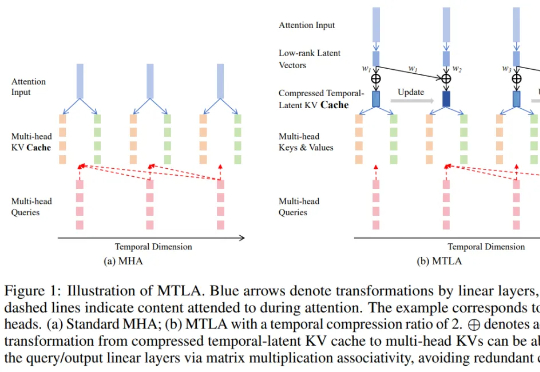
时空压缩!剑桥大学提出注意力机制MTLA:推理加速5倍,显存减至1/8
时空压缩!剑桥大学提出注意力机制MTLA:推理加速5倍,显存减至1/8在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点
来自主题: AI技术研报
9541 点击 2025-06-11 11:43
 搜索
搜索
在大语言模型蓬勃发展的背景下,Transformer 架构依然是不可替代的核心组件。尽管其自注意力机制存在计算复杂度为二次方的问题,成为众多研究试图突破的重点

本文第一作者为前阿里巴巴达摩院高级技术专家,现一年级博士研究生满远斌,研究方向为高效多模态大模型推理和生成系统。通信作者为第一作者的导师,UTA 计算机系助理教授尹淼。尹淼博士目前带领 7 人的研究团队,主要研究方向为多模态空间智能系统,致力于通过软件和系统的联合优化设计实现空间人工智能的落地。

World Labs 是由著名 AI 专家、斯坦福大学教授李飞飞于 2024 年创办的初创公司,致力于开发具备“空间智能”的下一代 AI 系统。

AI正被妈妈们用于辅导孩子作业,尤其是代写作文,以应对学校刻板命题和格式要求。家长认为作文缺乏意义,AI能高效生成应试模板,甚至老师也使用AI批改,形成“AI写-AI批”闭环。这虽减轻了家长负担,却让孩子过早学会应付规则,真实表达空间被压缩,引发对教育意义和童年消逝的反思。
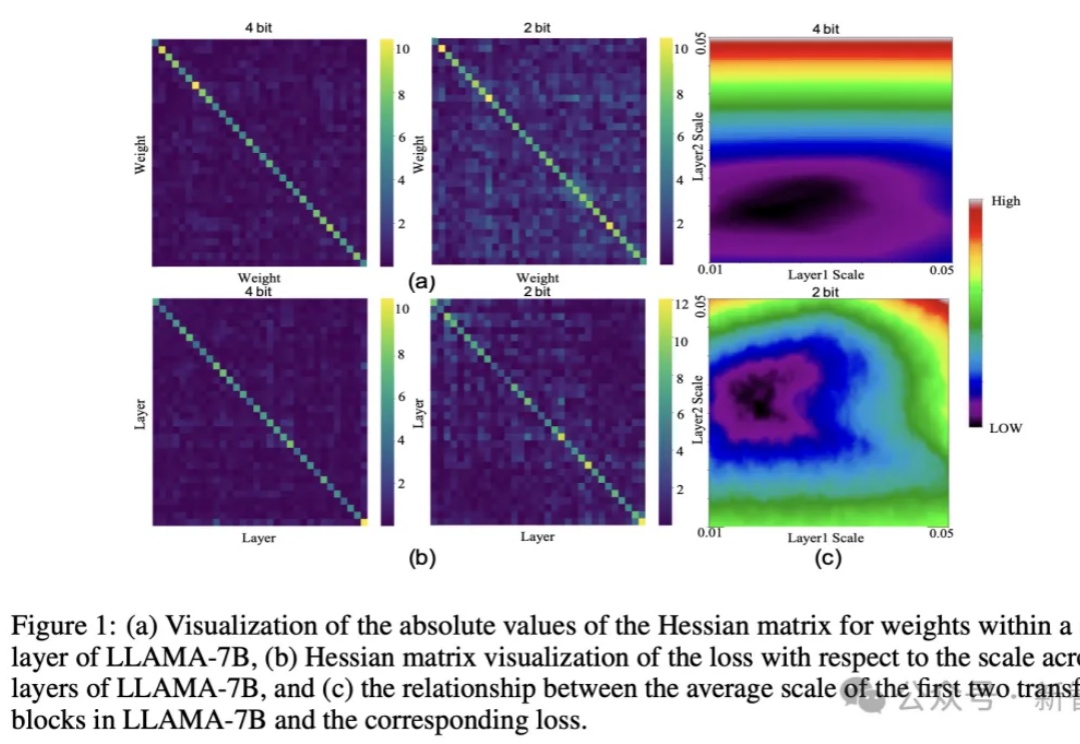
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。

继“结构式”“压缩式”“共振式”之后,一直在想第四种与 AI 交流的路,可能会是什么?
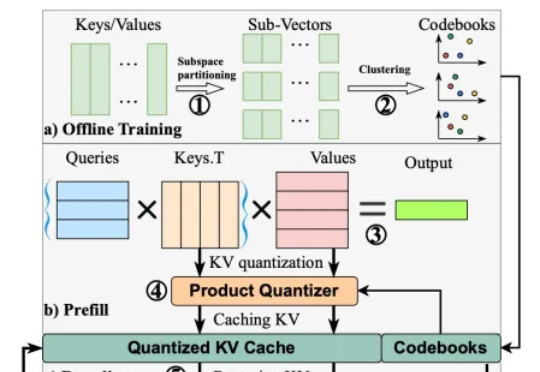
在以 transformer 模型为基础的大模型中,键值缓存虽然用以存代算的思想显著加速了推理速度,但在长上下文场景中成为了存储瓶颈。为此,本文的研究者提出了 MILLION,一种基于乘积量化的键值缓存压缩和推理加速设计。
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。

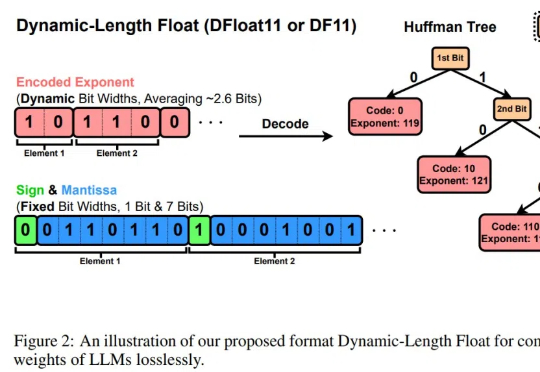
LLM的规模爆炸式增长,传统量化技术虽能压缩模型,却以牺牲精度为代价。莱斯大学团队的最新研究DFloat11打破这一僵局:它将模型压缩30%且输出与原始模型逐位一致!更惊艳的是,通过针对GPU的定制化解压缩内核,DFloat11使推理吞吐量提升最高38.8倍。