
实测ChatGPT最新生图模型三大发现
实测ChatGPT最新生图模型三大发现AI第一次从包工头,变成了建筑设计师。
来自主题: AI产品测评
7751 点击 2026-04-24 10:09
 搜索
搜索
AI第一次从包工头,变成了建筑设计师。

一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。

“这是我过去四个月一直在研究的东西!”
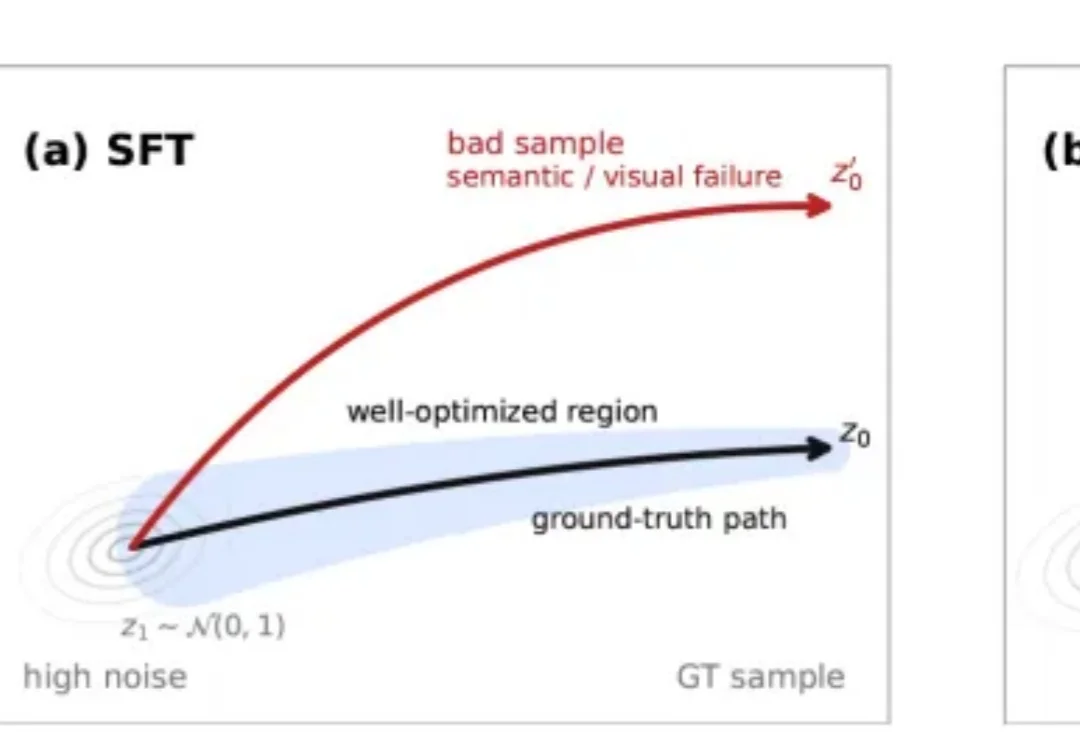
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。

GPT Image2全网刷屏,但效果究竟为什么这么好?
这两周国内外的 AI 圈又开始密集更新了。 上周 Anthropic 发了 Opus 4.7,这周 OpenAI 上了 GPT Image 2。国内这边 Kimi 发了 K2.6,腾讯据说也要发一个模

GPT Image 2的横空出世,直接暴打 Nano Banana 2,现在,真假难辨的照片和梗图已经满天飞了。超强的文字渲染和封神的设计能力,直接让它颠覆了众多行业,这一刻起,互联网的信任体系彻底洗牌!

今夜,ChatGPT Images 2.0震撼上线,成为首个「会思考」的图像AI。奥特曼直呼这是从GPT-3到GPT-5的飞跃。它不仅能精准听懂中文指令、渲染复杂UI,甚至能在米粒上刻字。
4 月的大模型战场,硝烟弥漫。

北京时间凌晨 3 点,直播准时开始,OpenAI 发布了 ChatGPT Images 2.0。据介绍,「ChatGPT Images 2.0 是下一步进化:一个最先进的模型,能够处理复杂的视觉任务,并生成精确、可直接使用的视觉内容。」