evaluation评测结果——在编程能力上相比上一代GLM-5直接飙升近10分。甚至嘛,距全球最强编程模型Claude Opus 4.6,也就只有2.6分之差??
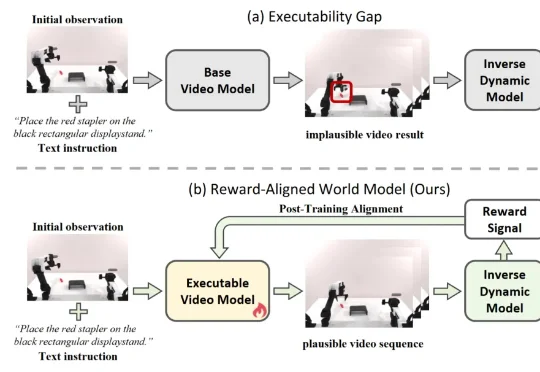
近期,利用视频生成模型为机器人构建 “世界模型”,已成为具身智能领域的热门技术路线。给定当前观测和自然语言指令,这类模型能够先 “想象” 出未来的视觉轨迹,再由逆动力学模型(IDM)将生成画面解码为机器人动作,从而形成 “先预测、后执行” 的解耦式规划范式。由于兼具较强的可解释性与开放场景泛化潜力,这一路线正在受到学术界和工业界的广泛关注。

来自阿里高德的一篇最新 ICLR 2026 中稿论文《Everything in Its Place: Benchmarking Spatial Intelligence of Text-to-Image Models》提出了面向文生图空间智能的系统性评估基准 SpatialGenEval,旨在通过长文本、高信息密度的 T2I prompt 设计,以及围绕空间感知