一句话生成无限逼真3D场景!匹兹堡大学新作直击VLM空间推理软肋丨CVPR'26
一句话生成无限逼真3D场景!匹兹堡大学新作直击VLM空间推理软肋丨CVPR'26VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
来自主题: AI技术研报
6484 点击 2026-04-08 09:15
 搜索
搜索
VLM看图像描述头头是道,一遇到3D空间推理就“晕菜”。
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。
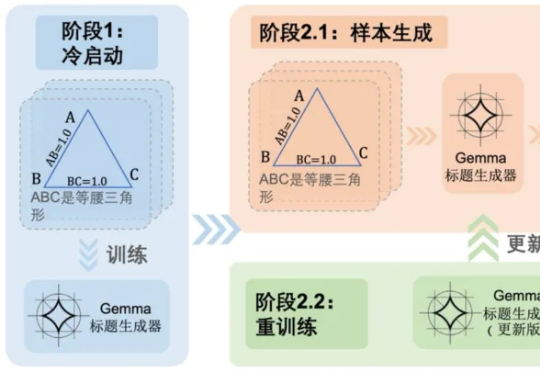
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。 然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视
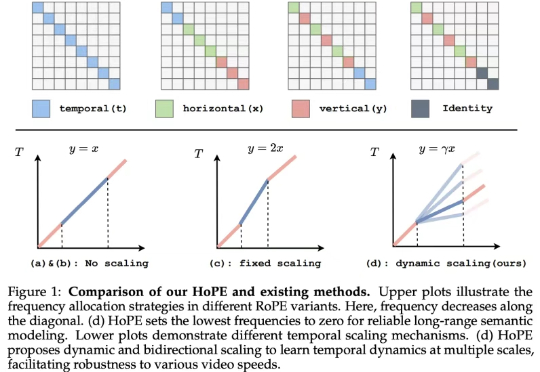
如今的视觉语言模型 (VLM, Vision Language Models) 已经在视觉问答、图像描述等多模态任务上取得了卓越的表现。然而,它们在长视频理解和检索等长上下文任务中仍表现不佳。

视觉价值模型(VisVM)通过「推理时搜索」来提升多模态视觉语言模型的图像描述质量,减少幻觉现象。实验表明,VisVM能显著提高模型的视觉理解能力,并可通过自我训练进一步提升性能。
PaliGemma 2在多个任务上取得了业界领先的成绩,包括图像描述、乐谱识别和医学图像报告生成;并且提供了不同尺寸和分辨率的版本,用户可以根据不同的任务需求进行微调,以获得更好的性能。
Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。

在当今的多模态大模型的发展中,模型的性能和训练数据的质量关系十分紧密,可以说是 “数据赋予了模型的绝大多数能力”。
一款名为Vary-toy的“年轻人的第一个多模态大模型”来了!模型大小不到2B,消费级显卡可训练,GTX1080ti 8G的老显卡轻松运行。