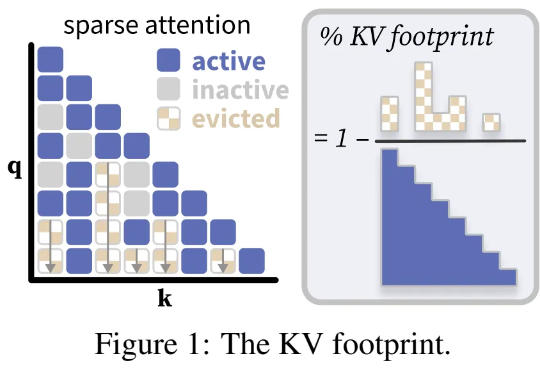
Cache Me If You Can:陈丹琦团队如何「抓住」关键缓存,解放LLM内存?
Cache Me If You Can:陈丹琦团队如何「抓住」关键缓存,解放LLM内存?普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
来自主题: AI技术研报
10881 点击 2025-06-25 10:51
 搜索
搜索
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文了。近期,诸如「长思维链」等技术的兴起,带来了需要模型生成数万个 token 的全新工作负载。
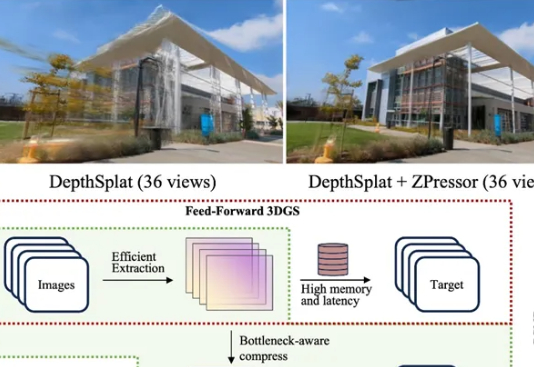
ZPressor能高效压缩3D高斯泼溅(3DGS)模型的多视图输入,解决其在处理密集视图时的性能瓶颈,提升渲染效率和质量。

