
Agnes AI推出无限期免费API后,一周烧出3.12万亿Token!本周再次升级模型服务!
Agnes AI推出无限期免费API后,一周烧出3.12万亿Token!本周再次升级模型服务!全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!
来自主题: AI资讯
9572 点击 2026-06-18 16:05
 搜索
搜索
全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!
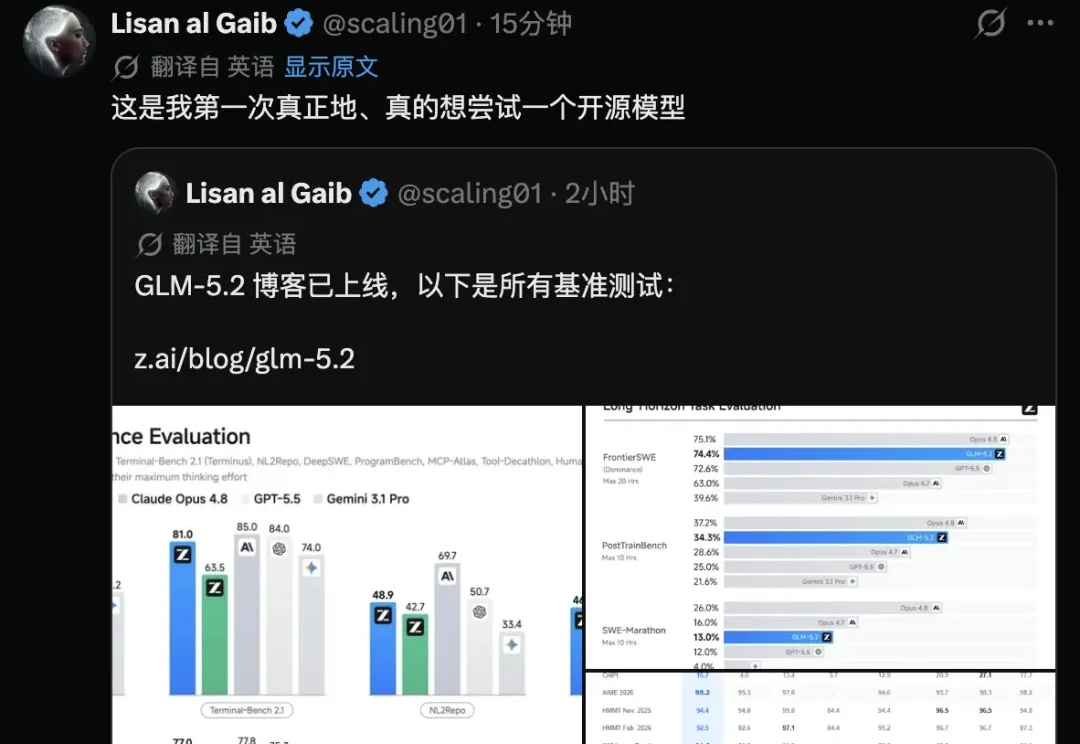
GLM-5.2 正式发布,震撼全网,主打长程任务能力,配合 1M token 上下文窗口,且完全开源(MIT 协议)。在相近的 token 消耗下,GLM-5.2 的能力大致介于 Opus 4.7 和 Opus 4.8 之间,参数仅为753B。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。

过去很长一段时间里,AI 行业衡量模型进步的方式都相当直观:参数更大、榜单更高、推理更强、上下文更长。每一次模型发布,行业都会盯着数学、代码、知识问答和多模态基准测试,看它是否又向通用智能迈近了一步。
