
有效的 Context 工程(精读、万字梳理)|见知录 004
有效的 Context 工程(精读、万字梳理)|见知录 004近日刚好得了空闲,在研读 Anthropic 官方技术博客和一些相关论文,主题是「Agent 与 Context 工程」。2025 年 6 月以来,原名为「Prompt Engineering」的提示词工程,在 AI Agent 概念日趋火热的应用潮中,
来自主题: AI技术研报
9395 点击 2025-10-21 10:21
 搜索
搜索
近日刚好得了空闲,在研读 Anthropic 官方技术博客和一些相关论文,主题是「Agent 与 Context 工程」。2025 年 6 月以来,原名为「Prompt Engineering」的提示词工程,在 AI Agent 概念日趋火热的应用潮中,
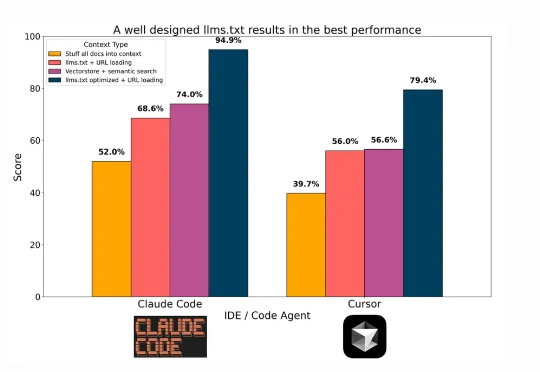
在技术飞速更新迭代的今天,每隔一段时间就会出现「XX 已死」的论调。「搜索已死」、「Prompt 已死」的余音未散,如今矛头又直指 RAG。
那边OpenAI的Sora2还没全面开放,这边国内团队已经上线了自己的“特色打法”。 清华特奖选手创办的Sand.ai,上线了音画同步视频模型GAGA-1。
![苹果盯上Prompt AI, 不是买产品,是要伯克利团队的[视觉大脑]](https://www.aitntnews.com/pictures/2025/10/15/ca7bf835-a97f-11f0-88f9-fa163e47d677.jpg)
根据外媒 CNBC 消息,苹果公司正和计算机视觉领域的初创企业 Prompt AI,推进收购事宜的 “最后阶段谈判”。

写给正在落地 AI 产品的工程师。一些代码直接可改造复用;另一些,是我踩坑后的经验之谈。
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
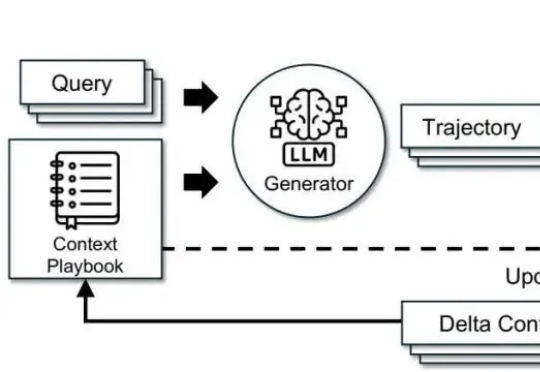
调模型不如“管上下文”。这篇文章基于 ACE(Agentic Context Engineering),把系统提示、运行记忆和证据做成可演化的 playbook,用“生成—反思—策展”三角色加差分更新,规避简化偏置与上下文塌缩。在 AppWorld 与金融基准上,ACE 相较强基线平均提升约 +10.6% 与 +8.6%,适配时延降至约 1/6(-86.9%),且在无标注监督场景依然有效。
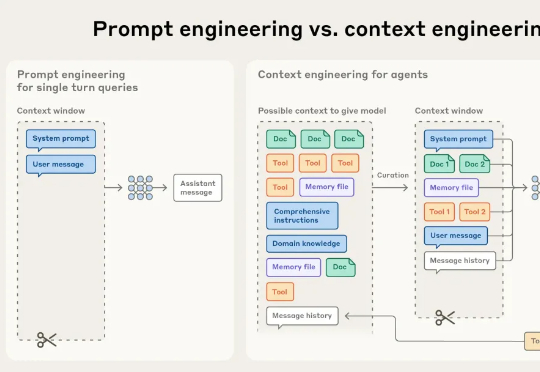
Hi,返工早上好。 我是洛小山,和你聊聊 AI 行业思考。 AI Agent 应用的竞争逻辑,正在发生根本性变化。 当许多团队还在死磕提示词优化(PE 工程)时,一些优秀团队开始重心转向了上下文工程

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。