# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大数字一向吸引眼球。
千亿参数、万卡集群,——还有各大厂商一直在卷的超长上下文。
从一开始的几K几十K,发展到了如今的百万token级别。
Gemini的最新版本可以接收200万个token作为上下文。
这大概相当于140万个单词、2小时视频或者22小时的音频。

但不知诸位平时用得着这么长的上下文吗?毕竟100K已经相当于一部比较长的小说了。
更重要的是,LLM真的能在这个长度上进行推理吗?
近日,有两篇独立研究分别表明:长上下文水分很大!LLM实际上并不能「理解」内容。
首先是来自UMass、AI2和普林斯顿的研究人员,推出了一项针对性的测试。

论文地址:https://arxiv.org/pdf/2406.16264
代码和示例数据:https://github.com/marzenakrp/nocha
当前传统的长上下文测试手段一般被称为「大海捞针」(needle-in-a-haystack):

将一个事实(针)嵌入到大量的上下文信息(干草堆)中,然后测试模型能否找到这根「针」,并回答与之相关的问题。
这种方式基本上衡量的是LLM的检索能力,有些流于表面。
于是研究人员构建了NoCha(小说挑战)数据集,让模型根据所提供的上下文(书籍)验证声明的真假。

如下图所示,由小说的粉丝根据书籍内容,提出关于同一事件或角色叙述的一对相反的声明。
LLM看完小说后需要分别判断两个问题的真假(确保是根据理解做题,打击在考场上瞎蒙的)。
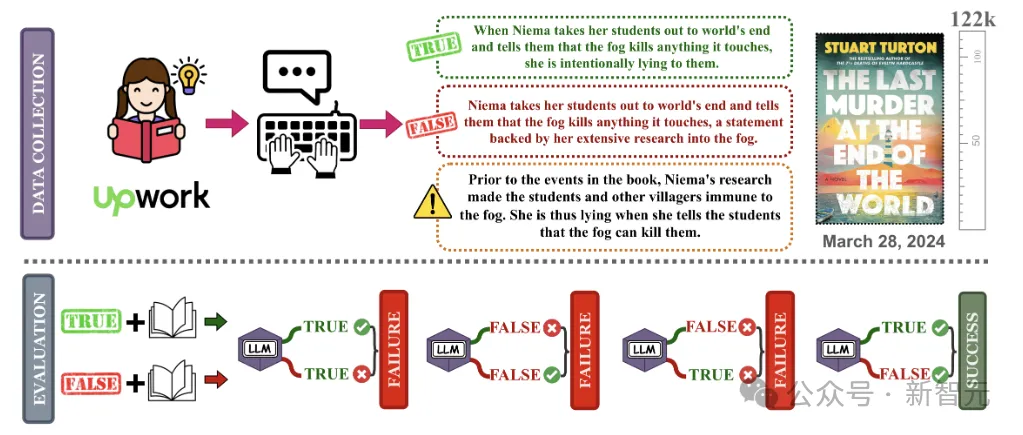
对于一对问题的回答有四种情况,只有两个问题全对时才能得一分。
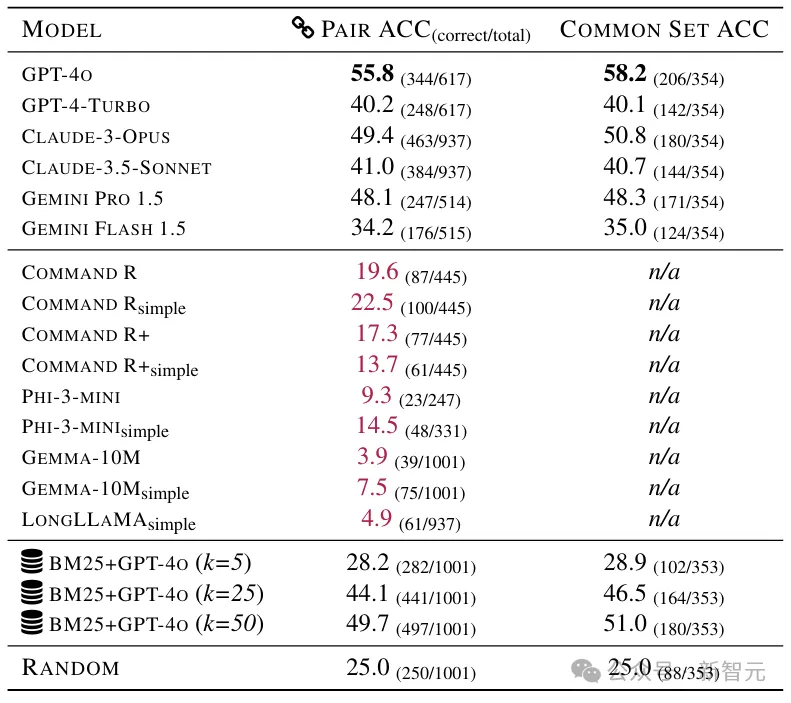
研究人员测试了目前最强的一些长上下文模型(包括闭源和开源),并将成绩单贴在墙上,公开处刑:
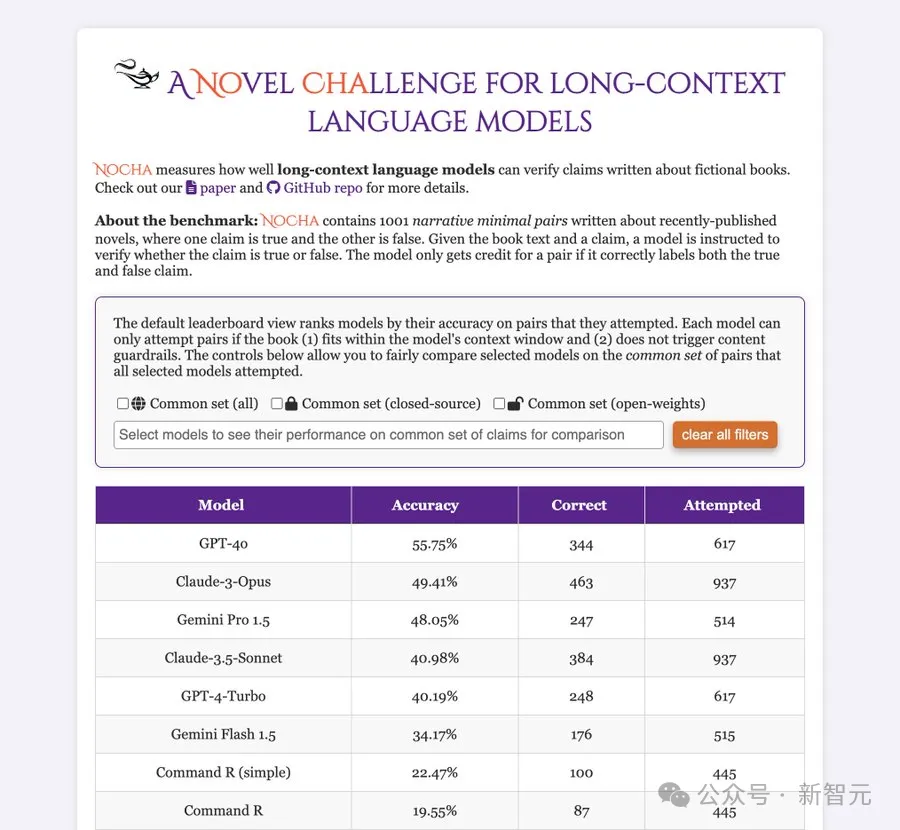
首当其冲的是GPT-4o,虽然全班第一,但是55.75分。
而开源阵营的成绩直接惨不忍睹,表现最好的Command R(simple)只有22.47%的准确率。
——要知道,这考试瞎蒙也能得25分(四选一)。
当然,这也说明人家不是瞎蒙的,确实动脑子了。
另一篇研究来自UCSB,考察的是视觉大模型(VLM)的长上下文能力。

论文地址:https://arxiv.org/pdf/2406.16851
主要的实验思路如下图所示,研究人员通过不断增加上下文长度(干扰图片的数量),将现有的VQA基准和简单图像识别集 (MNIST) 扩展为测试长上下文「提取推理」的示例。

