
无需标注图像,VLM也能「自我进化」!RL自我进化框架VisPlay突破视觉推理难题
无需标注图像,VLM也能「自我进化」!RL自我进化框架VisPlay突破视觉推理难题在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。
来自主题: AI技术研报
10095 点击 2025-12-02 15:22
 搜索
搜索
在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

今天,The Information从投资者文件和知情人士处获悉,AI数据分析平台Databricks正在洽谈一轮规模高达50亿美元(约合人民币354亿元)的新融资,此轮融资中,Databricks的估值已经飙升至1340亿美元(约合人民币9481亿元)。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

最近看到一篇关于Claude Skills的质量非常高的文章, 标题:Claude Agent Skills: A First Principles Deep Dive 链接:https://leehanchung.github.io/blogs/2025/10/26/claude-skills-deep-dive/

邀请码炒到了 30 大元。最近 AI 圈出了一款有趣的产品:「OiiOii」,一款专注 AI 生成动画的 Agent。而它异常火爆,7210 个内测名额很快被抢光,闲鱼上免费邀请码被炒到 30 块,甚至据说内测用户里还出现了全网 2000w 的顶级创作者。

尽管 Apple Intelligence 在大陆国行机型上落地仍然杳无音讯,但这并不代表苹果没有在努力推进。 前两天,伴随着 iOS 26.1 版本的更新,Apple Intelligence 先一步提供了对于繁体中文的支持。

今天,谷歌生成式AI团队发布了Nano-Banana的首个官方教程——《The Complete Guide to Nano Banana Pro: 10 Tips for Professional Asset Production》。核心信息是如何用 Nano-Banana Pro 制作专业级的素材!
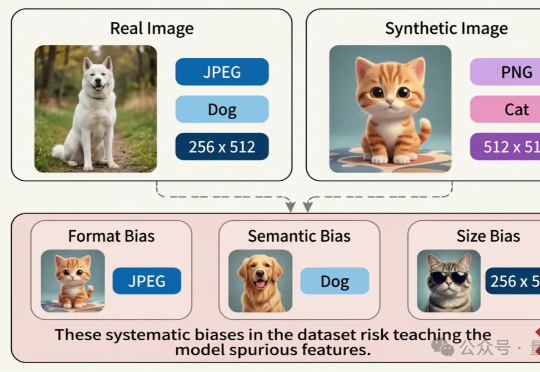
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

在本次 Z Potential 独家专访中,我们邀请到了 Striker Venture Partners 合伙人、Skild AI 与 Reflection AI 的早期投资人 Brian Zhan,深度解析他在 AI 时代如何快速投出明星级别的独角兽公司。

Digital Connexion 是由穆克什·安巴尼的依赖工业有限公司 、布鲁克菲尔德资产管理公司以及 Digital Realty Trust 共同组建的合资企业,已签署协议计划到 2030 年投资 110 亿美元在印度南部开发 数据 中心设施,标志着对科技领域增长最快赛道之一的最新投资。