人大高瓴-华为诺亚:大语言模型智能体记忆机制的系列研究
人大高瓴-华为诺亚:大语言模型智能体记忆机制的系列研究近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。
来自主题: AI技术研报
8160 点击 2025-08-07 17:03
 搜索
搜索
近期,基于大语言模型的智能体(LLM-based agent)在学术界和工业界中引起了广泛关注。对于智能体而言,记忆(Memory)是其中的重要能力,承担了记录过往信息和外部知识的功能,对于提高智能体的个性化等能力至关重要。
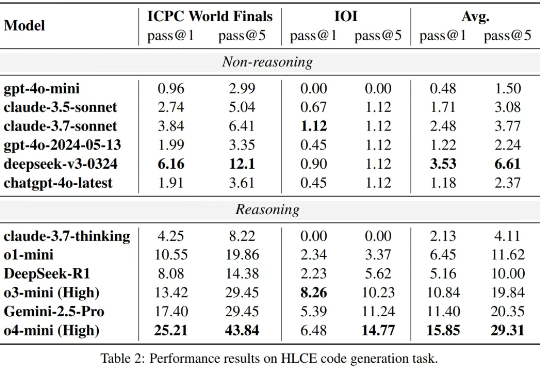
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
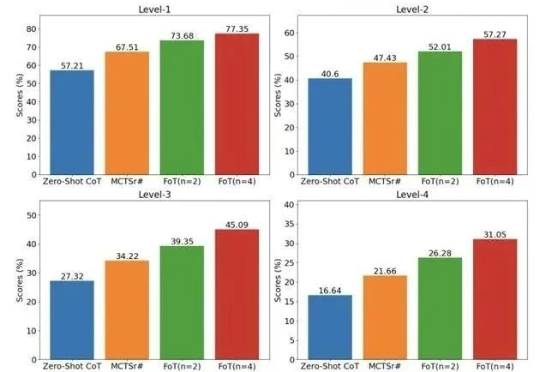
