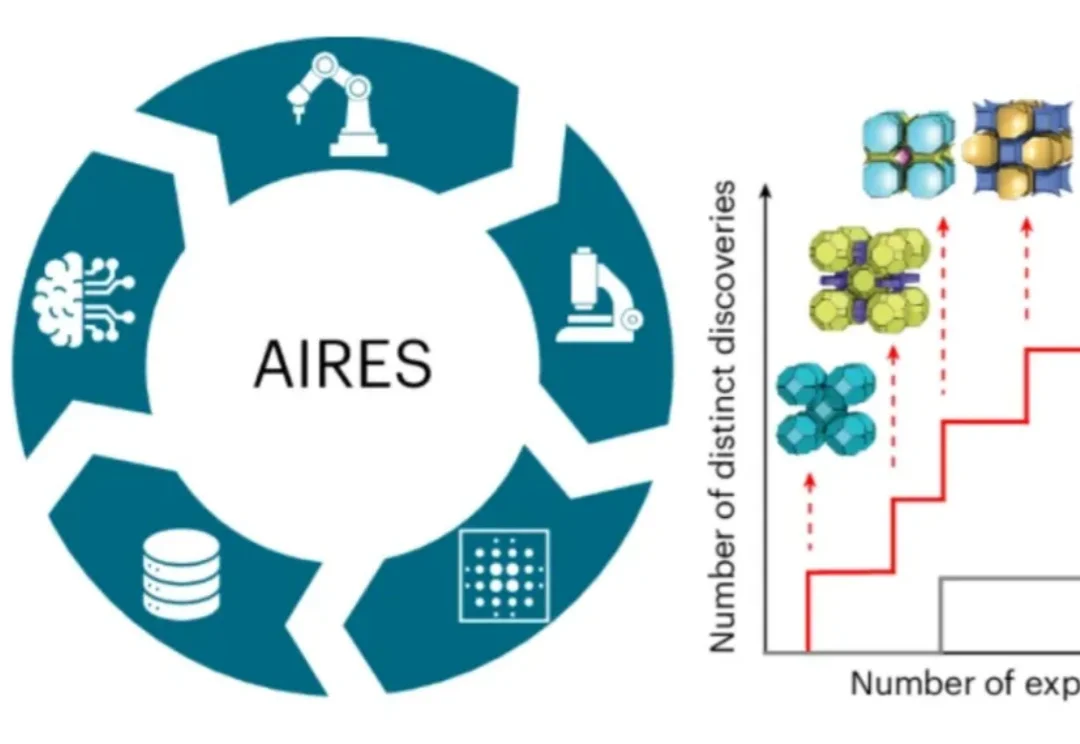
华人博士用AI破解十年材料发现困局,让ZIF晶体发现效率翻倍
华人博士用AI破解十年材料发现困局,让ZIF晶体发现效率翻倍近日,师从新晋诺贝尔化学奖得主奥马尔·亚吉(Omar M. Yaghi)、目前在美国加州大学伯克利分校读博的荣自超,带领一个跨国际的研究团队,打造出名为AIRES (algorithmic iterative reticular synthesis)的机器学习指导的高通量实验平台,
来自主题: AI技术研报
9222 点击 2025-12-11 10:09
 搜索
搜索
近日,师从新晋诺贝尔化学奖得主奥马尔·亚吉(Omar M. Yaghi)、目前在美国加州大学伯克利分校读博的荣自超,带领一个跨国际的研究团队,打造出名为AIRES (algorithmic iterative reticular synthesis)的机器学习指导的高通量实验平台,

2025就要过去了。UC Berkeley、Stanford和IBM联手做了一件大事。他们调研了306份在一线“造 Agent”的从业者问卷,并深度访谈了20个已经成功落地并产生价值的一线企业案例(涵盖金融、科技、医疗等领域)。试图回答一个最朴素的工程问题:一个能用的、赚钱的Agent,到底是用什么架构搭出来的?

