
上下文就是一切!行业热议话题:提示工程是否应该改名
上下文就是一切!行业热议话题:提示工程是否应该改名这几天 AI 圈子有个非常有必要也非常热的讨论就是提示工程是不是应该被称为“上下文工程”更加适合。
来自主题: AI技术研报
7748 点击 2025-06-28 16:54
 搜索
搜索
这几天 AI 圈子有个非常有必要也非常热的讨论就是提示工程是不是应该被称为“上下文工程”更加适合。
![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)
前段时间,沉寂了很久的Flux官方团队Black Forest Labs发布了新模型:FLUX.1 Kontext,这是一套支持生成与编辑图像的流匹配(flow matching)模型。FLUX.1 Kontext不仅支持文生图,还实现了上下文图像生成功能,可以同时使用文本和图像作为提示词,并能无缝提取修改视觉元素,生成全新且协调一致的画面。

开源且免费!谷歌对编程Agent出手了。
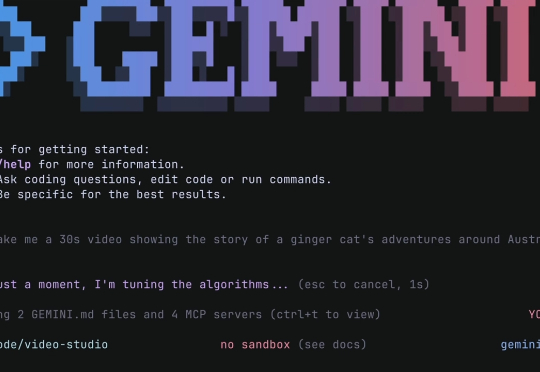
刚刚谷歌推出了 Gemini CLI,一个开源的 AI Agent,把 Gemini 的能力直接带到你的终端里。可以把它看作是谷歌版的 Claude Code。最香的是,这玩意儿开源、免费用,背后是带百万上下文的最强 Gemini 模型。
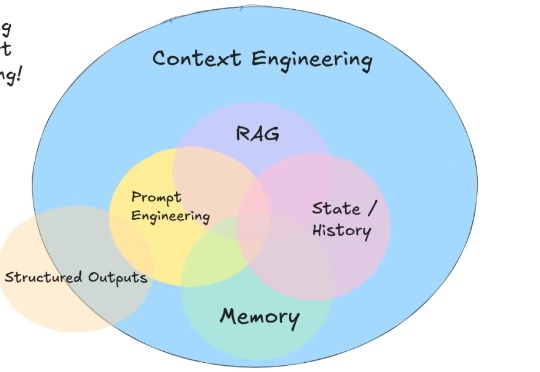
AI 时代,你可能听说过提示词工程、RAG、记忆等术语。但是很少有人提及上下文工程(context engineering)。
