
超越Claude 3.5和o1!8B模型靠「分层投票+测试时训练」逆袭
超越Claude 3.5和o1!8B模型靠「分层投票+测试时训练」逆袭小时候完成月考测试后,老师会通过讲解考试卷中吃错题让同学们在未来取得好成绩。
来自主题: AI技术研报
9796 点击 2025-07-23 10:20
 搜索
搜索
小时候完成月考测试后,老师会通过讲解考试卷中吃错题让同学们在未来取得好成绩。

又一位离职OpenAI的核心研究员发声! 刚刚被曝加入Meta的Hyung Won Chung,分享了他对AI未来的深刻思考:人工智能正在成为有史以来最强大的杠杆机制。

这次是真真真挖到OpenAI大动脉了。 Jason Wei,思维链的提出者、o1系列模型的关键人物,被曝也被扎克伯格请走,即将入职Meta。

大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。

从撒谎到勒索,再到暗中自我复制,AI 的「危险进化」已不仅仅是科幻桥段,而是实验室里的可复现现象。
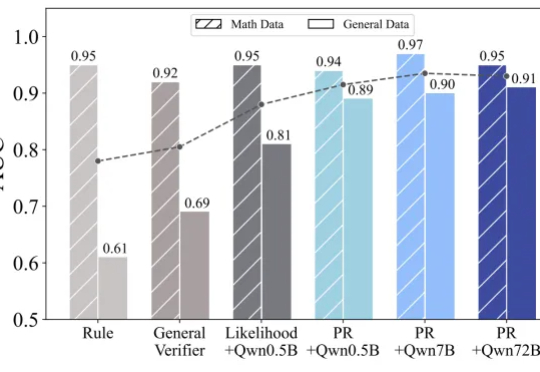
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
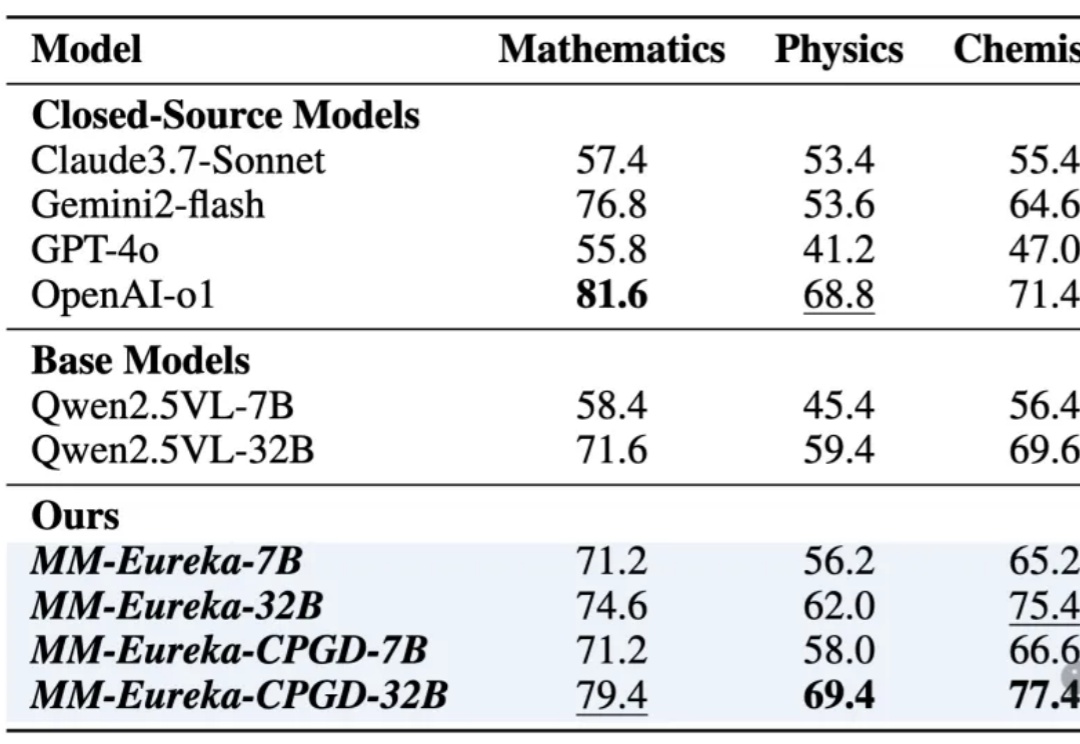
只训练数学,却在物理化学生物战胜o1!强化学习提升模型推理能力再添例证。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。
强化学习·RL范式尝试为LLMs应用于广泛的Agentic AI甚至构建AGI打开了一扇“深度推理”的大门,而RL是否是唯一且work的一扇门,先按下不表(不作为今天跟大家唠的重点),至少目前看来,随着o1/o3/r1/qwq..等一众语言推理模型的快速发展,正推动着LLMs和Agentic AI在不同领域的价值与作用,
最强推理模型一夜易主!深夜,o3-pro毫无预警上线,刷爆数学、编程、科学基准,强势碾压o1-pro和o3。更惊艳的是,o3价格直接暴降80%,叫板Gemini 2.5 Pro。