大模型越来越大,通用能力越来越强,但一遇到数学、科学、逻辑这类复杂问题,还是常“翻车”。为破解这一痛点,华为诺亚方舟实验室提出全新高阶推理框架 ——思维森林(Forest-of-Thought,FoT)。
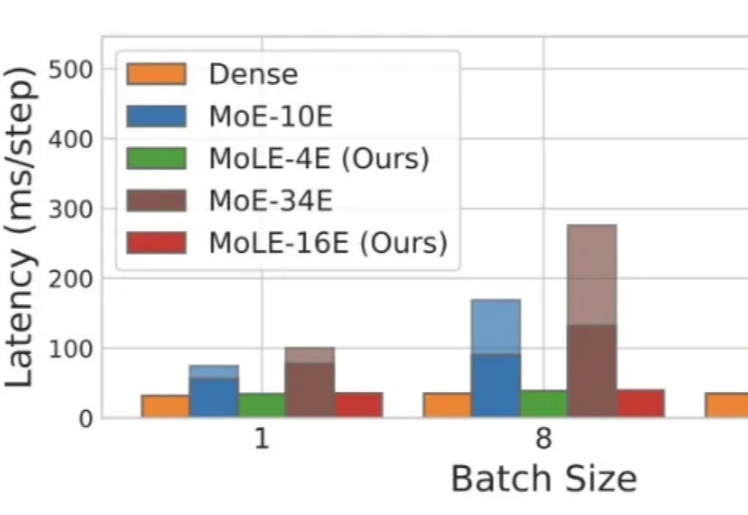
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
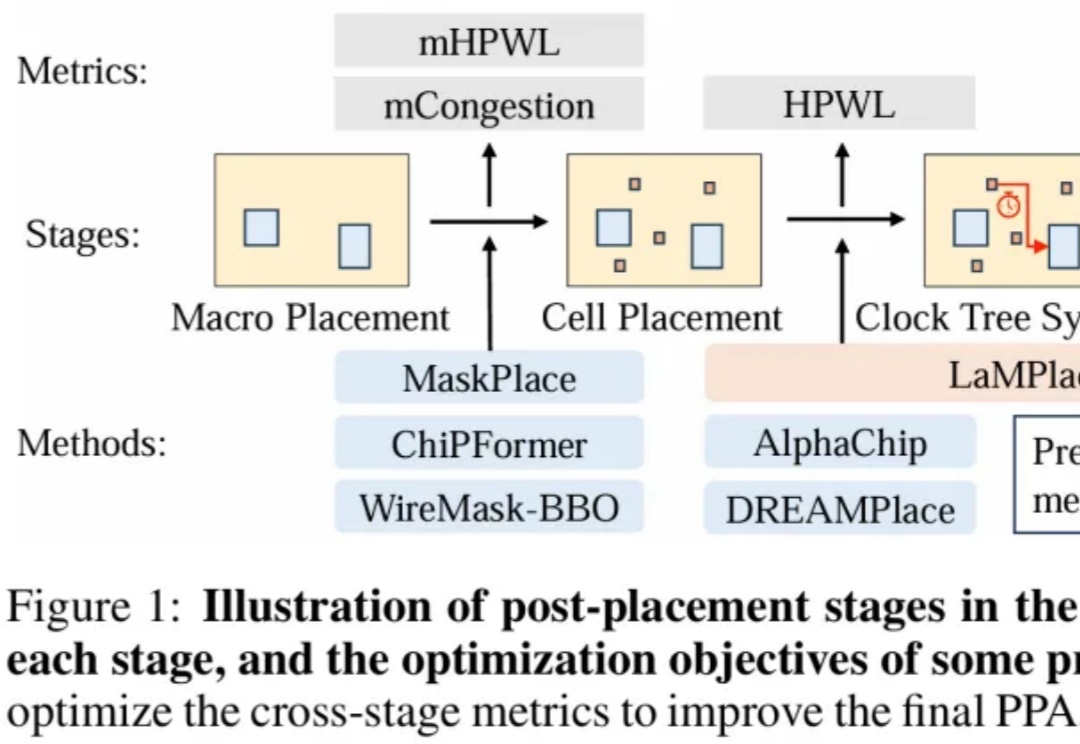
用AI指导芯片设计,中科大王杰教授团队、华为诺亚实验室、天津大学提出全新芯片宏单元布局优化方法LaMPlace!
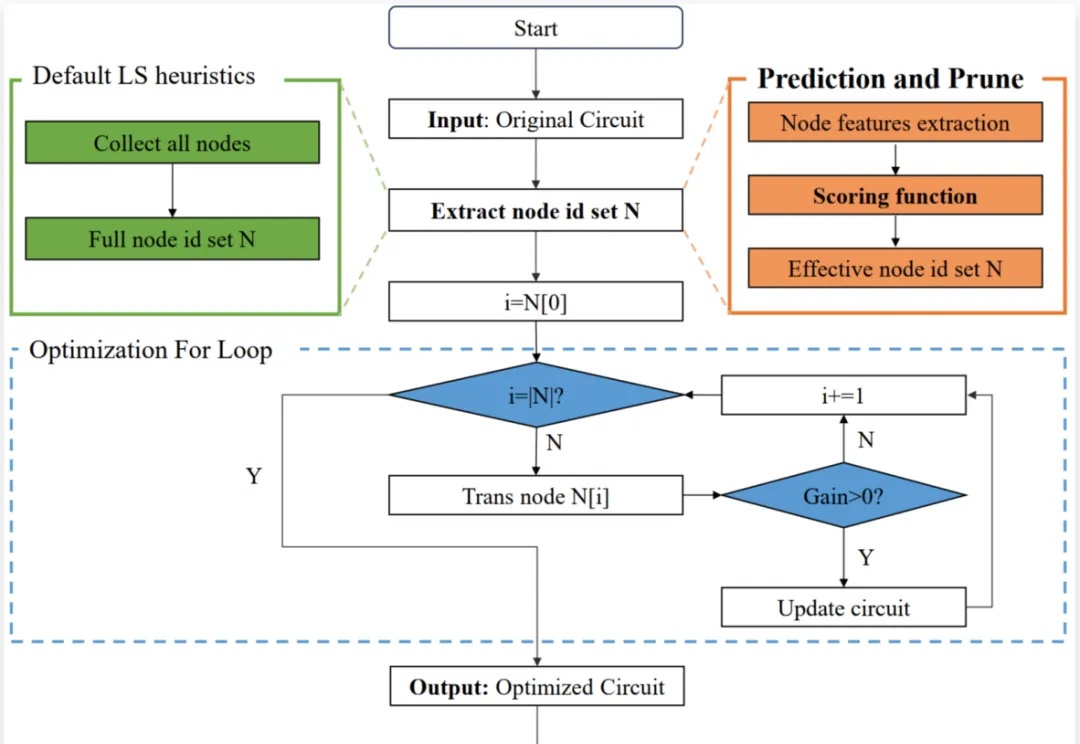
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
