龙虾冲浪终于不迷路了!网页智能体新框架Avenir-Web开源即SOTA
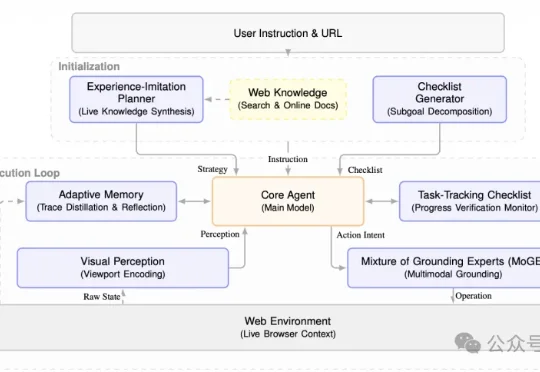
龙虾冲浪终于不迷路了!网页智能体新框架Avenir-Web开源即SOTA伦敦大学学院(UCL)、普林斯顿大学和爱丁堡大学的研究团队联合推出了Avenir-Web,让现有多模态模型像人类一样使用网页。现有的Web Agent在面对复杂的网页结构(如 iframe、Shadow DOM)时,往往会陷入“定位不准”“缺乏常识”或“走着走着就忘了”的窘境。
来自主题: AI技术研报
8812 点击 2026-04-30 08:32