
让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好
让大模型不再过度思考!上海AI Lab后训练新范式重塑CoT,推理又快又好近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:
来自主题: AI技术研报
7596 点击 2025-12-21 12:35
近日,上海人工智能实验室的研究团队提出了一种全新的后训练范式——RePro(Rectifying Process-level Reward)。这篇论文将推理的过程视为模型内部状态的优化过程,从而对如何重塑大模型的CoT提供了一个全新视角:

VLA模型性能暴涨300%,背后训练数据还首次实现90%由世界模型生成。

中国最早进行医疗大模型后训练的创新企业之一 ——杭州全诊医学科技有限公司(以下简称“全诊医学”)正式宣布完成1亿元B轮融资:2024年4季度由A股上市公司“创新医疗”(SZ.002173)完成战略轮投资;2025年2季度由中国医药工业百强“好医生集团”完成B轮投资,探针资本担任本轮融资的独家财务顾问。
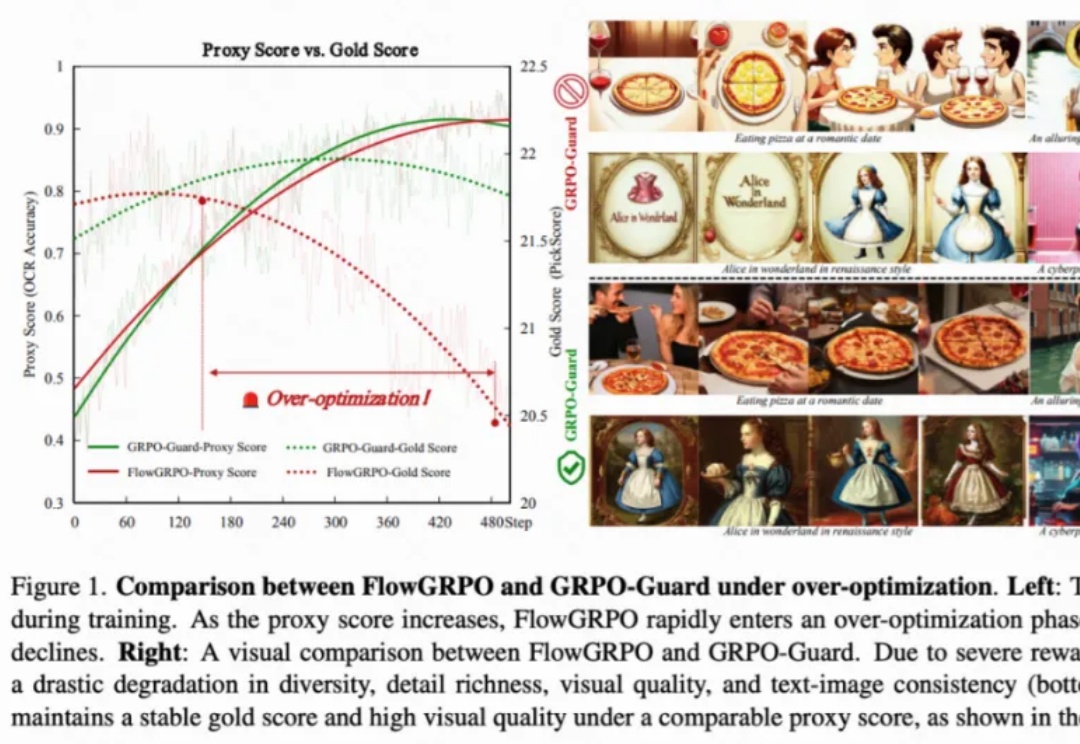
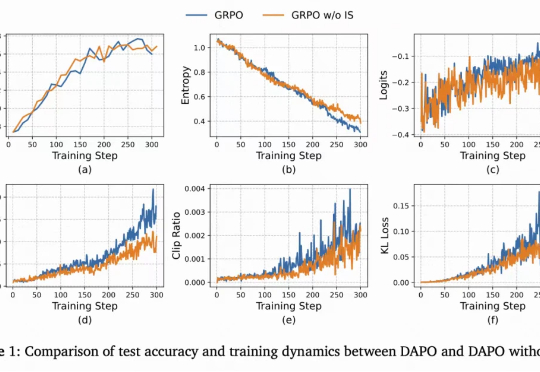
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。

