
GPT-4o图像生成架构被“破解”了?自回归主干+扩散解码器,还有4o图像生成全面测评基准
GPT-4o图像生成架构被“破解”了?自回归主干+扩散解码器,还有4o图像生成全面测评基准GPT-4o图像生成架构被“破解”了!
来自主题: AI技术研报
8545 点击 2025-04-09 17:37
 搜索
搜索
GPT-4o图像生成架构被“破解”了!
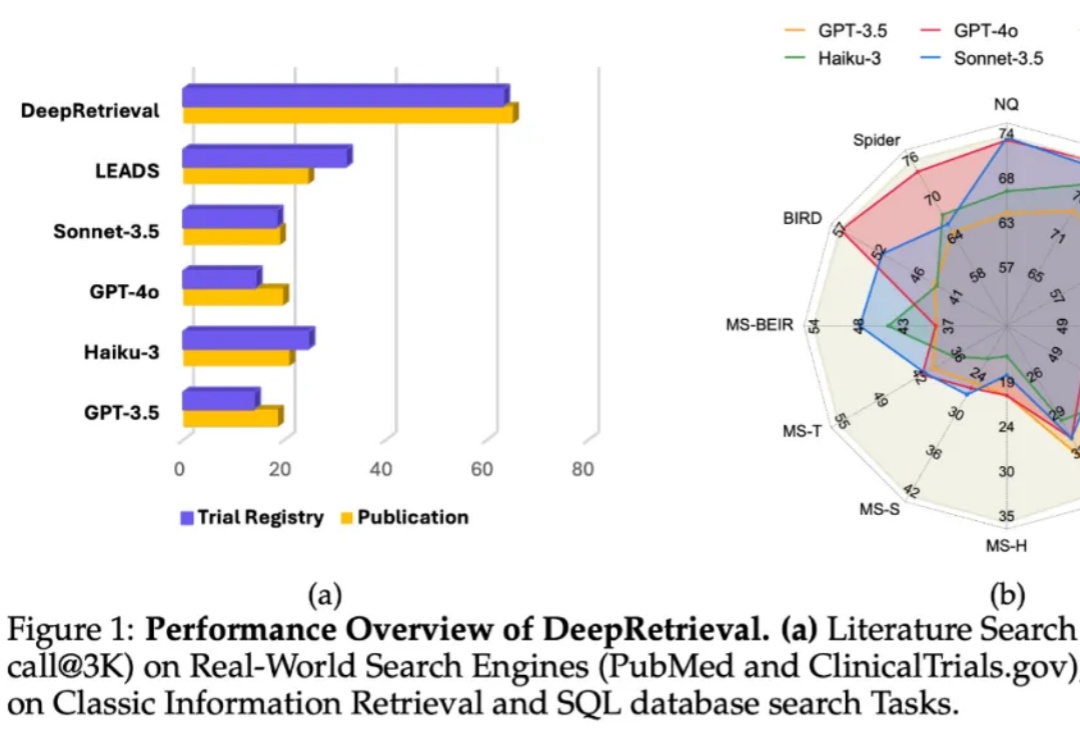
在信息检索系统中,搜索引擎的能力只是影响结果的一个方面,真正的瓶颈往往在于:用户的原始 query 本身不够好。
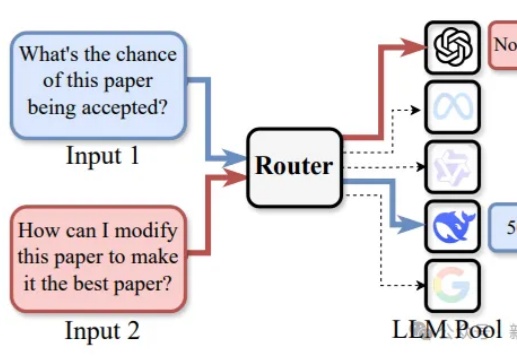
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。
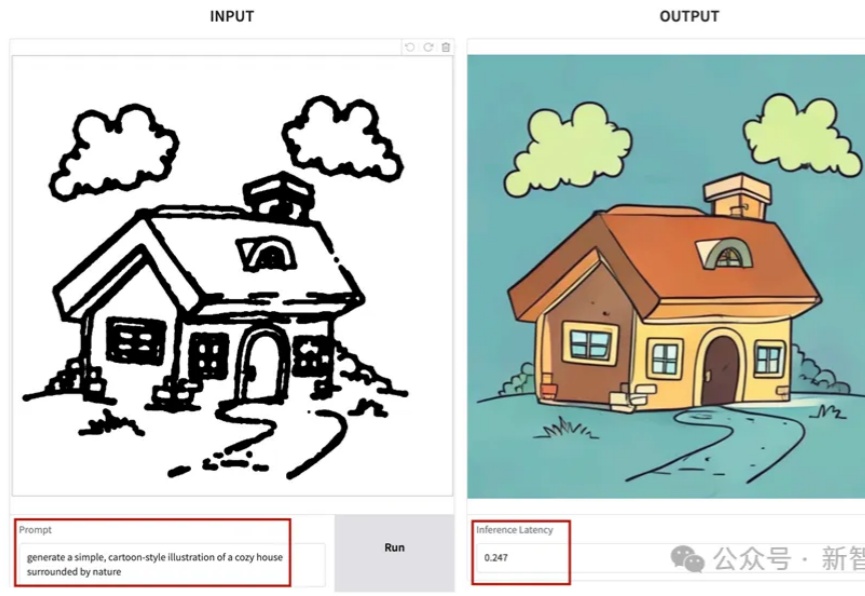
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。

