
短剧里的AI,和被AI压缩的人
短剧里的AI,和被AI压缩的人“再来一条,情绪得跟上AI 给的节奏。”
来自主题: AI资讯
8480 点击 2025-07-15 15:41
 搜索
搜索
“再来一条,情绪得跟上AI 给的节奏。”
当产品团队还在为等待 4-6 周的 A/B 测试结果而焦虑时,一家名为 Blok 的初创公司正在用 AI 虚拟用户彻底颠覆这一传统模式。他们让产品测试从"weeks"压缩到"hours",从"reactive"转向"predictive",这不仅仅是效率的提升,更是产品开发哲学的根本性变革。
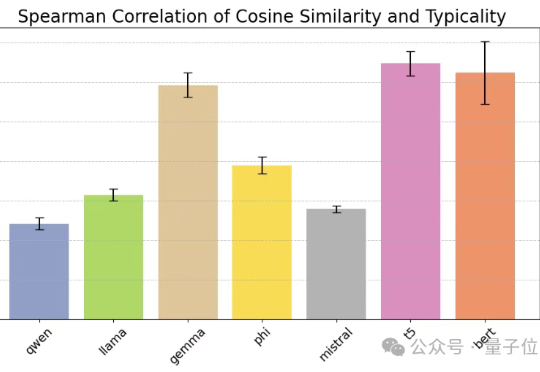
那问题来了:大型语言模型(LLM)虽然语言能力惊人,但它们在语义压缩方面能做出和人类一样的权衡吗?为探讨这一问题,图灵奖得主LeCun团队,提出了一种全新的信息论框架。该框架通过对比人类与LLM在语义压缩中的策略,揭示了两者在压缩效率与语义保真之间的根本差异:LLM偏向极致的统计压缩,而人类更重细节与语境。

Legora从观察律师朋友被"thankless tasks"拖累的痛苦中诞生,通过"真正合作伙伴"而非单纯工具的协作理念,解决了传统法律研究低效问题——AI可为律师每周节省4小时、年增10万美元计费时间,目前已服务250家顶级律所实现数据室审查从数周压缩至数小时。
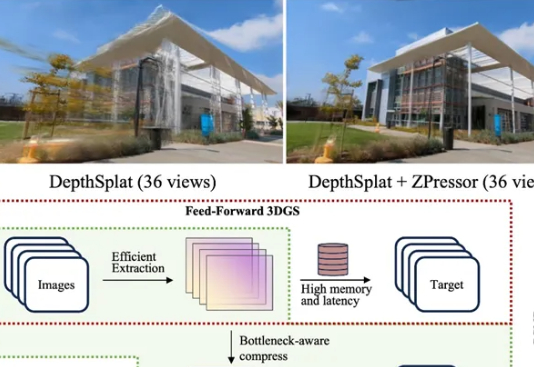
ZPressor能高效压缩3D高斯泼溅(3DGS)模型的多视图输入,解决其在处理密集视图时的性能瓶颈,提升渲染效率和质量。

地铁站,老人方言购票秒出;医院里,医生病历书写时间压缩至1h。这家深耕AI的先锋长跑13年,如今即将叩响港交所大门。这条路没有捷径,只是把「人的需求」作为终点,或许这才是AI最本真的温度。

在金融科技智能化转型进程中,大语言模型以及多模态大模型(LVLM)正成为核心技术驱动力。尽管 LVLM 展现出卓越的跨模态认知能力
西班牙初创公司 Multiverse Computing 于 6 月 12 日宣布 ,凭借其名为"CompactifAI"的技术优势,已完成 1.89 亿欧元(约合 2.15 亿美元)的巨额 B 轮融资。本轮B 轮融资由 Bullhound Capital 领投,该机构曾投资过 Spotify、Revolut、Delivery Hero、Avito 和 Discord 等企业

AI数据标注师职业呈分层现象(体力型、理解型、管理型),虽处行业需求增长期,但面临廉价、技术壁垒低、易被AI替代的困境。从业者普遍缺乏上升通道与核心竞争力,大厂战略转向落地应用进一步压缩基础标注岗位,凸显个人主动转型的重要性。

小扎亲手挖人,很疯狂。