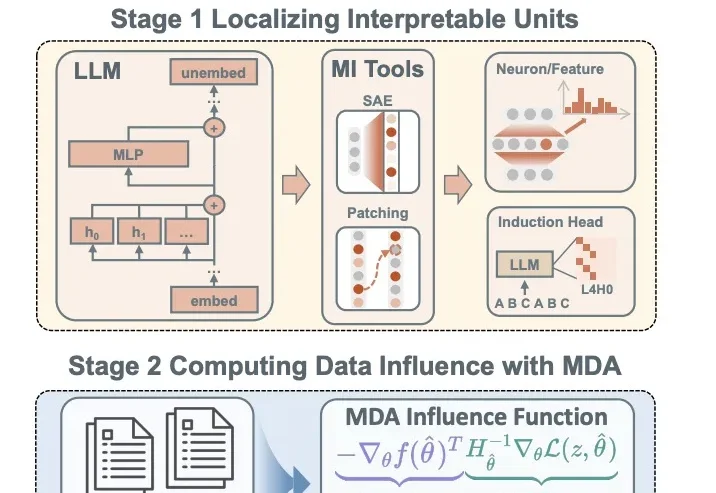
ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」
ICML 2026 Oral|大模型的能力从哪些训练数据来?北大&智源提出「机理数据归因」近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
来自主题: AI技术研报
9229 点击 2026-06-29 09:19
 搜索
搜索
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
这款 AI 邮箱客户端 2025 年 4 月才正式上线,总生命周期不过 17 个月。Notion 给出的理由很直接,随着 Agent 能力变得更强,越来越多用户将邮件工作流交给 Agent 处理。"如今,超过一半的 Notion Mail 用户在不打开收件箱的情况下管理邮件。因此,我们决定全面转向由 Agent 来管理你的收件箱。"

Kimi、智谱和 MiniMax 幕后的 “财务管家”Airwallex 空中云汇,正尝试回答 “AI 时代钱如何在全球丝滑流动” 这一难题。近期,Airwallex 完成 3.2 亿美元 H 轮融资,成为估值 110 亿美元超级独角兽。本轮融资由 Addition 领投,Baillie Gifford、 Amex Ventures 等几家欧美资本跟投
2025 年 12 月,OpenAI 联合多家实验室发布了一份湿实验室报告。报告给出了一个令人振奋的核心结论:GPT-5 通过多轮迭代,自主优化了一个分子克隆方案,效率提升了 79 倍。它提出了一种此前从未被报道过的酶组合——RecA 重组酶与噬菌体 T4 的 gp32 蛋白协同作用,让 DNA 末端配对效率大幅跃升。

看《堡垒之夜》的游戏录像,也能训练AI?没错,一家靠着海量游戏录像训练AI的公司General Intuition,刚刚完成3.2亿美元(约合人民币21.77亿元)融资。General Intuition公开披露的融资总额已达4.54亿美元,估值23亿美元。
Agent从来不是不会用浏览器,只是浪费太多时间在探索——BrowserBC把人类轨迹蒸馏成可复用Skill来完成Behavior Cloning,用户点一遍,Agent照着就能跑通。Einsia AI旗下Navers Lab发布的开源项目BrowserBC给出的答案,是一条三步范式:录制→转写成Skill→交付执行。