事关路由LLM(Routing LLM),一项截至目前最全面的研究,来了——
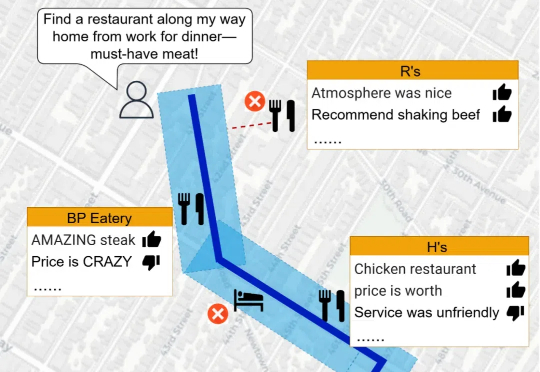
当涉及到空间推理任务时,LLMs 的表现却显得力不从心。空间推理不仅要求模型理解复杂的空间关系,还需要结合地理数据和语义信息,生成准确的回答。为了突破这一瓶颈,研究人员推出了 Spatial Retrieval-Augmented Generation (Spatial-RAG)—— 一个革命性的框架,旨在增强 LLMs 在空间推理任务中的能力。
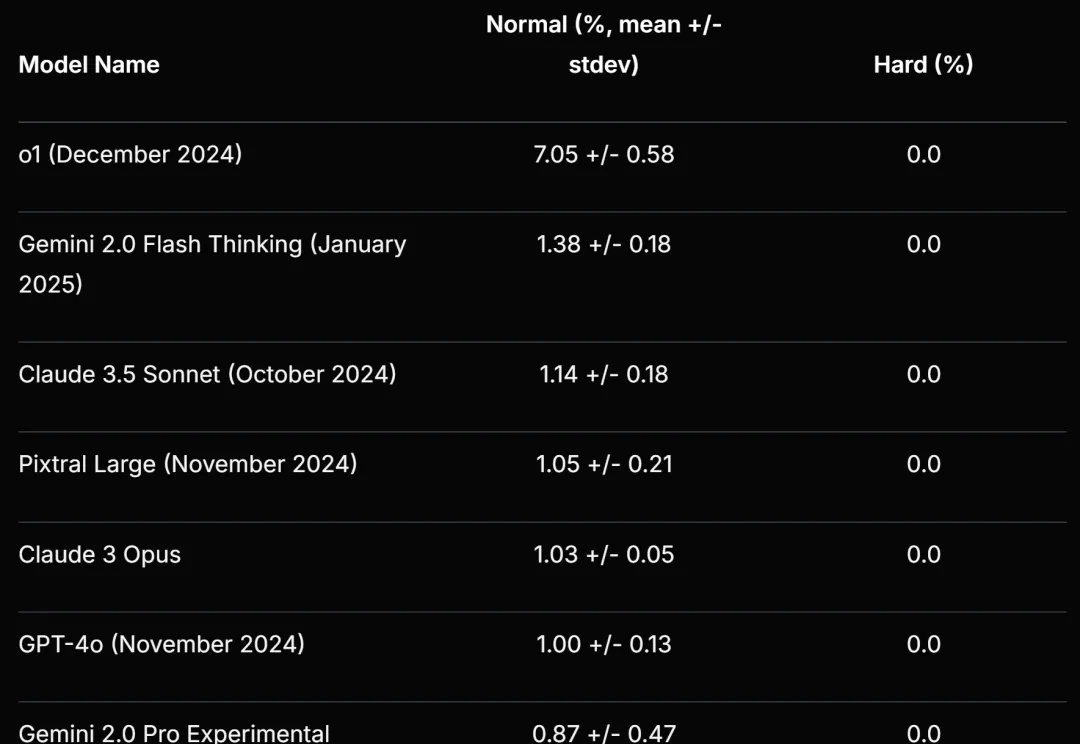
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
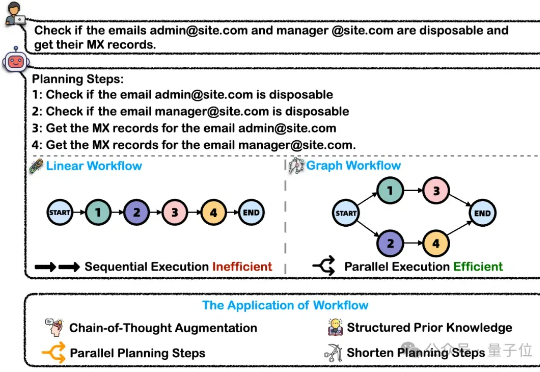
在处理这类复杂任务的过程中,大模型智能体将问题分解为可执行的工作流(Workflow)是关键的一步。然而,这一核心能力目前缺乏完善的评测基准。为解决上述问题,浙大通义联合发布WorfBench——一个涵盖多场景和复杂图结构工作流的统一基准,以及WorfEval——一套系统性评估协议,通过子序列和子图匹配算法精准量化大模型生成工作流的能力。

梁文锋带领着DeepSeek,还在继续搅动大模型行业。继用R1模型炸场之后,1月28日凌晨,除夕夜前一晚,DeepSeek又开源了其多模态模型Janus-Pro-7B,宣布在GenEval和DPG-Bench基准测试中击败了DALL-E 3(来自 OpenAI)和Stable Diffusion。

DeepSeek大爆出圈,现在连夜发布新模型——多模态Janus-Pro-7B,发布即开源。在GenEval和DPG-Bench基准测试中击败了DALL-E 3和Stable Diffusion。