结果在简单VQA任务上,VLM的性能呈现出惊人的指数衰减。
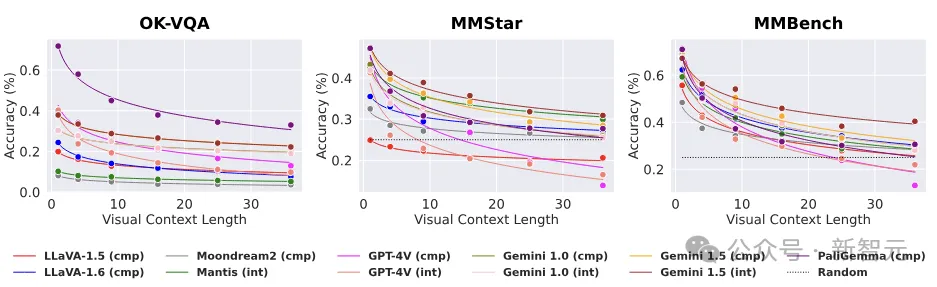
——LLM:原形毕露了家人们。
而与实际研究相对的,在今年早些时候,谷歌展示了几个预先录制的演示。
让Gemini 1.5 Pro搜索阿波罗11号登月的电视直播记录(约402页),查找包含笑话的引语,以及在电视直播中找到与铅笔素描相似的场景。

主持这次简报会的谷歌DeepMind研究副总裁Oriol Vinyals表示,「Gemini 1.5 Pro可以在每一页、每一个单词上执行此类推理任务。」
一千零一夜
第一篇工作被作者命名为「One Thousand and One Pairs」(下面这盏灯应该也是这么来的)。

一千零一在这里有两个含义,首先用于测试的材料基本都是小说,对于大模型来说,算是故事会了;
其次,作者真的花钱请人注释了刚刚好1001个问题对。
为了保证模型无法依靠自己的知识来作弊,这1001个问题大部分来自于最近出版的虚构叙事类读物。
NoCha数据集包括63本新书(33本于2023年出版,30本于2024年出版)和四本经典小说,书籍的平均长度为127k个token(约98.5k个单词)。
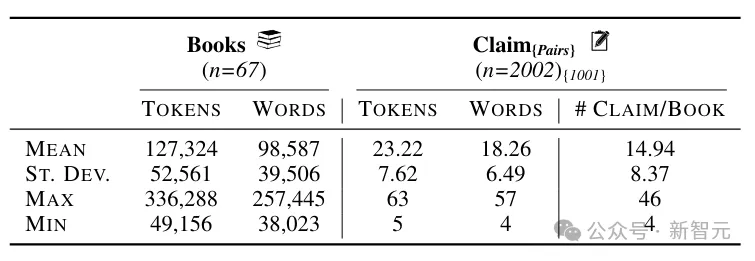
注释者首先写出关于书中事件或人物的真实陈述,然后针对同一对象创建相应的虚假陈述,同时还需要给出一个简短的解释,说明为什么这些说法是正确或错误的。

为了确保声明的质量,作者聘请了读过相同书籍的注释者,来验证五本书中的128个声明,并最终对其中的124个达成了一致。
下面给出参加本次考试的考生信息(开源和闭源两大阵营):

