美团视频生成模型来了!一出手就是开源SOTA
美团视频生成模型来了!一出手就是开源SOTA美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。
来自主题: AI资讯
10909 点击 2025-10-27 17:35
 搜索
搜索
美团,你是跨界上瘾了是吧!(doge)没错,最新开源SOTA视频模型,又是来自这家“送外卖”的公司。模型名为LongCat-Video,参数13.6B,支持文生/图生视频,视频时长可达数分钟。

AI视频领域杀疯了! 发布Vidu Q2图生视频不到2周,Vidu又又又更新了,而且直接甩出三张王牌。 首先是AI创作者们等待良久的Vidu Q2参考生功能终于要正式发布了。此外,Vidu视频延长功能一来就亮绝杀,最高可延长至五分钟。

正如前几天网上泄露与传闻所预料的那样,深夜,谷歌发布了最新的 AI 视频生成模型 Veo 3.1。Veo 3.1 带来了更丰富的音频、叙事控制,以及更逼真的质感还原。在 Veo 3 的基础上,Veo 3.1 进一步提升了提示词遵循度,并在以图生视频时提供更高的视听质量。

9 月 25 日,生数科技新一代图生视频大模型 Vidu Q2 正式全球上线,打破了原有 AI 生成的表情太假,动作飘忽不定,运动幅度不够大,无法指哪打哪的行业问题,实现从 “视频生成” 到 “演技生成”,从 “动态流畅” 到 “情感表达” 的革命性跨越,标志着 AI 视频生成技术正式从追求 “形似” 进入追求 “神似” 的新纪元

好玩好用的明星视频生成产品再更新,用户操作基础,模型技术就不基础。

5月9日,京西智谷潭柘智空基座大模型体系及应用平台建设项目开标,北京智谱清言科技有限公司中标,金额6400万元。根据此前公开的采购公告,本项目招标范围是:文生图片平台、图生视频与视频生视频平台、汉藏平台、多语种平台、AI数字人与垂类大模型对接平台、集成总平台等。
“史上最强视觉生成模型”,现在属于快手。一基双子的可灵AI基础模型——文/图生图的可图、文/图生视频的可灵,都重磅升级到2.0版本。可图2.0,对比MidJourney 7.0,胜负比「(good+same) / (same+bad)」超300%,对比FLUX超过150%;
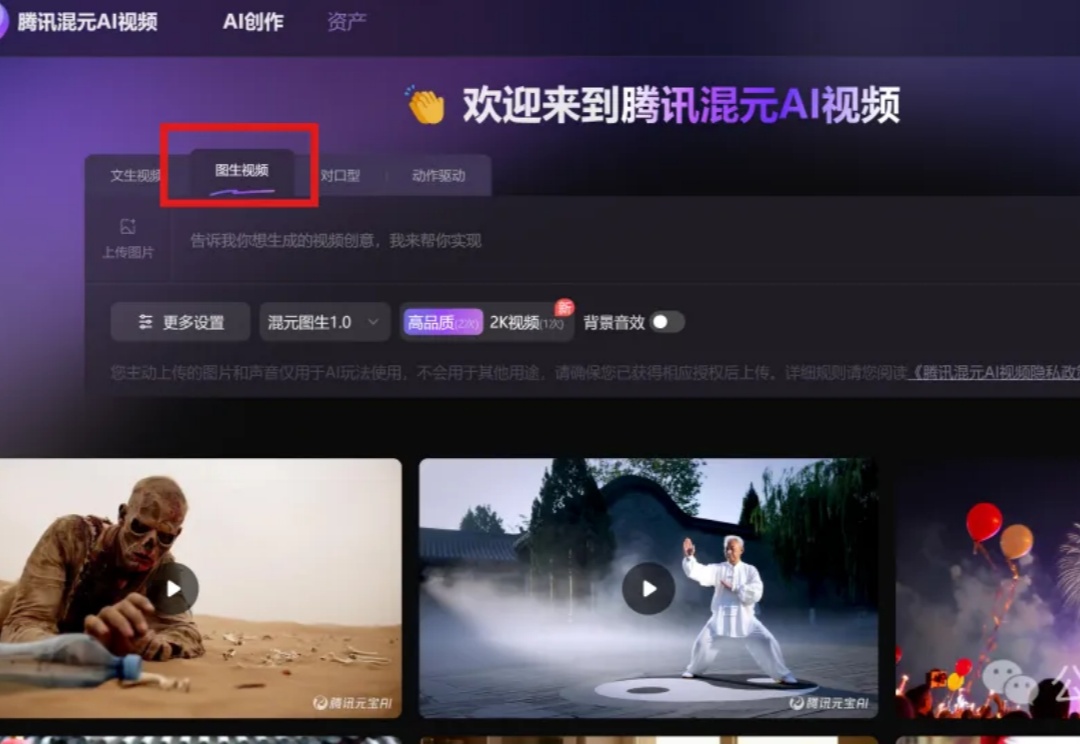
就在刚刚,腾讯版Sora补齐了又一重要拼图——图生视频。

进入到 2025 年,视频生成(尤其是基于扩散模型)领域还在不断地「推陈出新」,各种文生视频、图生视频模型展现出了酷炫的效果。其中,长视频生成一直是现有视频扩散的痛点。

这两年,大模型作为前沿技术,正逐步深入电商行业的各个环节。 2025,这一变革仍在加速:近日,【淘宝星辰 · 图生视频】工具已重磅上线,并对淘宝天猫商家正式开放!