
仅需0.4GB,参数只有0和±1!微软开源首个原生1 bit模型,CPU轻松跑
仅需0.4GB,参数只有0和±1!微软开源首个原生1 bit模型,CPU轻松跑微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。
来自主题: AI技术研报
8296 点击 2025-04-20 21:12
 搜索
搜索
微软研究院开源的原生1bit大模型BitNet b1.58 2B4T,将低精度与高效能结合,开创了AI轻量化的新纪元。通过精心设计的推理框架,BitNet不仅突破了内存的限制,还在多项基准测试中表现出色,甚至与全精度模型不相上下。

3月末,多家海外存储头部企业,宣布从4月起提高部分产品报价,国内厂商也随之上调价格,终结了DRAM内存与NAND闪存的降价势头。

在大模型争霸的时代,算力与效率的平衡成为决定胜负的关键。

通过完全启用并发多块执行,支持任意专家数量(MAX_EXPERT_NUMBER==256),并积极利用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被精心设计,实现了显著的性能提升:A100提升3倍,H200提升3倍,MI100提升10倍,MI300X/MI300A提升7倍...

大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。
DeepSeek MoE“变体”来了,200美元以内,内存需求减少17.6-42%! 名叫CoE(Chain-of-Experts),被认为是一种“免费午餐”优化方法,突破了MoE并行独立处理token、整体参数数量较大需要大量内存资源的局限。
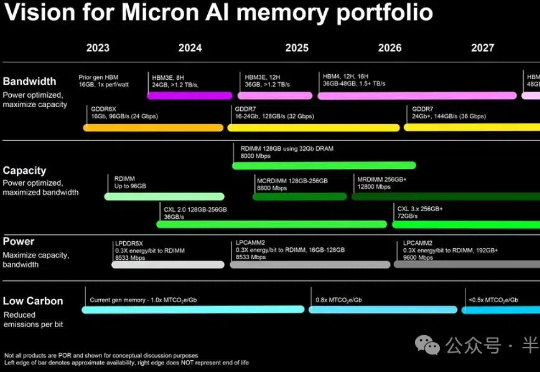
2月26日,美光宣布已率先向生态系统合作伙伴及特定客户出货专为下一代CPU设计的 1γ(1-gamma) 第六代 (10纳米级) DRAM节点DDR5内存样品。
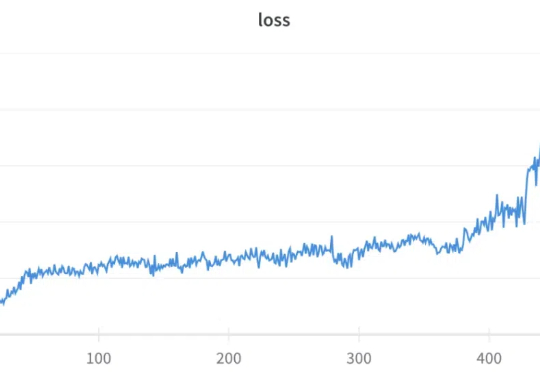
GRPO(Group Relative Policy Optimization)是 DeepSeek-R1 成功的基础技术之一,我们之前也多次报道过该技术,比如《DeepSeek 用的 GRPO 占用大量内存?有人给出了些破解方法》。
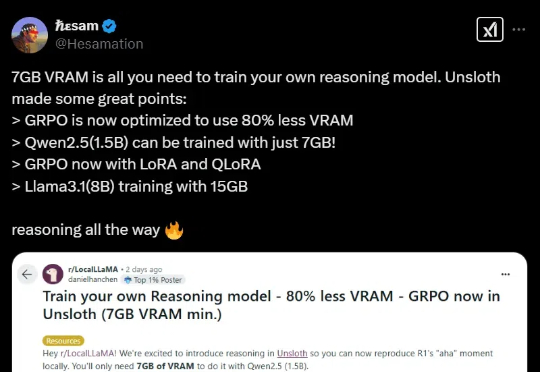
黑科技来了!开源LLM微调神器Unsloth近期更新,将GRPO训练的内存使用减少了80%!只需7GB VRAM,本地就能体验AI「啊哈时刻」。
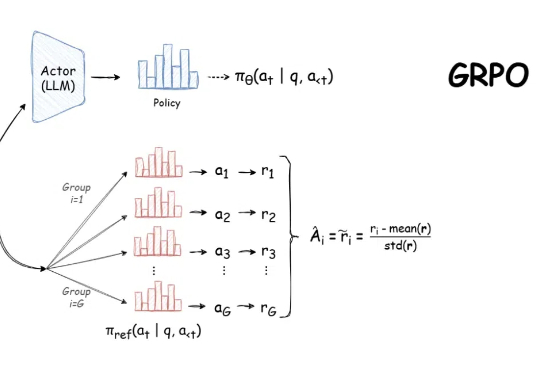
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。