5天连更5次,可灵AI年末“狂飙式”升级
5天连更5次,可灵AI年末“狂飙式”升级12月伊始,可灵AI接连放出大招。全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能……5天内5次“上新”,直接让生成式AI领域的竞争“卷”出新高度。
来自主题: AI资讯
8073 点击 2025-12-10 14:32
 搜索
搜索
12月伊始,可灵AI接连放出大招。全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能……5天内5次“上新”,直接让生成式AI领域的竞争“卷”出新高度。

左下角的血条、右下角的小地图,还有这一连串丝滑的跑酷动作…… 看到这个画面,你是不是以为《疯狂动物城2》这边刚拿下中国影史进口动画片票房第一,那边就趁势要推出 3A 开放世界游戏了?甚至这光影和物理碰撞,比很多大厂的游戏都要真实。

ChatGPT发布三周年,OpenAI没发布,各大AI玩家倒纷纷整出大活。
昨晚,AI视频领域,终于来了一点新东西。

今天,来自快手可灵团队和香港城市大学的研究者们,正在尝试打破这一界限。他们提出了一个全新的任务范式——「视频作为答案」,并发布了相应模型VANS。而这项工作则开创性地提出了Video-Next Event Prediction任务,要求模型直接生成一段动态视频作为回答。
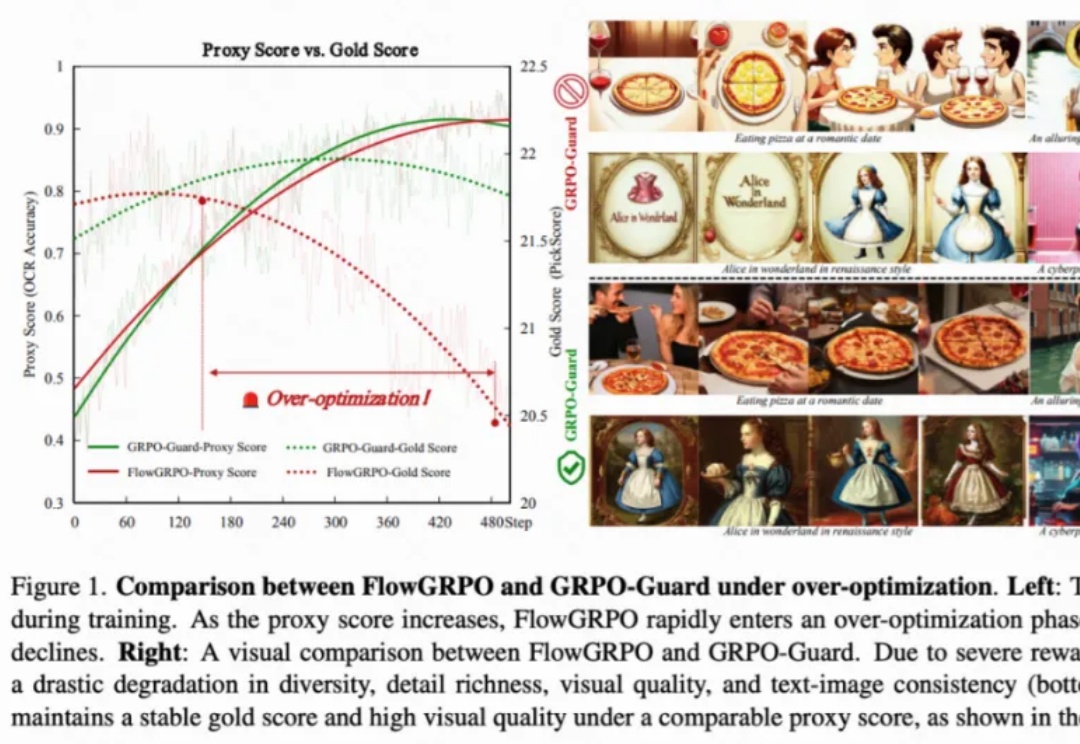
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
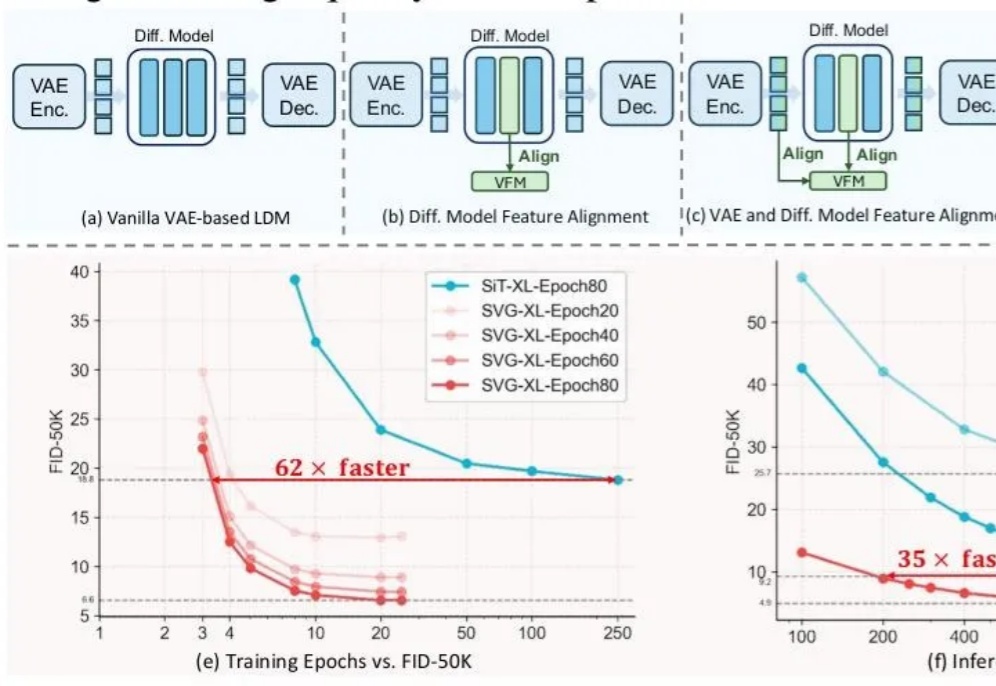
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。

