
开源Qwen凌晨暴击闭源Claude!刷新AI编程SOTA,支持1M上下文
开源Qwen凌晨暴击闭源Claude!刷新AI编程SOTA,支持1M上下文编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
来自主题: AI资讯
11011 点击 2025-07-23 09:09
 搜索
搜索
编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
最近使用cursor的朋友可能已经遇到了这个问题:打开Cursor,准备使用Claude- sonnet4开始Vibe Coding,却看到了"Model not available"的提示。这不是您的网络问题,而是Cursor对中国地区用户限制了高级模型的访问。对于习惯了AI辅助编程的工程师来说,这简直像是突然失去了得力助手。

Claude Code 出来之后,很多人都在说“一个人 + AI 就可以独立写应用了”。

大模型有苦恼,记性太好,无法忘记旧记忆,也区分不出新记忆!基于工作记忆的认知测试显示,LLM的上下文检索存在局限。在一项人类稳定保持高正确率的简单检索任务中,模型几乎一定会混淆无效信息与正确答案。

Trae 2.0 即将到来,根据 Trae 的发布说明,这次带来的 TRAE SOLO 功能将极大改变你的编程体验!Trae 团队深信,一个真正强大的编码 AI 需要完全理解你的工作全貌才能发挥最佳效果。正是基于这一理念,他们打造了 SOLO —— 一个智能上下文工程师。

MiniMax 在 7 月 10 日面向全球举办了 M1 技术研讨会,邀请了来自香港科技大学、滑铁卢大学、Anthropic、Hugging Face、SGLang、vLLM、RL领域的研究者及业界嘉宾,就模型架构创新、RL训练、长上下文应用等领域进行了深入的探讨。

AI 不该只是工具,而应该成为团队中的「智能中枢」。2023 年 3 月,微软发布 Office Copilot,掀起 AI 办公革命的第一波浪潮。然而,这场变革止步于简单的「智能助手」或「聊天工具栏」的辅助层面,受限于软件割裂、缺乏上下文记忆与协作能力,Copilot 式插件未能从根本上重构办公逻辑。
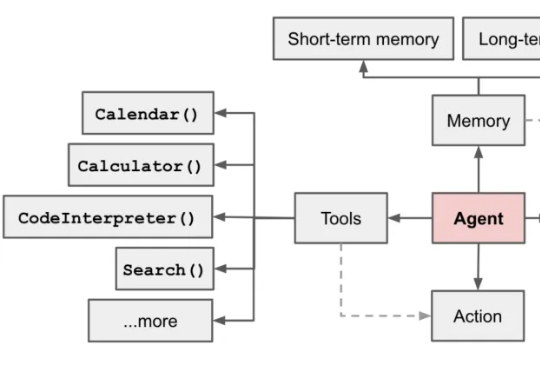
超长上下文窗口的大模型也会经常「失忆」,「记忆」也是需要管理的。

自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。
在上一篇关于子模优化与多样化查询的文章发表后,我们收到了来自圈内很多积极的反馈,希望我们能多聊聊子模性(submodularity)和子模优化,尤其是在信息检索和 Agentic Search 场景下的更多应用。