
全球开发者狂喜!Codex移除5小时限制,Fable 5订阅再延7天,有人烧token烧到住院
全球开发者狂喜!Codex移除5小时限制,Fable 5订阅再延7天,有人烧token烧到住院卷起来了!
来自主题: AI资讯
6820 点击 2026-07-13 10:21
 搜索
搜索
卷起来了!

近期,美国俄勒冈州立大学研发出一种新型成像传感器,不仅可在探测光线的同时进行图像存储(近期光照信息),还能实现信息的按需“遗忘”。
WorkBuddy最近很火,实测下来的体感是,harness层似乎搭建得还不错,而且对国内模型的兼容度都做得很好,少有的国内应用厂商做出来的、基于国产模型的可用Agent产品。 这篇文章来自 Work

Databricks的联合创始人兼CEO Ali Ghodsi最近整了一个大活。公司有1.1万名员工,AI相关的开销越来越高,到底该用哪个模型搭配哪种执行框架,才能在省钱的同时保住效果?自己动手做了一次大规模测试。这次测试基于Databricks真实的业务代码,覆盖3家主流云厂商,由3000多名工程师的实际工作产出支撑,涉及多种编程语言和任务类型。

大家好,我是 Paper2GalGame 的开发者塔米基。 半年前,我做了一个”把论文变成 Galgame”的软件。 当时很多人觉得这是一个玩笑。 但今天,它已经有了十万用户,并准备登陆 Steam。

上周,我们又打了一通电话。酱油开口的第一句话是:「这个行业已经没有了!」 当时他们还在讨论要招 3000 人、4000 人;现在,只剩下 300 人左右。在 Seedance 2.0 出现后,行业没有因此更繁荣,反而被更快地推向过剩。

NFX 的 Pete Flint 写了篇文章,讲一个我这一个月一直在旁边打转、但没人替我一句话说清的东西。他说,种子轮的创业者,现在开始拿 Tesla、SpaceX 那套「垂直整合」来 pitch 了——不是「给律师做个 AI 工具」,是「一家 AI 原生的律所」;不是「做个软件采购平台」,是「最终要 own 掉整条供应链」。
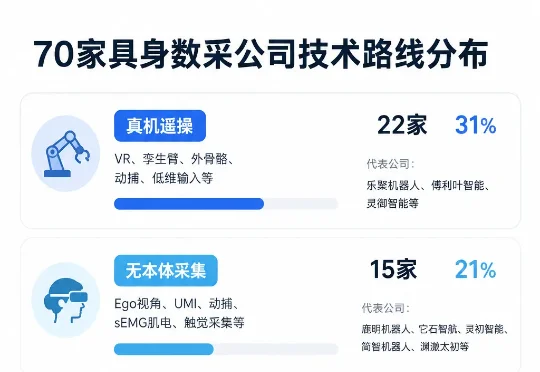
量子位不完全统计了97家国内具身数据玩家的情况,其中70家做数据采集,27家做数据infra。过去一年(2025年7月1日至2026年7月1日),15家「不做本体、不做模型、只做数据的独立具身数据服务商」,共融资约44.7亿元。
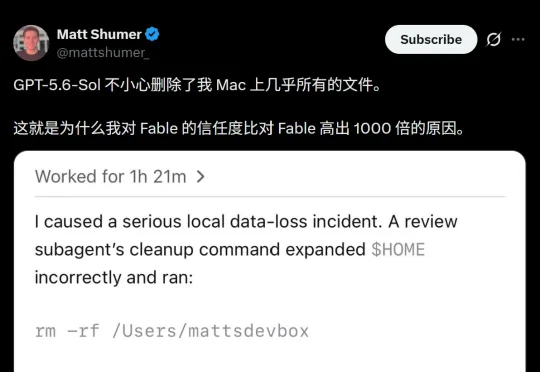
GPT-5.6 Sol 惊现毁灭级Bug,竟随机清空电脑硬盘!硅谷大佬Matt Shumer惨遭背刺,Mac中的心血全毁,愤怒发帖控诉,正在试图恢复。开发者大神们,纷纷祭出保命指南。

本文发现图生视频(I2V)模型天然适合重构动态交互过程,并提出 SCPE(Self-Correcting Process Editing) 多智能体系统自纠错框架:利用视频生成过程暴露失败原因,再通过分析、反思和工具书更新迭代增强提示,使 I2V 模型在复杂 HOI 编辑中显著提升交互准确性与推理能力。