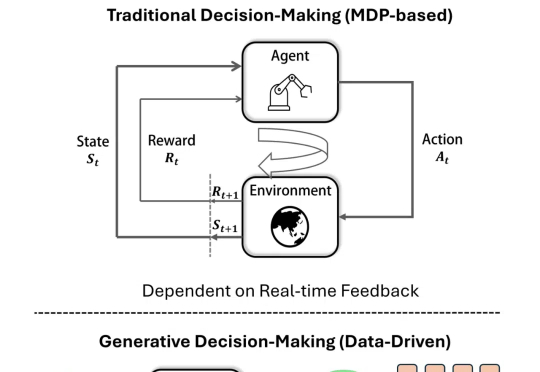
近年来,生成模型在内容生成(AIGC)领域蓬勃发展,同时也逐渐引起了在智能决策中的应用关注。

国内芯片设计研究团队,刚刚在国际学术顶会上获奖了。
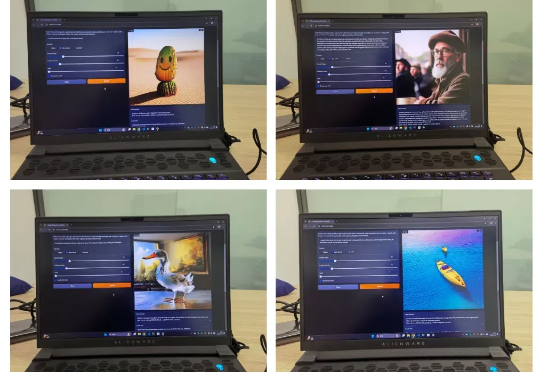
香港大学联合上海人工智能实验室,华为诺亚方舟实验室提出高效扩散模型 LiT:探索了扩散模型中极简线性注意力的架构设计和训练策略。LiT-0.6B 可以在断网状态,离线部署在 Windows 笔记本电脑上,遵循用户指令快速生成 1K 分辨率逼真图片。
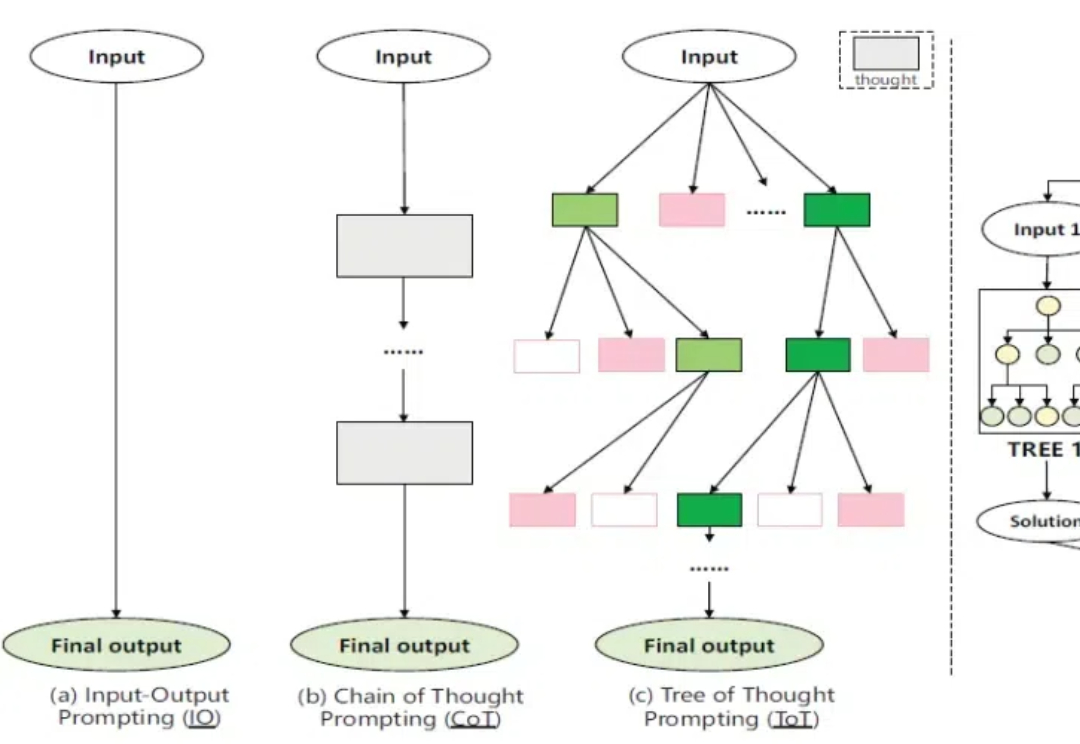
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。