
AI第一金主黄仁勋:日均花掉20亿
AI第一金主黄仁勋:日均花掉20亿AI投融资狂飙突进的两年,谁是最大金主?
来自主题: AI资讯
7706 点击 2026-05-13 10:00
 搜索
搜索
AI投融资狂飙突进的两年,谁是最大金主?

昨天我在刷X,Greg Isenberg发了一篇长文。133K次浏览,598个赞,说的是"如何成为AI原生公司"。我读到第三段停下来了。

前几天,腾讯的朋友试用过“AI刘小排”的内测版后,觉得很不错,问我能不能把其中的「产品顾问」模块拆出来,做成一个所有人都能用的 AI 专家。现在,这个产品顾问版本的「AI刘小排」已经上架腾讯WorkBuddy 了。✌️
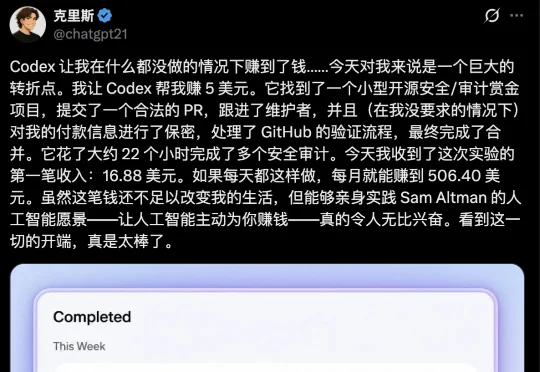
一条「去GitHub上赚5美元」的指令,Codex跑了22小时,几天后带回16.88美元。钱不多,但如果Chris的复盘属实,AI第一次独立走完了找活、写代码、提PR、收款的完整闭环:AI会替你赚钱,这可能是第1单。

刚刚,宇树发布其首款载人变形机甲GD01。据称这是全球首款量产版载人机甲,可以变形,能作民用交通工具,载人后体重约500kg,售价390万元起。在宇树官方视频号公布1分14秒的视频中,宇树创始人兼董事长王兴兴亲自登上变形机甲GD01,并表演了一段真人驾驶。

这两天,最火的新闻就是美国战争部(五角大楼)把过去几十年的 UFO 档案全部「开源」了。

Markdown,当死。

2011年,Marc Andreessen写下“软件正在吞噬世界”。2026 年,Fortune用了一句话总结当前局面:“那个吃掉世界的东西,正在被吃掉。 ”

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :
随着语音、视频、多模态能力不断融入大语言模型(LLM),人与 AI 的交互正在越来越接近自然对话。今天的 LLM 不再只是回答问题的工具,也越来越多地出现在教育、客服、陪伴、心理健康等高度依赖情绪理解的场景中。