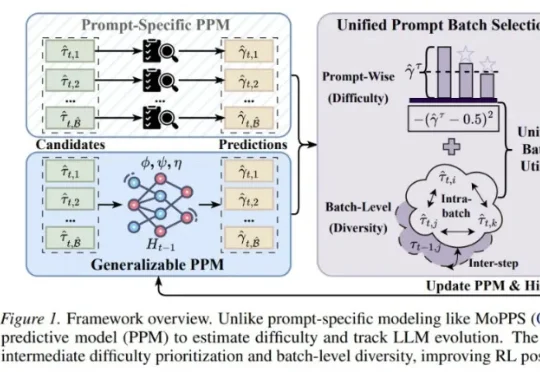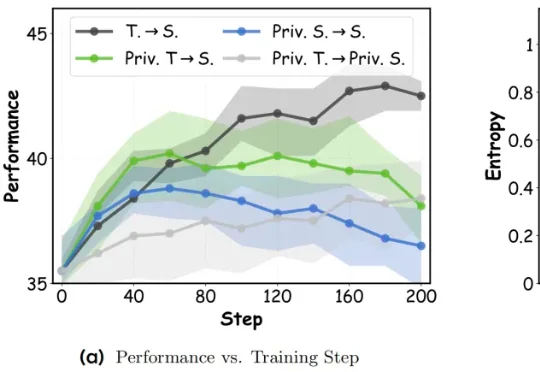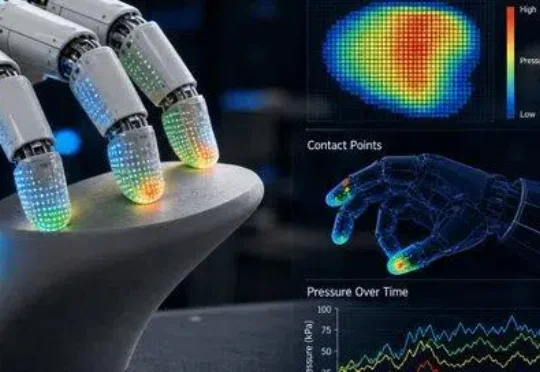
98年哈工大教授带队,破晓智能要把触觉写进机器人基础模型
98年哈工大教授带队,破晓智能要把触觉写进机器人基础模型瞄准这类 “看起来做对了,物理上却没完成” 的失败。破晓智能(PHANES AI)创始人、哈工大(深圳)长聘教授杨朔及其团队发布了最新论文 TouchWorld: A Predictive and Reactive Tactile Foundation Model for Dexterous Manipulation。
来自主题: AI资讯
9445 点击 2026-07-12 16:37