以及考试成绩:
如果按照小说类型划分,所有六个闭源模型在历史小说上的准确率为56.4%,当代小说为46.8%,推理小说为38.8%。
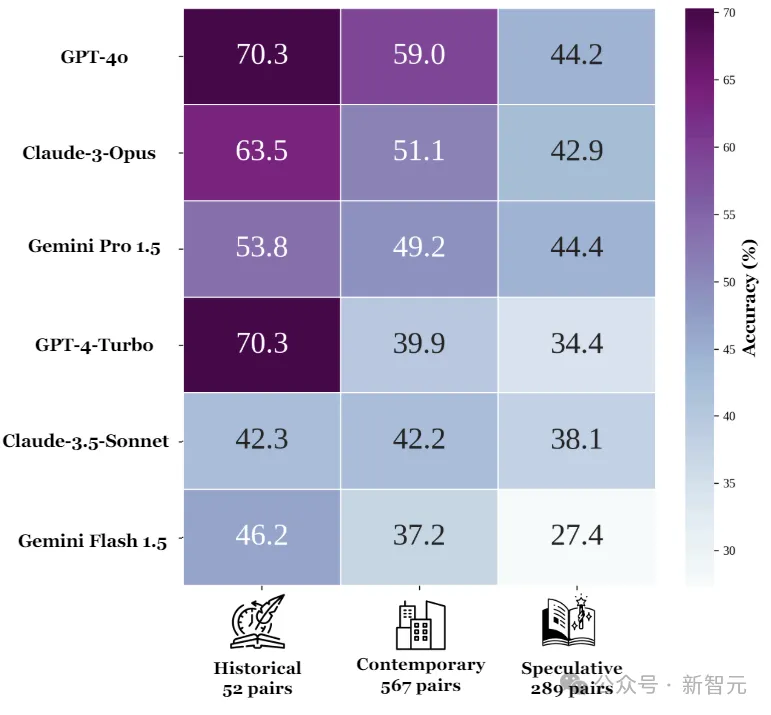
对于每个模型来说,都是历史小说的准确度最高,当代小说次之,推理小说的准确度最低。
从这个结果来看,貌似LLM的推理更多依赖于自身参数中的知识。
接下来做个对比实验:如果某个主张可以通过书中的一小部分内容来单独验证,那么提供本书的其余部分是否会影响其准确性?
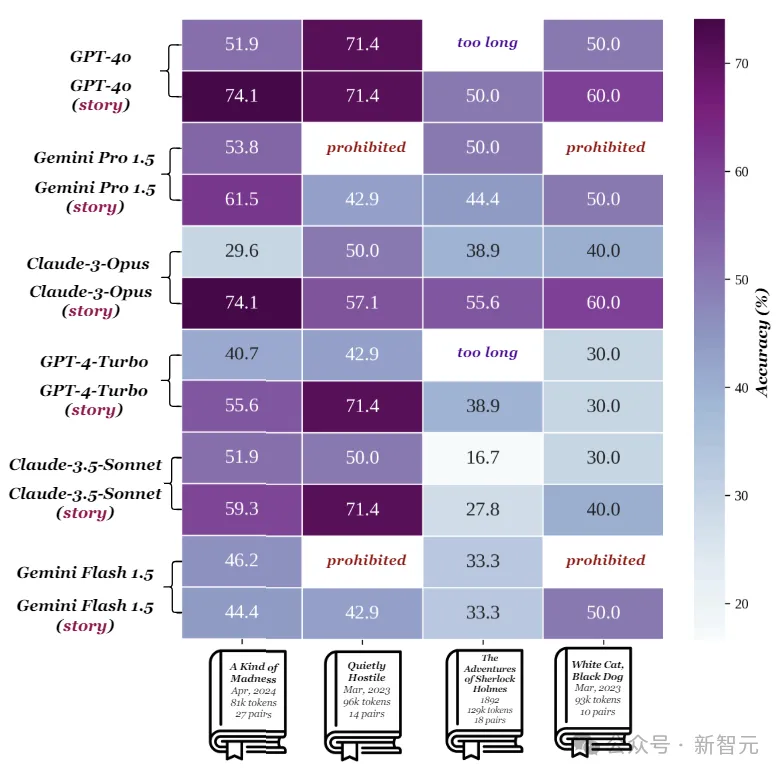
上图显示了在四个短篇故事集上的模型性能,每两行为一组,上面一行表示给出整本书(约129k token)时的准确率,下面表示只给出与声明相关的部分(约21k token)。
Gemini对于添加上下文的表现相对稳健,而Claude-3-Opus的准确度直接下降了44.5%,Claude-3.5-Sonnet、GPT-4-Turbo和GPT-4o的表现也大幅下降。
作者表示,与句子层面的检索任务相比,模型在验证需要考虑整本书(或大部分)内容的问题时,显得力不从心。
另外,书中的一些隐含信息对于人类读者来说是明确的,但LLM却无法理解。
大海捞针
另一项研究来自加州大学圣巴巴拉分校(UCSB),作者引入了 LoCoVQA,一种带有干扰项的长上下文视觉问答 (VQA) 基准生成器。
LoCoVQA可以提供与问题相关的图像序列,以及一组可配置的视觉干扰项,从而准确评估VLM如何在杂乱的上下文中仅提取与查询相关的信息。
从原理上讲,这也是一项「大海捞针」的任务。
另外,LoCoVQA的方法能够以任意图像理解数据集为基础,创建长上下文图像理解测试。
通过LoCoVQA合成的样本包含一个或多个与问答对(????、????)相对应的内容图像????。
内容图像可以从各种图像理解基准中采样,例如OK-VQA、MMStar 、MNIST等。
除了内容图像之外,每个样本还包括最多35个干扰图像(来自相同或者不同的数据集)。