当你发现自己刷到的视频、帖子是「AI制造」时,当身边的人用一种「AI腔调」和你说话时,你是不是想要迅速滑走,或者直接拉黑?加州大学伯克利分校等机构的权威研究证实,AI正在改变我们的说话、写作等交流方式,让我们的交际「塑料感」十足。
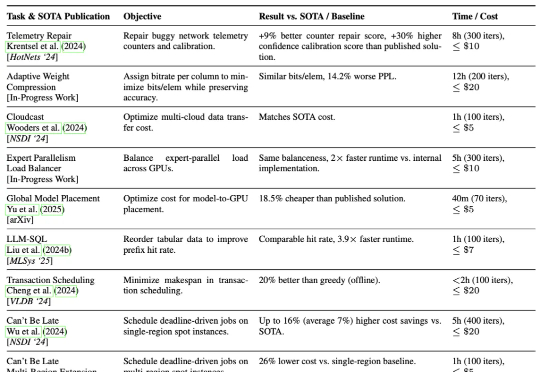
加州大学伯克利分校的研究团队提出了一种AI驱动的系统研究方法ADRS(AI-Driven Research for Systems),它可以通过“生成—评估—改进”的迭代循环,实现算法的持续优化。

加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
![苹果盯上Prompt AI, 不是买产品,是要伯克利团队的[视觉大脑]](https://www.aitntnews.com/pictures/2025/10/15/ca7bf835-a97f-11f0-88f9-fa163e47d677.jpg)
根据外媒 CNBC 消息,苹果公司正和计算机视觉领域的初创企业 Prompt AI,推进收购事宜的 “最后阶段谈判”。
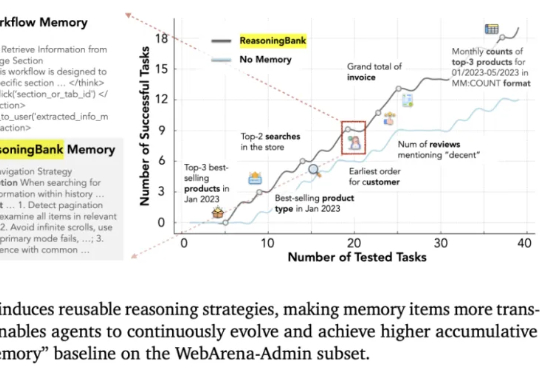
这几天,关于「微调已死」的言论吸引了学术圈的广泛关注。一篇来自斯坦福大学、SambaNova、UC 伯克利的论文提出了一种名为 Agentic Context Engineering(智能体 / 主动式上下文工程)的技术,让语言模型无需微调也能实现自我提升!
库克和马斯克都盯上的CV公司!打开Prompt AI官网,上面介绍了这家公司的定位:一家专注于消费应用视觉智能的AI公司。这家总部位于旧金山的初创公司,其核心团队非常UC伯克利范儿:
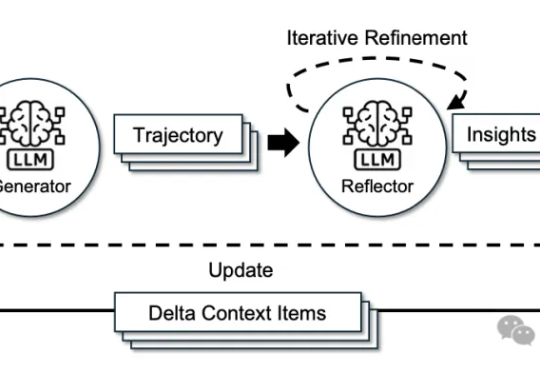
来自斯坦福大学、SambaNova Systems公司和加州大学伯克利分校的研究人员,在新论文中证明:依靠上下文工程,无需调整任何权重,模型也能不断变聪明。他们提出的方法名为智能体上下文工程ACE。

来自加州大学圣地亚哥分校(UCSD)的华人学者Wanda Hou,与加州大学伯克利分校以及Google Quantum AI合作,在谷歌的Sycamore与Willow超导量子处理器上完成了一次别开生面的实验。