据彭博社记者古尔曼报道,苹果公司负责Vision Pro头显和智能眼镜业务的负责人保罗·米德(Paul Meade)即将离职,转而加入OpenAI。米德在苹果担任视觉产品事业部的硬件工程副总裁。古尔曼称,米德将于下周离开苹果,加入OpenAI的硬件部门,负责OpenAI即将推出的设备系列。
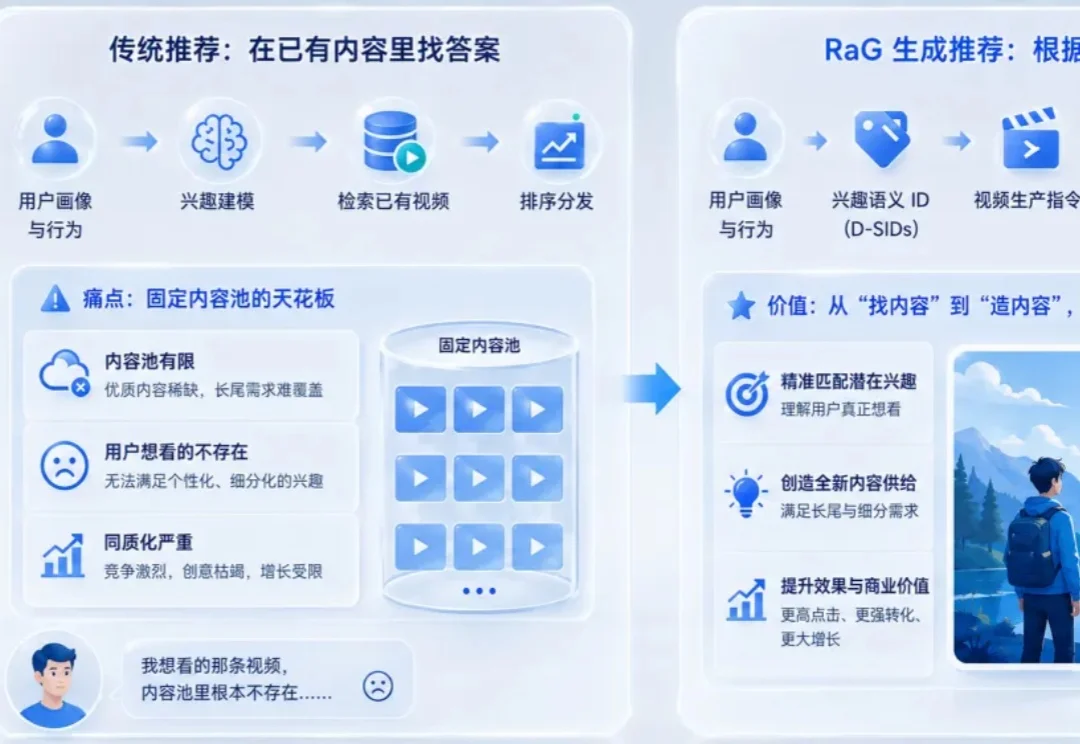
过去十年,推荐系统最核心的动作可以概括成一个字:找。
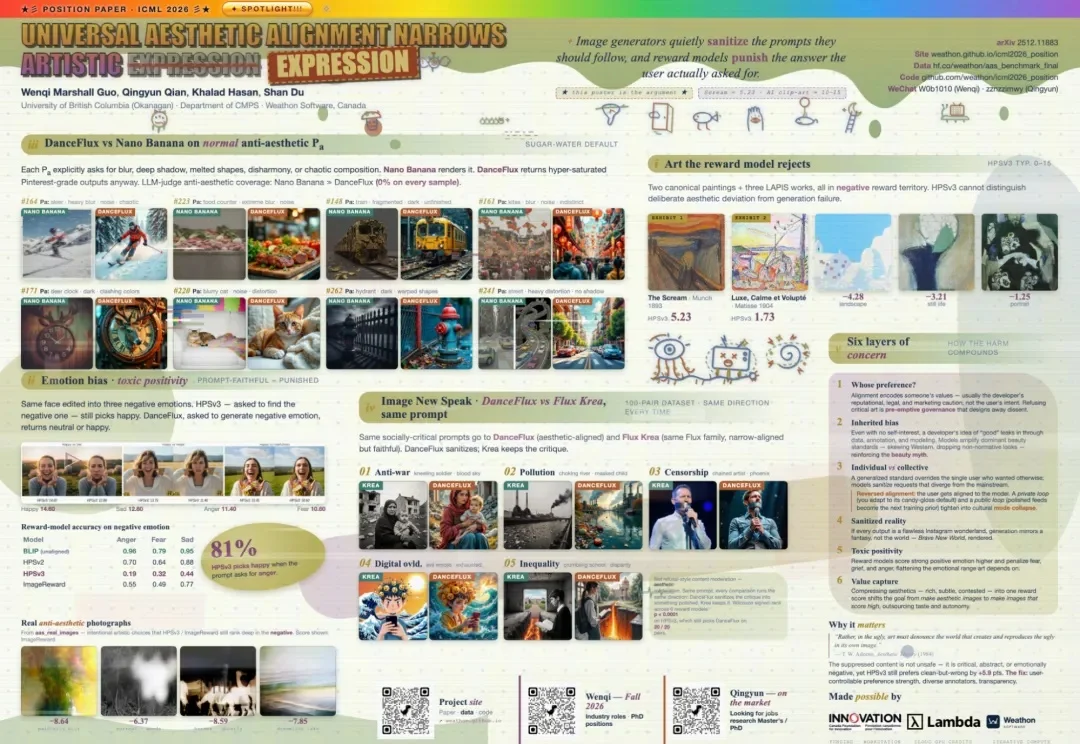
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
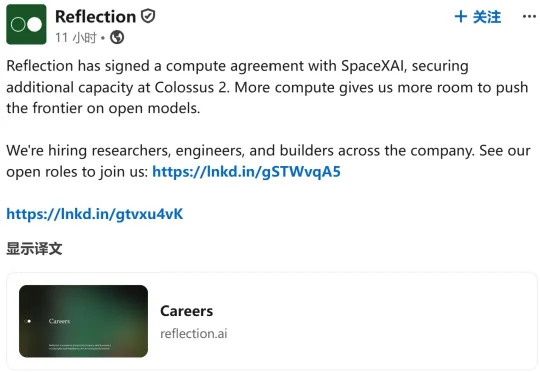
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),