DeepSeek删豆包冲上热搜,大模型世子之争演都不演了
DeepSeek删豆包冲上热搜,大模型世子之争演都不演了大模型“世子之争”,果然暗潮汹涌(doge)。 这不“手机内存不够”怎么办,如果你问问DeepSeek老师:你和豆包删一个你删谁?
来自主题: AI资讯
7556 点击 2025-08-21 16:48
 搜索
搜索
大模型“世子之争”,果然暗潮汹涌(doge)。 这不“手机内存不够”怎么办,如果你问问DeepSeek老师:你和豆包删一个你删谁?

今天 ,OpenAI 开源了俩模型:120B/20B 117B 的 gpt-oss-120b 对标 o4-min,按官方说法至少需要 80G 内存,推荐使用单卡 H100 GPU 而刚买的的游戏本,刚好满足gpt-oss-120b 的部署条件

近日,一位开发者在 GitHub 上公开警告称,字节跳动旗下 AI 编程环境 Trae IDE 存在在用户未明确知情的情况下,将数据上传至字节服务器的行为,即便用户已在设置中手动关闭遥测(Telemetry)功能。

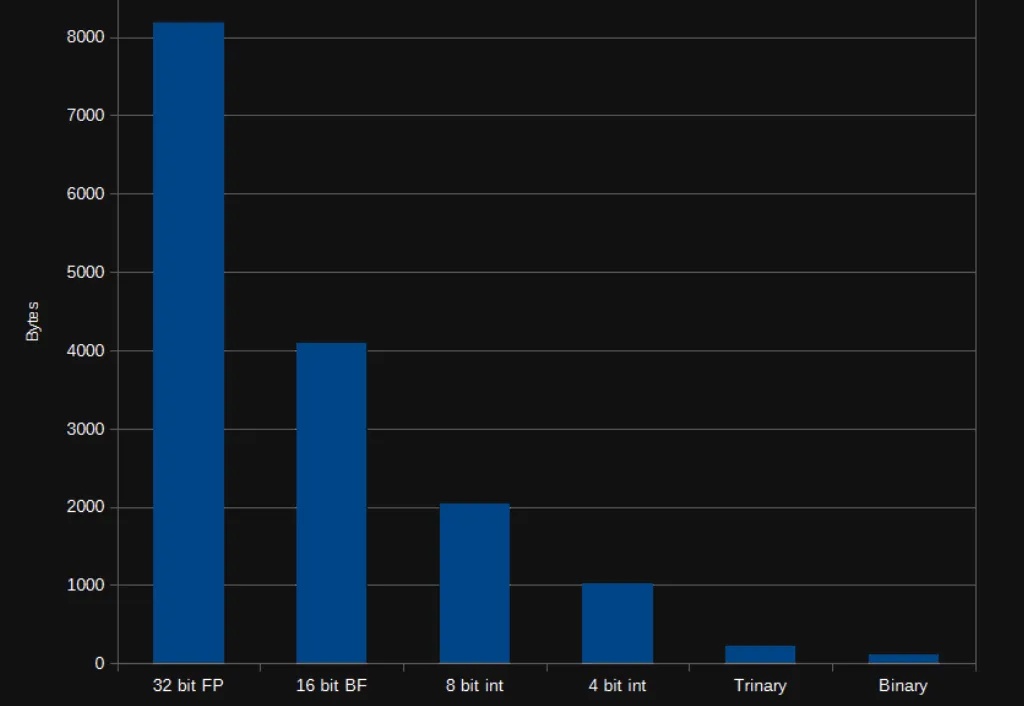
近年来,大语言模型(LLM)的能力越来越强,但它们的“饭量”也越来越大。这个“饭量”主要体现在计算和内存上。当模型处理的文本越来越长时,一个叫做“自注意力(Self-Attention)”的核心机制会导致计算量呈平方级增长。这就像一个房间里的人开会,如果每个人都要和在场的其他所有人单独聊一遍,那么随着人数增加,总的对话次数会爆炸式增长。
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。

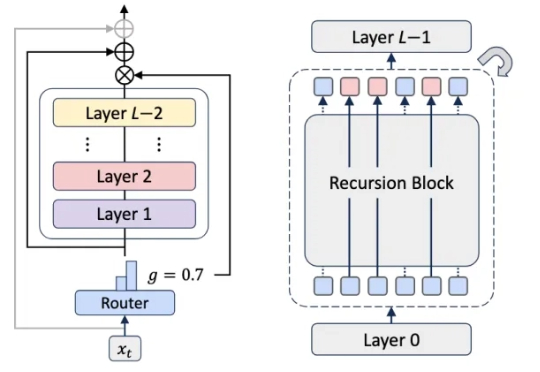
Transformer杀手来了?KAIST、谷歌DeepMind等机构刚刚发布的MoR架构,推理速度翻倍、内存减半,直接重塑了LLM的性能边界,全面碾压了传统的Transformer。网友们直呼炸裂:又一个改变游戏规则的炸弹来了。

MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。
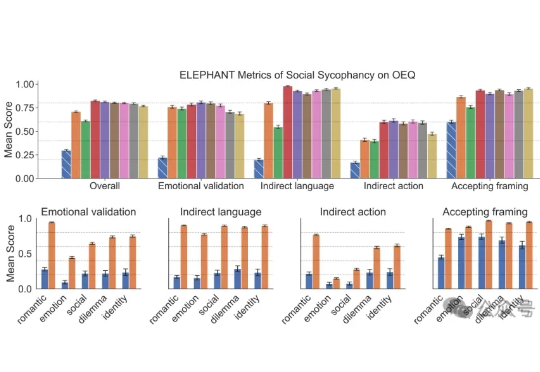
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。

当地时间 6 月 26 日,在上个月的 Google I/O 上首次亮相预览后,谷歌如今正式发布了 Gemma 3n 完整版,可以直接在本地硬件上运行。
本周五凌晨,谷歌正式发布、开源了全新端侧多模态大模型 Gemma 3n。谷歌表示,Gemma 3n 代表了设备端 AI 的重大进步,它为手机、平板、笔记本电脑等端侧设备带来了强大的多模式功能,其性能去年还只能在云端先进模型上才能体验。