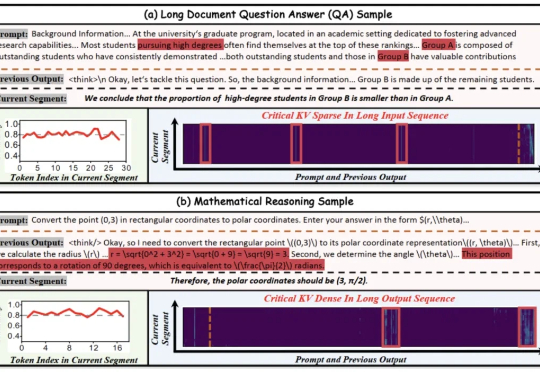
长序列推理不再卡顿!北大华为KV缓存管理框架实现4.7倍推理加速
长序列推理不再卡顿!北大华为KV缓存管理框架实现4.7倍推理加速北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
来自主题: AI技术研报
8045 点击 2025-10-22 14:52
 搜索
搜索
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。
大语言模型(LLM)不仅在推动通用自然语言处理方面发挥了关键作用,更重要的是,它们已成为支撑多种下游应用如推荐、分类和检索的核心引擎。尽管 LLM 具有广泛的适用性,但在下游任务中高效部署仍面临重大挑战。
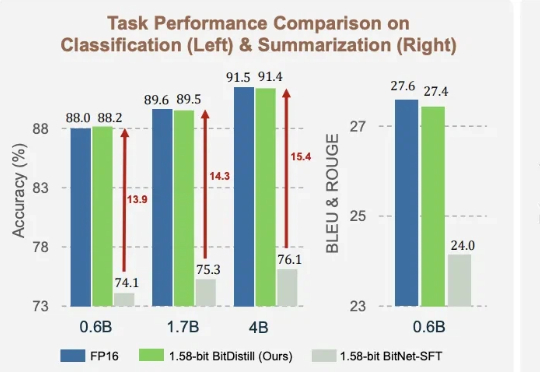
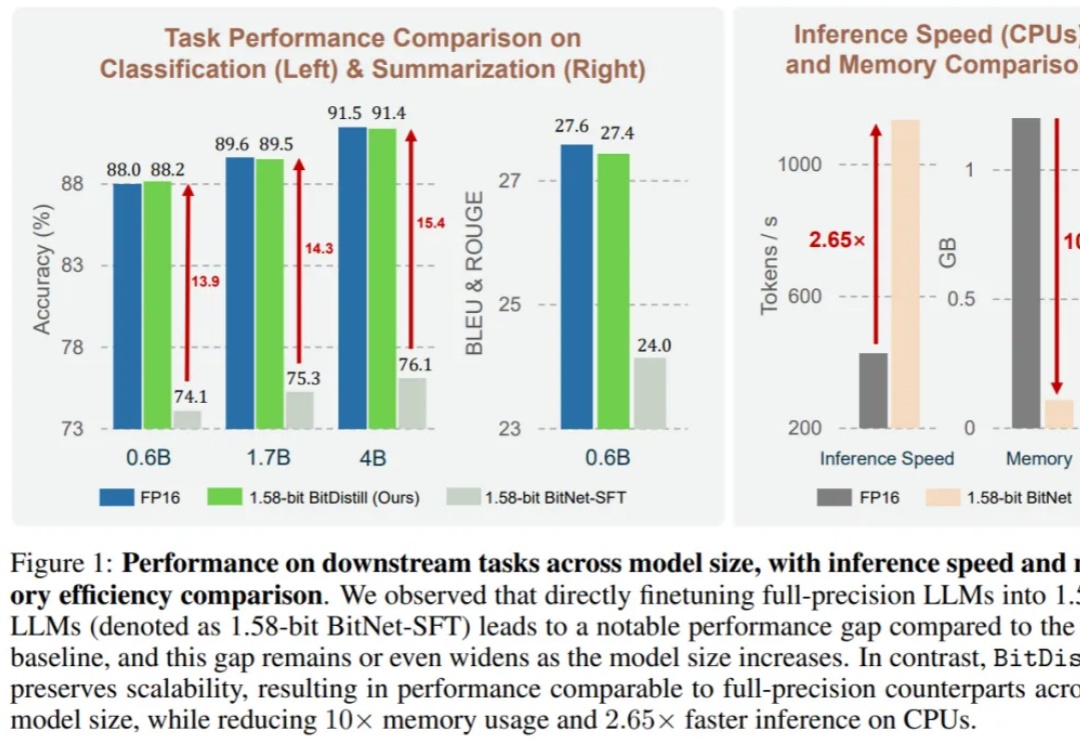
1.58bit量化,内存仅需1/10,但表现不输FP16? 微软最新推出的蒸馏框架BitNet Distillation(简称BitDistill),实现了几乎无性能损失的模型量化。

英伟达面向个人的AI超算DGX Spark已上市!128GB统一内存(常规系统内存+GPU显存),加上允许将两台DGX Spark连起来,直接可以跑起来405B的大模型(FP4精度),而这已经逼近目前开源的最大模型!如此恐怖的实力却格外安静优雅,大小与Mac mini相仿,3999美元带回家!

据报道,英伟达已取消其第一代SOCAMM内存模块的推广,并将开发重点转向名为SOCAMM2的新版本。不久前,英伟达曾表示计划今年为其AI产品部署60-80万个SOCAMM内存模块,但据称随后发现了技术问题,项目两次搁置,并未能下达任何实际的大规模订单。目前开发重点已经转移到SOCAMM 2,英伟达已开始与三星电子、SK海力士和美光合作对SOCAMM 2进行样品测试。

只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。

当前AI大模型(LLM)训练与推理对算力的巨大需求,以及传统计算精度(如FP16/BF16)面临的功耗、内存带宽和计算效率瓶颈。

不使用端侧AI的话,谷歌在Pixel 10上就有虚假宣传的嫌疑了。
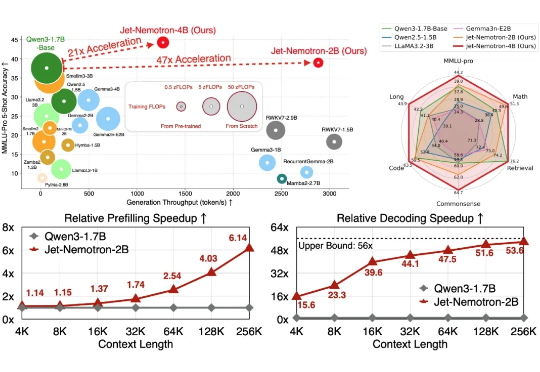
Transformer 架构对计算和内存的巨大需求使得大模型效率的提升成为一大难题。为应对这一挑战,研究者们投入了大量精力来设计更高效的 LM 架构。

英伟达直接把服务器级别的算力塞进了机器人体内。 全新的机器人计算平台Jetson Thor正式发售,基于最新的Blackwell GPU架构,AI算力直接飙升到2070 TFLOPS,比上一代Jetson Orin提高至整整7.5倍,同时能效提高至3.5倍。