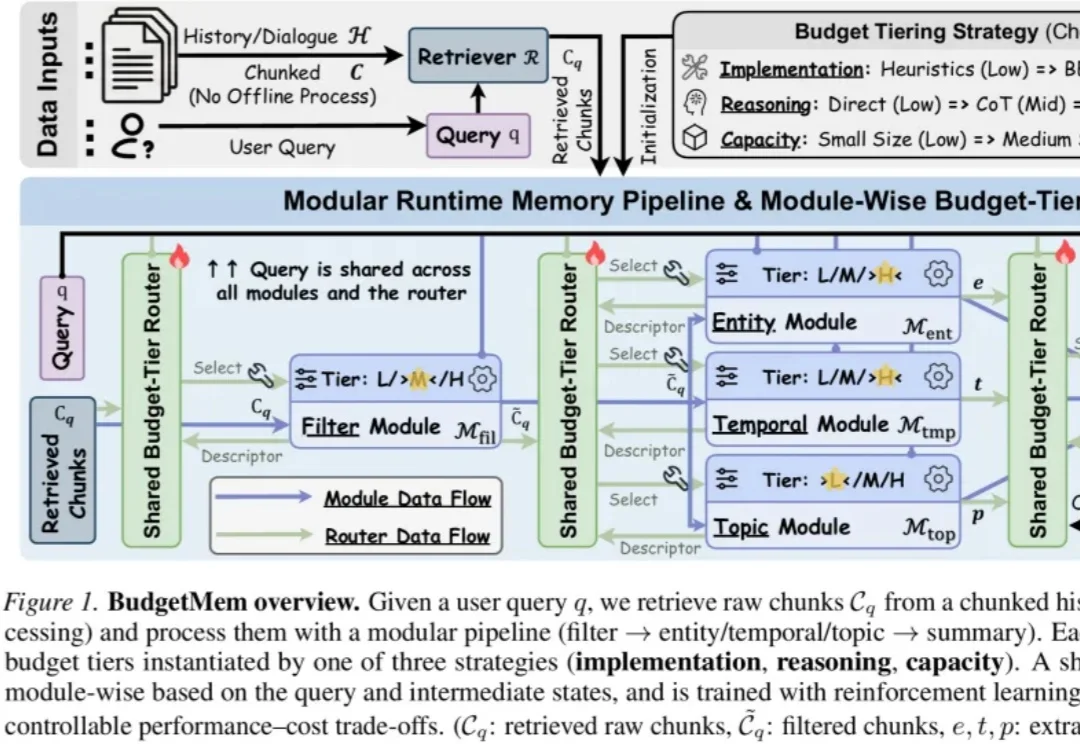
当 LLM Agent 处理长期对话、多轮交互和复杂文档时,Memory 已经成为不可或缺的核心模块。它帮助智能体保存历史、检索信息、维持个性化上下文,并支撑跨时间的推理能力。
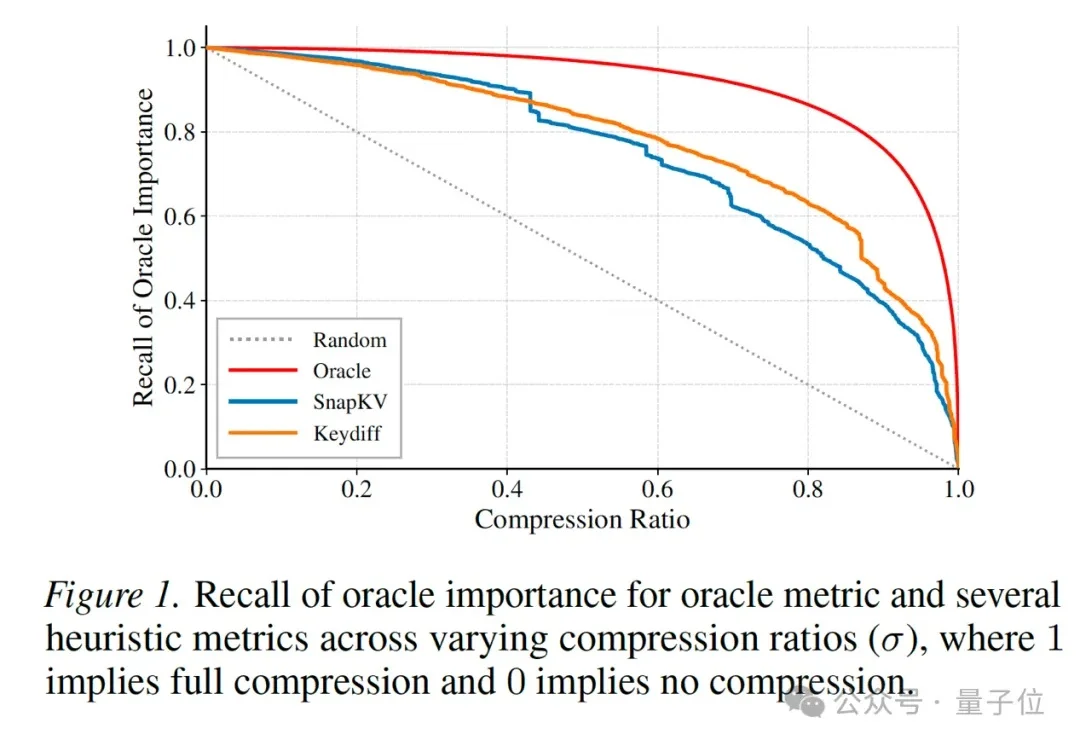
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。

GLM-5.2 是智谱迄今能力最强的开源模型,支持真正可用的 1M 上下文,并在长程任务中继续保持领先。它也依旧是我们心中最强的国产 Coding 模型。
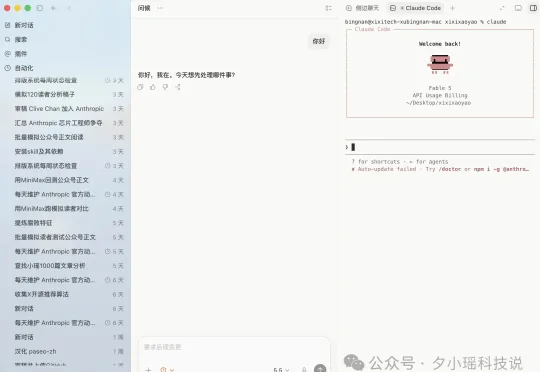
所以,教你一招把Claude code塞进Codex里。所以我现在的工位长这样——左边是 GPT,右边跑着 Claude Code,同一个窗口。Codex负责管规划、把控进度,Claude code负责干活;Fable 拒答降级的时候,直接复制上下文丢给左边的GPT接住,无缝换人。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。