最近,华为在MoE训练系统方面,给出了MoE训练算子和内存优化新方案:三大核心算子全面提速,系统吞吐再提20%,Selective R/S实现内存节省70%。
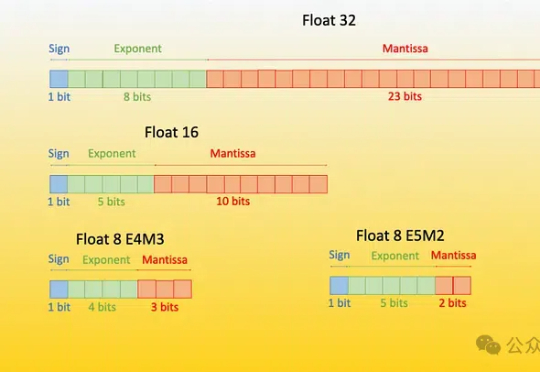
原生1bit大模型BitNet b1.58 2B4T再升级!微软公布BitNet v2,性能几乎0损失,而占用内存和计算成本显著降低。
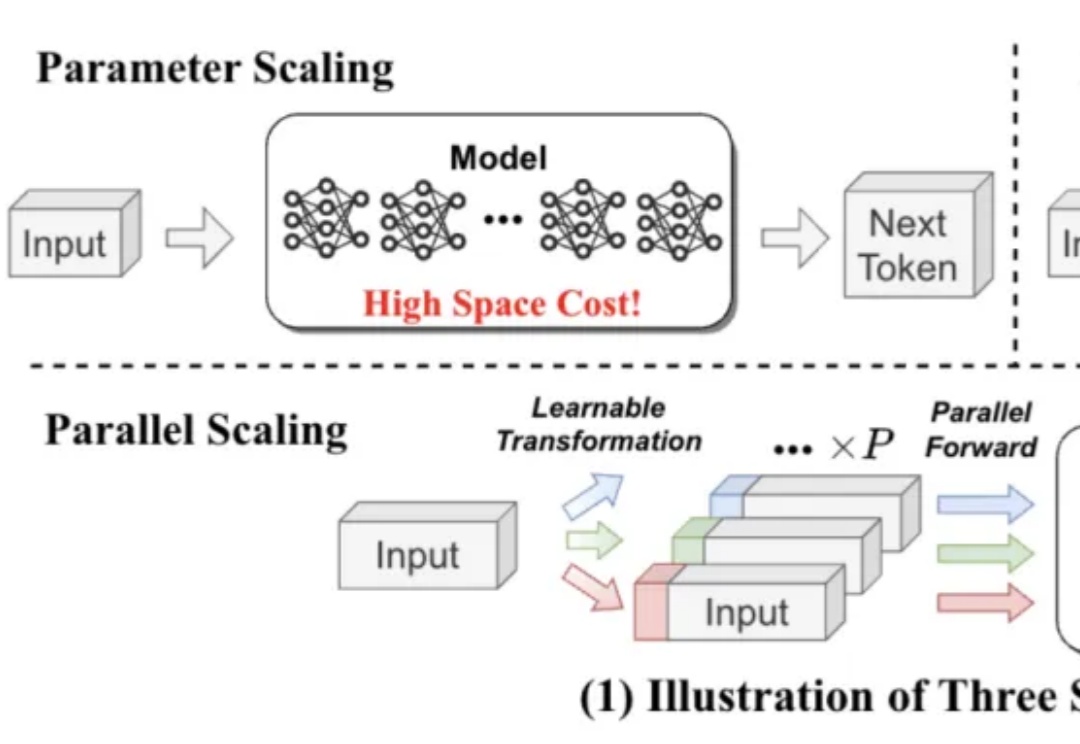
既能提升模型能力,又不显著增加内存和时间成本,LLM第三种Scaling Law被提出了。
Mistral沉默好久,果然在憋大招。
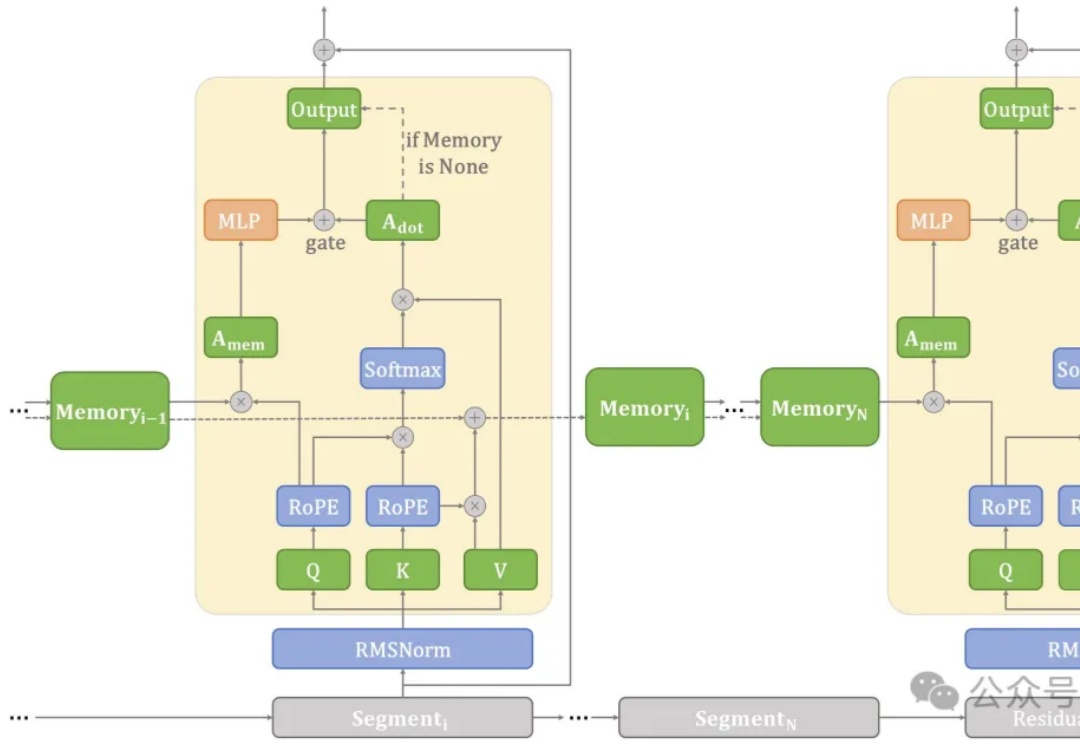
在端侧设备上处理长文本常常面临计算和内存瓶颈。

英伟达官宣新办公室落户中国台湾省台北市,但居然是从太空飞下来的吗?

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
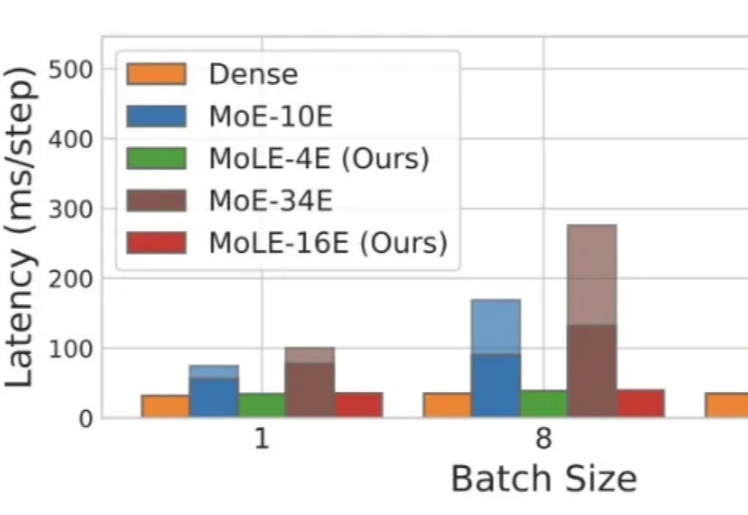
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。