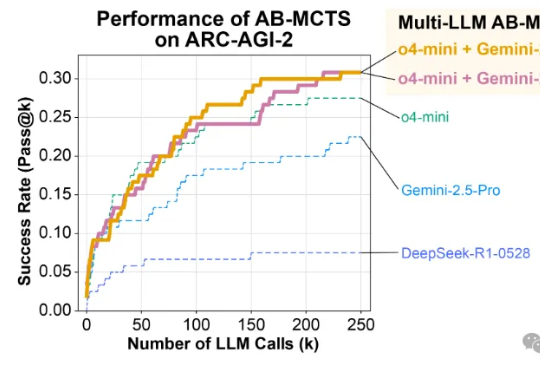
AI版三个臭皮匠!ChatGPT/Gemini/DeepSeek合体拿下AGI测试最高分
AI版三个臭皮匠!ChatGPT/Gemini/DeepSeek合体拿下AGI测试最高分ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……
来自主题: AI技术研报
9946 点击 2025-07-09 15:05
 搜索
搜索
ChatGPT的对话流畅性、Gemini的多模态能力、DeepSeek的长上下文分析……
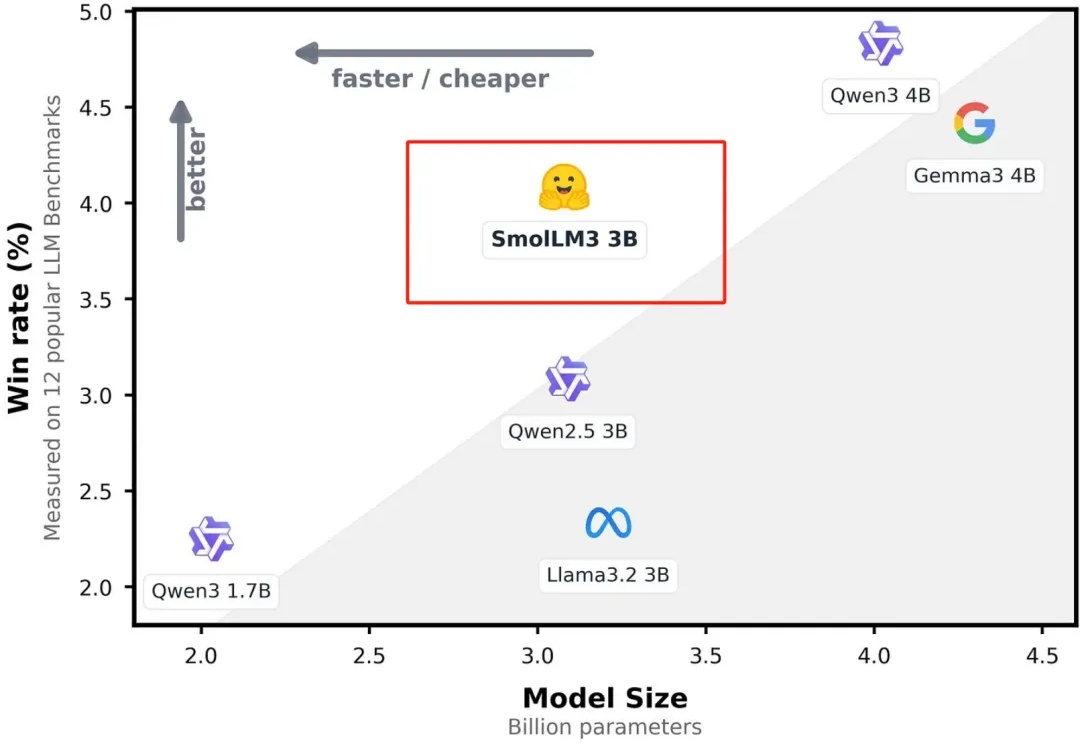
今天凌晨,全球著名大模型开放平台Hugging Face开源了,顶级小参数模型SmolLM3。

在多模态大语言模型(MLLMs)应用日益多元化的今天,对模型深度理解和分析人类意图的需求愈发迫切。尽管强化学习(RL)在增强大语言模型(LLMs)的推理能力方面已展现出巨大潜力,但将其有效应用于复杂的多模态数据和格式仍面临诸多挑战。
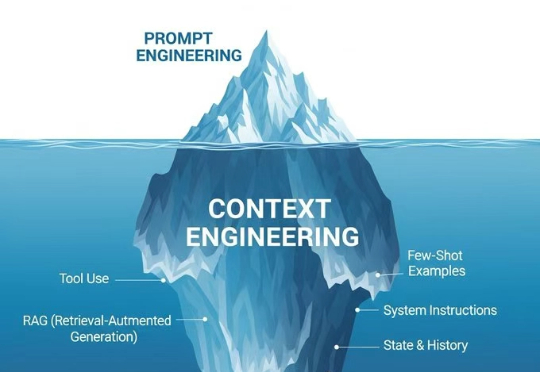
就像是播放音乐,Prompt Engineering是在调音响的音量,那Context Engineering就是在设计整个音响系统,从音源、功放、音箱到房间声学,每个环节都要精心设计。Context Engineering本质上是设计和优化AI模型整个上下文窗口的工程学科。这不只是一个技术升级,更像是思维模式的根本转变。