今年三月,Liam Fedus 在推特上宣布离开 OpenAI。这条推文的影响力超出了所有人的预期——硅谷的风投们几乎是立刻行动起来,争相联系这位 ChatGPT 最初小团队的核心成员、曾领导 OpenAI 关键的后训练部门的研究者,他的离职甚至一度引发了一场“反向竞标”。

预训练的核心是推动损失函数下降,这是我们一直追求的唯一目标。
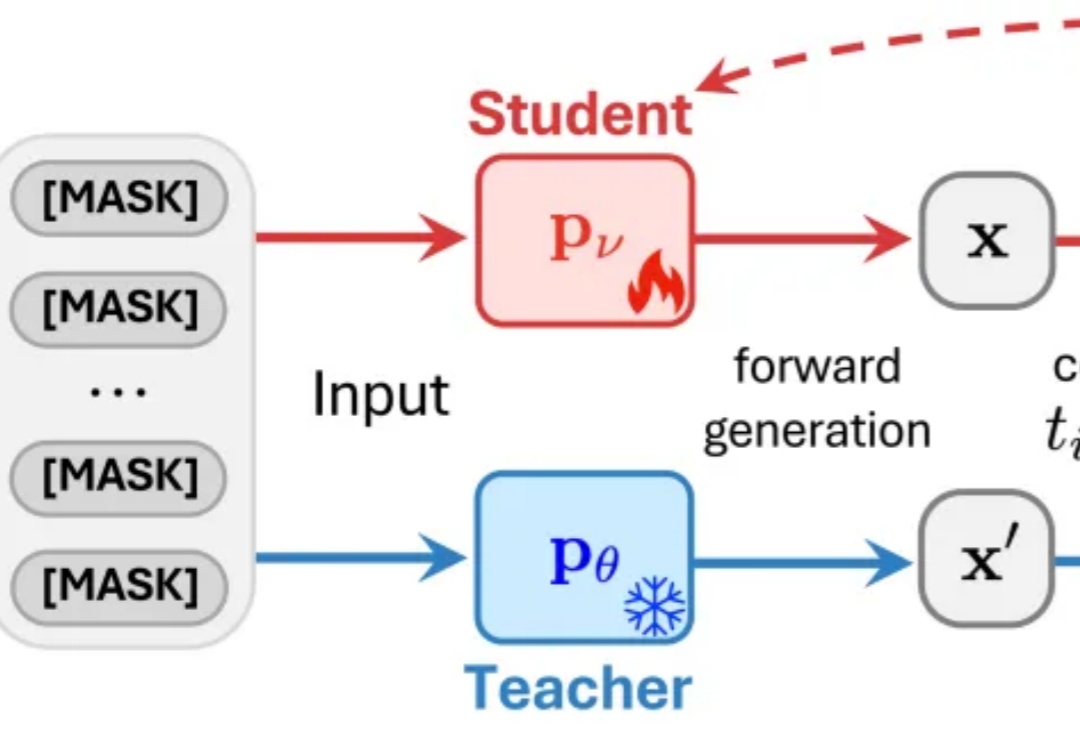
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。
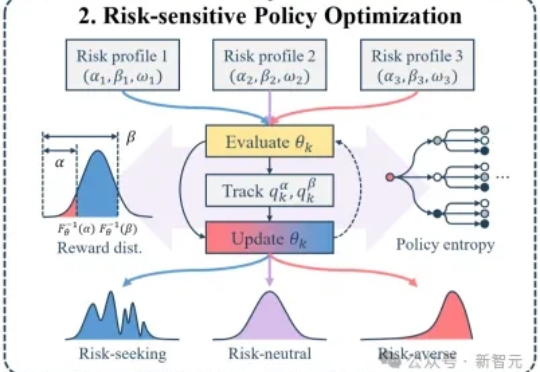
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。

强化学习能力强大,几乎已经成为推理模型训练流程中的标配,也有不少研究者在探索强化学习可以为大模型带来哪些涌现行为。
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。