VLM的输入样本可以是多个交错的图像,也可以是上面这种排列为网格的合成图像。
OK-VQA(Outside Knowledge Visual Question Answering)是一个单图像视觉问答数据集,包含5072个问题-答案-图像三元组。它需要外部知识来超越图像进行推理。

LoCoVQA生成分布内的长上下文OK-VQA样本,确保内容图像不会出现可能使评估复杂化的概念冲突。
实验使用三个指标对样本进行评分:精确匹配(如果模型的响应包含任何真实答案作为子字符串,则为满分)、连续文本生成、和 ROUGE(候选人和推荐人之间)。
为了解决内容干扰冲突问题(视觉上下文中多个相似分布的图像使QA对模糊),作者实现了一种基于LM的鲁棒过滤方法。
对于每个视觉上下文图像,提示GPT-4列出前五个实体,如果存在重叠,则认为该问题可能含糊不清。
这里使用合成任务构建「序列VQA」数据集,将多个OCR示例作为交错图像输入,要求VLM列出所有文本(OCR规范数据集采用MNIST)。
为了获得所需的视觉上下文长度,研究人员从大约60K图像的MNIST训练集中采样1到8个随机颜色的数字,将它们的大小调整到其他上下文图像最大高度的1/6到1/2之间。
剩余的干扰图像是从5K个MS COCO的子集中随机采样的。VLM的任务是列出序列中存在的所有手写数字。

