
独家|经纬领投了一家因果世界模型公司“Aether AI”
独家|经纬领投了一家因果世界模型公司“Aether AI”投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。
来自主题: AI资讯
9205 点击 2026-06-18 17:27
 搜索
搜索
投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。

刚刚过去的2026智源大会上,由智源研究院孵化的星源智发布了全球首个具身交互世界模型ω-EVA,就这一前沿命题给出了全新的差异化解法。传统世界模型的困境是"只预测,不参与"。它们训练时学习未来状态,推理时却与动作生成分割——视频生成得再精美,机器人该撞墙还是撞墙。

物理AI基础设施公司章鱼动力(SynapX)近日已完成新一轮5000万美元融资。结合此前两轮5000万美元的连续融资,章鱼动力在过去3个月内已累计完成接近10亿元人民币的融资。

被算力荒逼出来的硬核奇迹!腾讯米哈游老兵组成的「草根」团队,硬在国产芯片上炼出了超10分钟的绝对物理一致性。画面可以糙,物理绝不能假,这就是通往AGI的真正基石。
达摩院联合高校推出WorldOlympiad评测基准,跳出传统视频“唯画质”的评价逻辑,以物理真实性、三维几何一致性、长时序交互保真度三大维度,搭配游戏、机器人、通用实景三大场景,打造一套全方位的视频世界模型评测体系。

逆矩阵计划于 2026 年底发布旗舰模型。

刚刚,大晓机器人半年融资数亿美元,开悟世界模型同时刷新四大权威榜单第一,4B参数硬刚28B大模型!具身智能的「ChatGPT时刻」真的要来了?
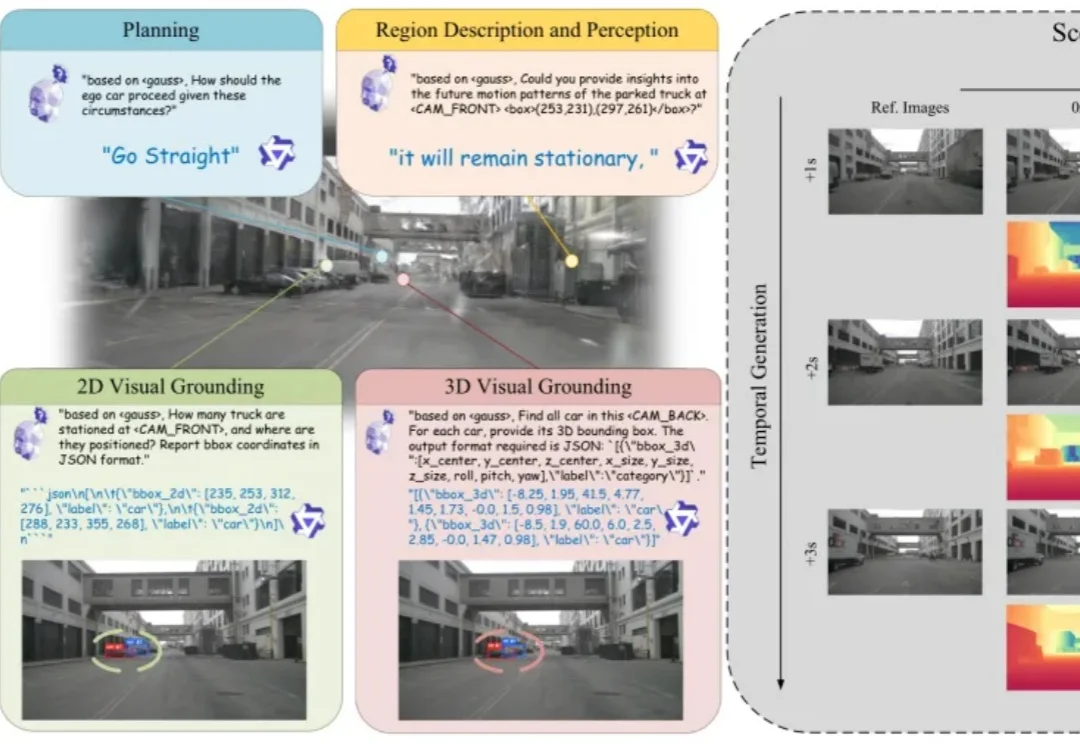
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。

硬氪获悉,具身智能世界模型公司「千诀科技」日前完成数亿元A轮融资,本轮由京铭资本领投,山东新动能、山东财金资本、元禾厚望、芯能创投、南创投、英诺天使基金、尚势资本、仁爱集团、玄素投资等机构共同投资,投资方阵容汇集了国家队、产业方、市场化基金及家族办公室。Maple Pledge枫承资本长期出任私募股权融资顾问。

随着视频生成技术的发展,模型正在从短视频片段合成,向流式长视频生成演进。然而,仅仅做到视觉上的逼真是不够的。一个功能完备的视频世界模型,必须能够在长时序交互中保持稳定的内部状态,并遵循真实世界的物理定律与逻辑规则。