继提示工程之后,「上下文工程」又红了!这一概念深得Karpathy等硅谷大佬的喜欢,堪称「全新的氛围编程」。而智能体成败的关键,不在于精湛的代码,而是上下文工程。
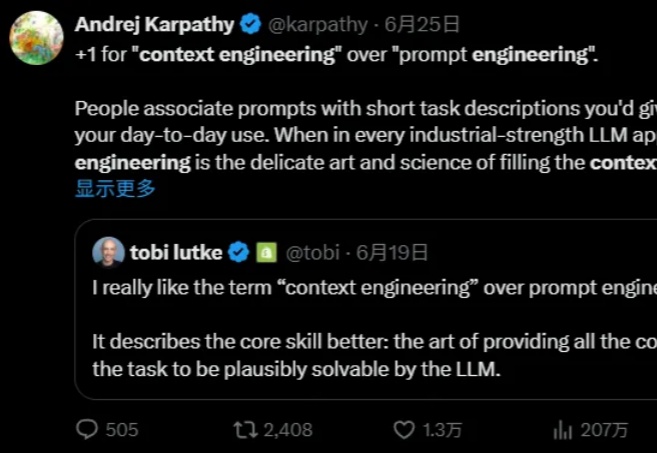
最近「上下文工程」有多火?Andrej Karpathy 为其打 Call,Phil Schmid 介绍上下文工程的文章成为 Hacker News 榜首,还登上了知乎热搜榜。
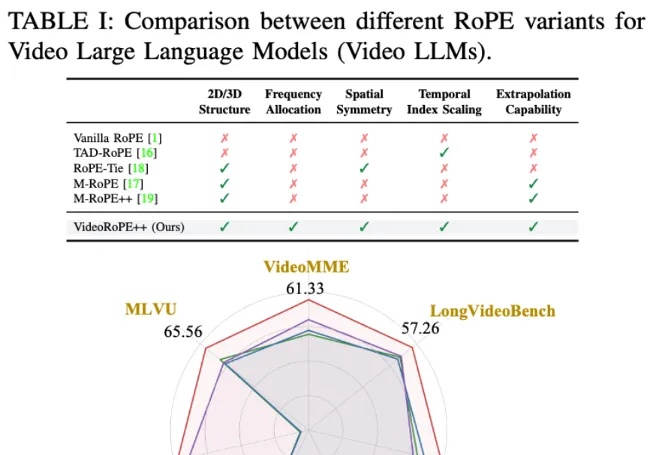
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
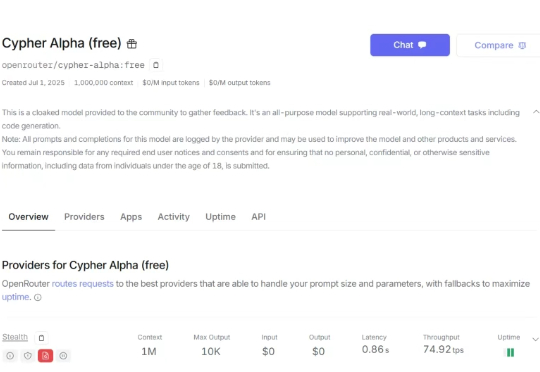
OpenRouter 又上新神秘模型了,支持 100 万 token 上下文,猜猜是谁家的。 刚刚,OpenRouter 上出现了一个神秘模型,该模型被命名为「Cypher Alpha」。其可以免费使用,100 万 token 上下文,还具有推理能力。
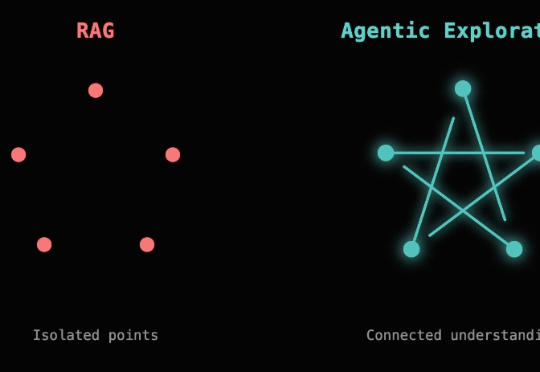
这两天读到开源的代码 Agent,Cline 团队的一篇博客,《Why Cline Doesn't Index Your Codebase (And Why That's a Good Thing) 》,做了一些整理和探索,来分享一下这篇博客内容。
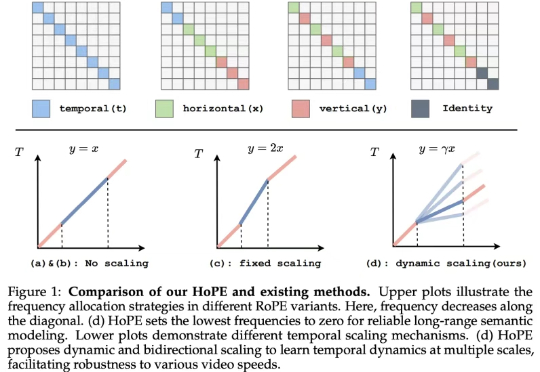
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。