通过改变序列中的位数,可以动态调整多图像干扰OCR任务的难度级别。

上图展示了9个图像上下文中包含1、4 和8个数字的示例。仅当存储的生成数字字符串与基本事实完全匹配时,输出才被认为是正确的。
参赛的VLM如下图所示:
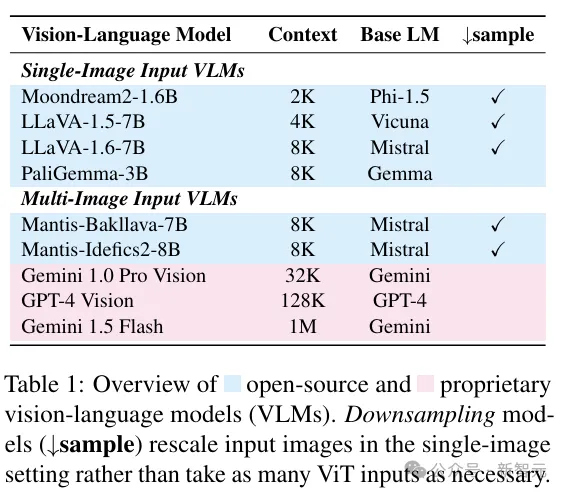
研究人员在LoCoVQA生成的基准上,评估了以上九种视觉语言模型的性能。
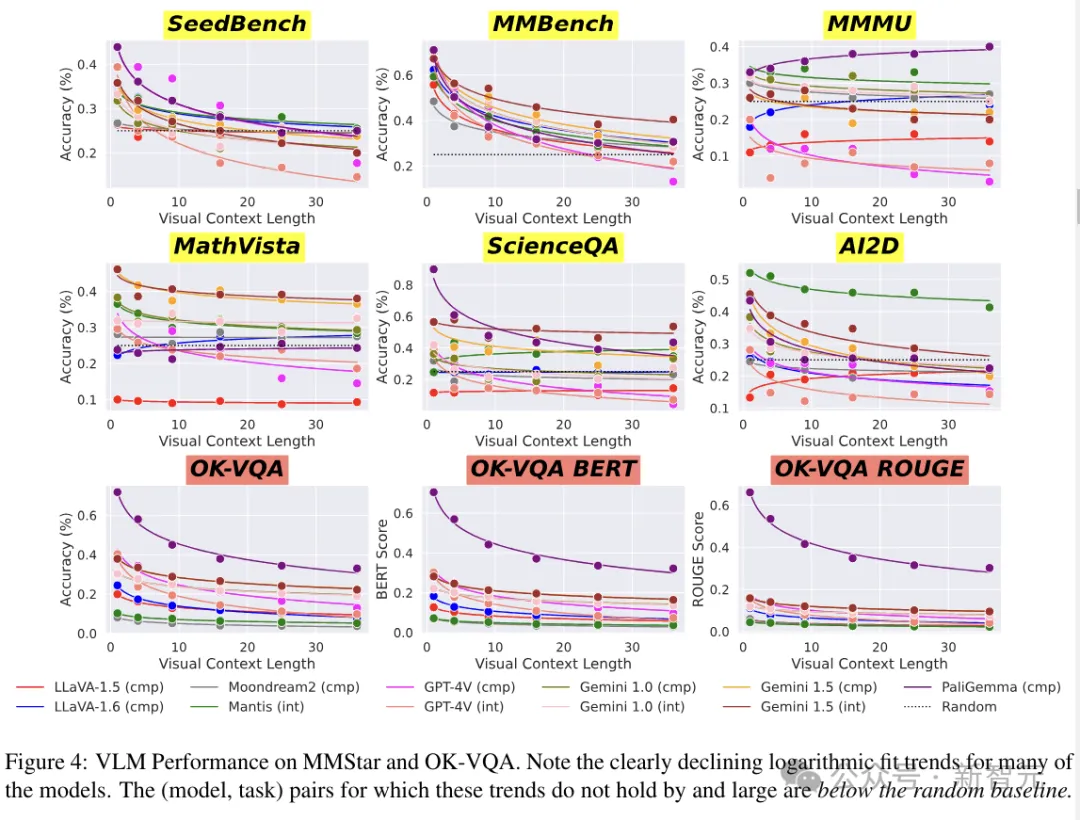
上图结果展示了单图像LoCoVQA任务中,模型性能如何随着视觉上下文长度的增加而变化。
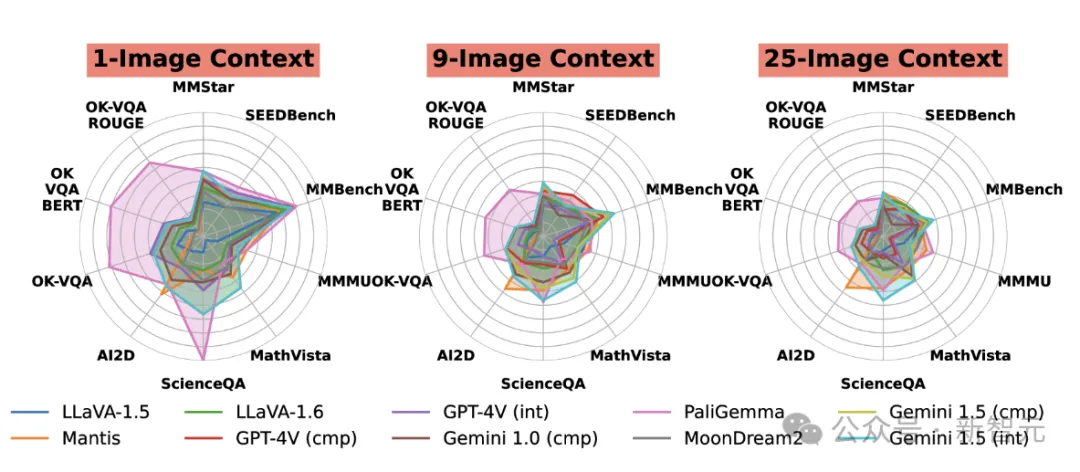
上图为每个任务的模型在上下文长度为1、9和25时的性能,比较了不同模型在各种任务上的相对优势。
与其他模型相比,PaliGemma在OK-VQA上表现出色,而Mantis在AI2D上表现也很好。这些差异可能是由于训练任务的变化造成的。
参考资料:
https://techcrunch.com/2024/06/29/geminis-data-analyzing-abilities-arent-as-good-as-google-claims/
文章来自于微信公众号“新智元”,作者 “新智元”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