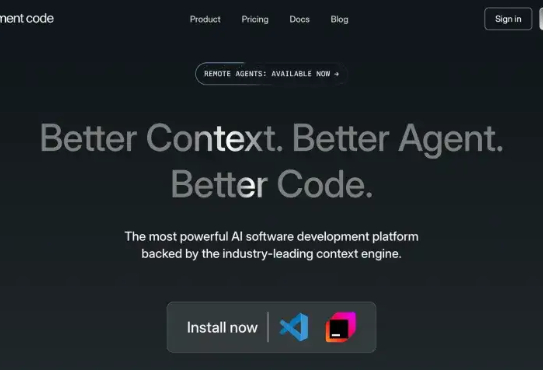
大家好,我是袋鼠帝 最近我发现好几个AI交流群炸锅了 起因是一款AI编程工具,大家聊得热火朝天。这款AI编程工具叫:Augment Code,它的slogen是更好的上下文、更好的Agent、更好的代码
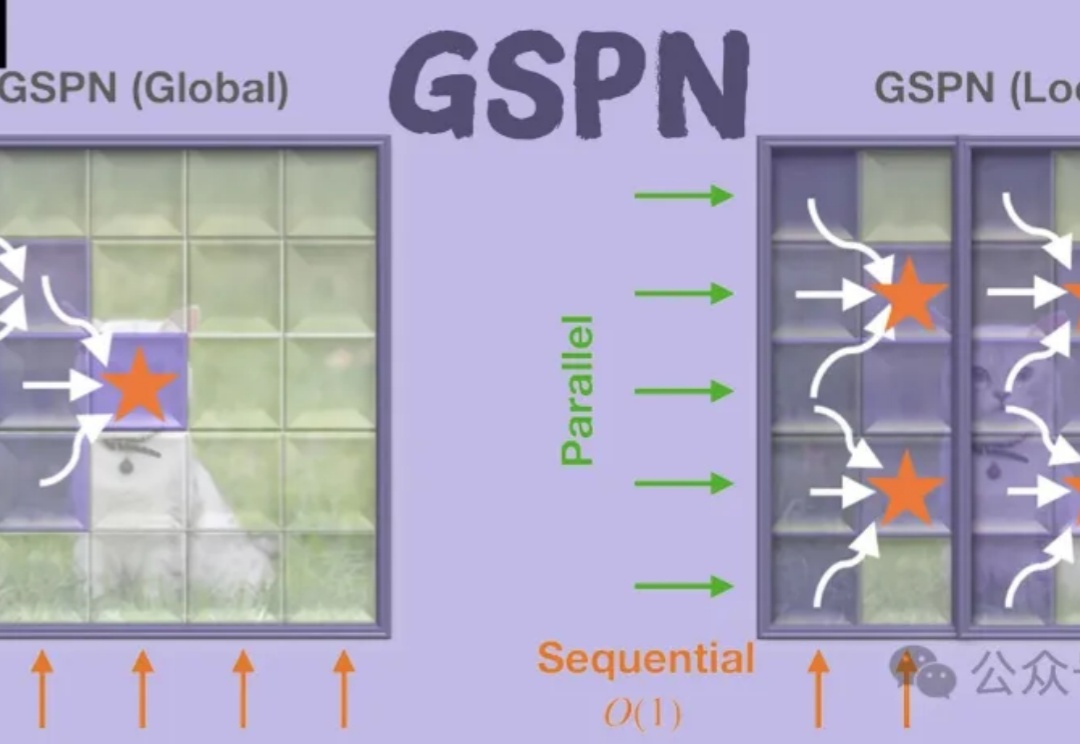
GSPN是一种新型视觉注意力机制,通过线性扫描和稳定性-上下文条件,高效处理图像空间结构,显著降低计算复杂度。通过线性扫描方法建立像素间的密集连接,并利用稳定性-上下文条件确保稳定的长距离上下文传播,将计算复杂度显著降低至√N量级。
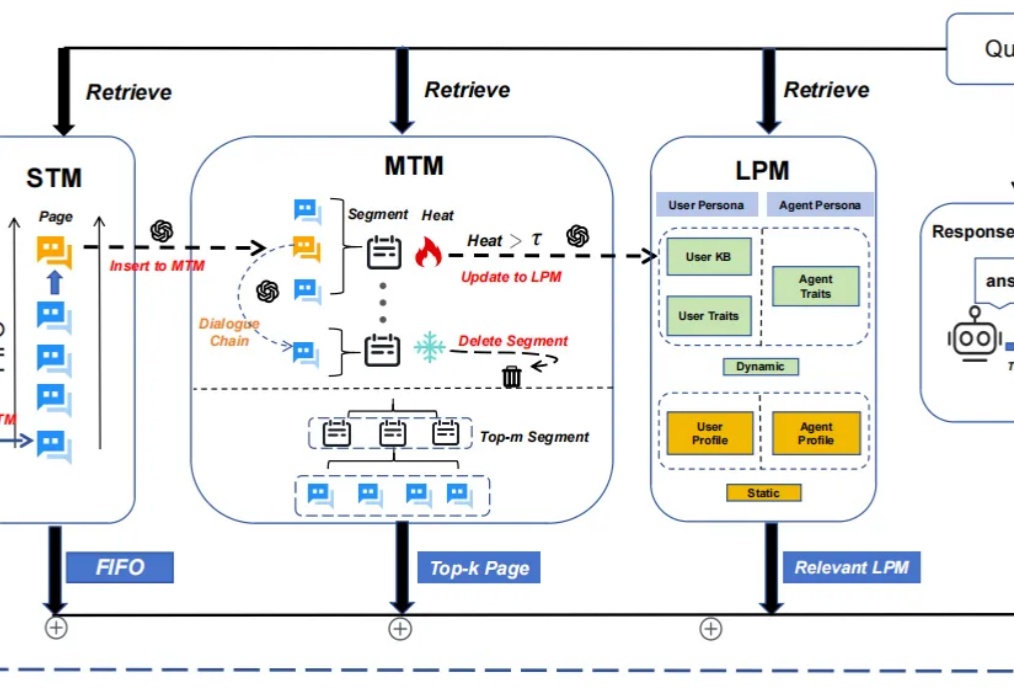
随着大模型应用场景的不断拓展,其在处理长期对话时逐渐暴露出的记忆局限性日益凸显,主要表现为固定长度上下文窗口导致的“健忘”问题。

未来AI路线图曝光!谷歌发明了Transformer,但在路线图中承认:现有注意力机制无法实现「无限上下文」,这意味着下一代AI架构,必须「从头重写」。Transformer的时代,真的要终结了吗?在未来,谷歌到底有何打算?

本文深入剖析 MiniCPM4 采用的稀疏注意力结构 InfLLM v2。作为新一代基于 Transformer 架构的语言模型,MiniCPM4 在处理长序列时展现出令人瞩目的效率提升。传统Transformer的稠密注意力机制在面对长上下文时面临着计算开销迅速上升的趋势,这在实际应用中造成了难以逾越的性能瓶颈。