AI编程有了独立工作台!GitHub Copilot App全量开放,模型、Issue、仓库、PR全都交给Agent
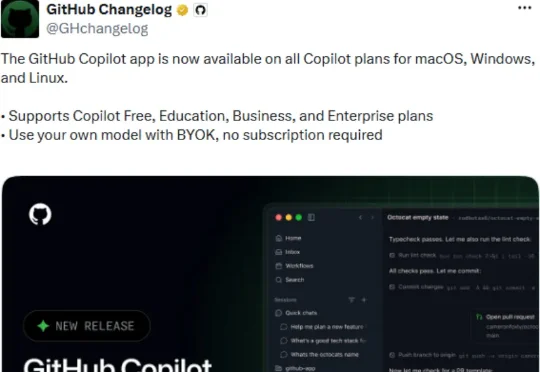
AI编程有了独立工作台!GitHub Copilot App全量开放,模型、Issue、仓库、PR全都交给AgentGitHub宣布,GitHub Copilot App正式向所有Copilot套餐开放。这意味着,Copilot Free、GitHub Education、Copilot Pro、Business、Enterprise用户,都可以在macOS、Windows和Linux上使用这个独立桌面应用。
来自主题: AI资讯
9044 点击 2026-07-08 17:24