长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练
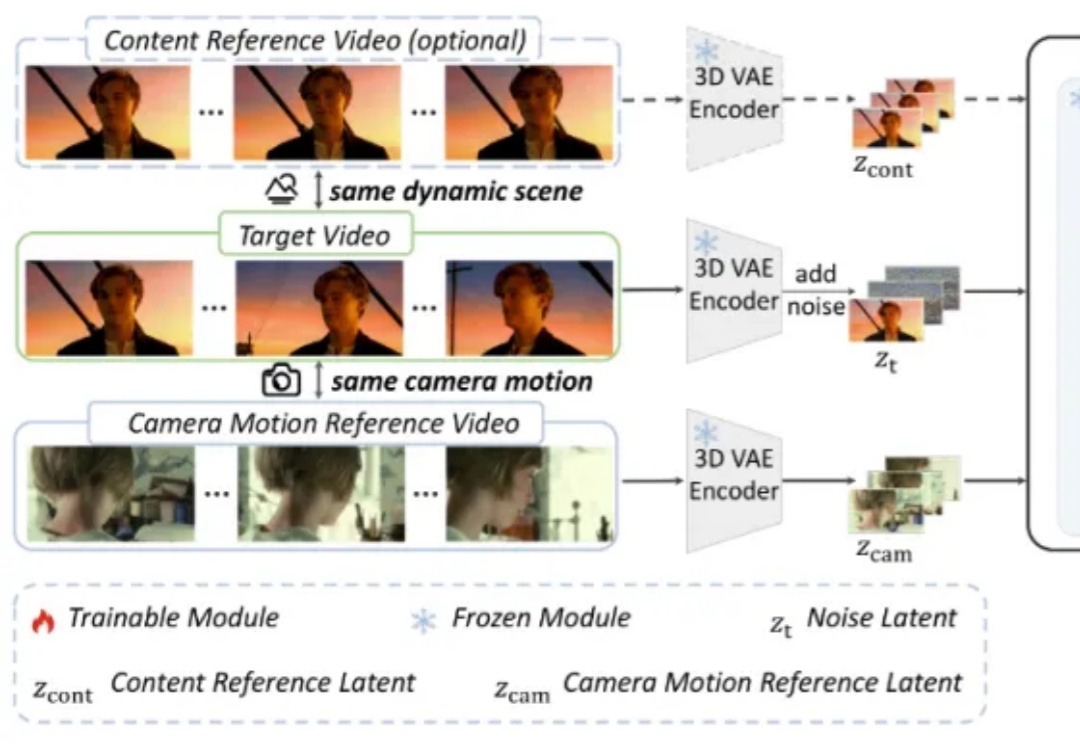
作为视频创作者,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜?

最近,两条消息同时刷屏:先是 9 月 23 日快手宣布其可灵 2.5 Turbo 图生/文生视频模型,推出 10 天后,即在 Artificial Analysis 上成为世界第一;紧接着,腾讯也宣布混元图像 3.0 模型在 LMArena 上成为世界第一。