
AI爆改陶哲轩30年主页,顺手揪出两个藏了20多年的bug
AI爆改陶哲轩30年主页,顺手揪出两个藏了20多年的bug都以为AI应该先去替数学家证定理,陶哲轩却让它搬30年前的旧网页。一天迁走560篇论文,还从他二十多年前亲手写的老代码里揪出两个连他都不知道的bug。
来自主题: AI资讯
5863 点击 2026-07-14 11:09
 搜索
搜索
都以为AI应该先去替数学家证定理,陶哲轩却让它搬30年前的旧网页。一天迁走560篇论文,还从他二十多年前亲手写的老代码里揪出两个连他都不知道的bug。

近日,新基石研究员、北京大学集成电路学院教授、深圳研究生院信息工程学院院长杨玉超团队,联合中国科学院上海微系统与信息技术研究所宋志棠研究员团队等,在国际顶级学术期刊《科学》发表最新成果,在新型神经动力学计算芯片领域取得重大突破。
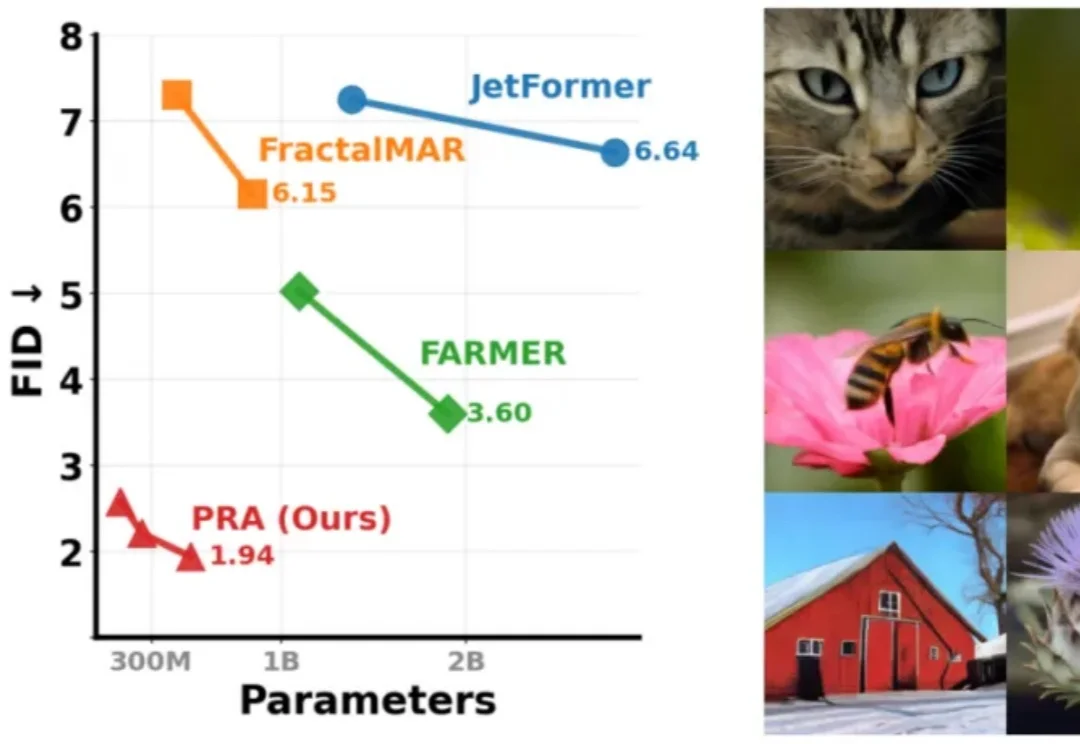
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?
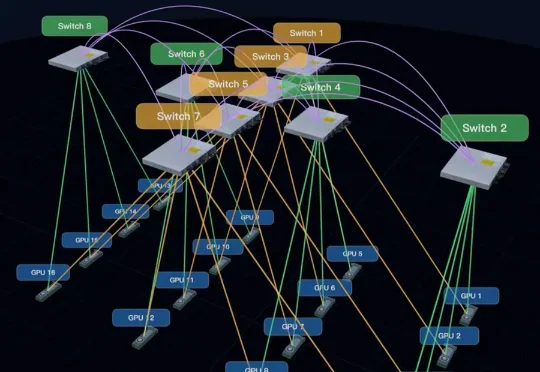
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。
图片来源:Unsplash 在 ChatGPT 的发布将生成式人工智能带入主流市场三年多之后,OpenAI 正将其关注点从个人用户扩展到家庭。 OpenAI 正在旧金山招聘一名专职产品经理,负责在其产

外界不只有 Meta 一家公司表达过收购兴趣。

7 月 7 日这一天,有两条关于中国 AI 公司自研芯片的消息成为热点新闻。

一个AI工具挖出了藏在Linux里15年的致命漏洞,另一个AI却因为一个被录错的数字,让四辆警车把无辜记者当成盗车贼围了起来。
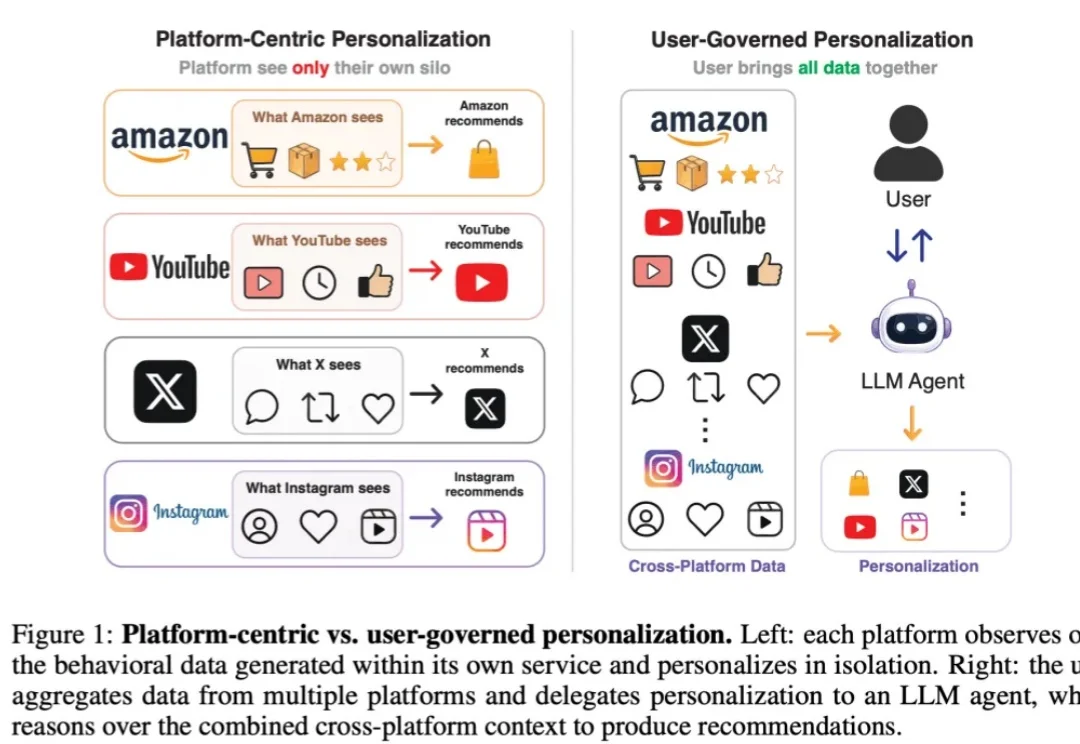
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)