上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型
上海交大DENG Lab提出「LatentUM」:Unified Model的真正「战场」在视觉推理与世界模型过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。
来自主题: AI技术研报
8891 点击 2026-04-14 08:42
 搜索
搜索
过去一段时间,生成理解统一模型(Unified Model)经常被理解成一种「既能看懂图、又能生成图」的多模态通用系统。

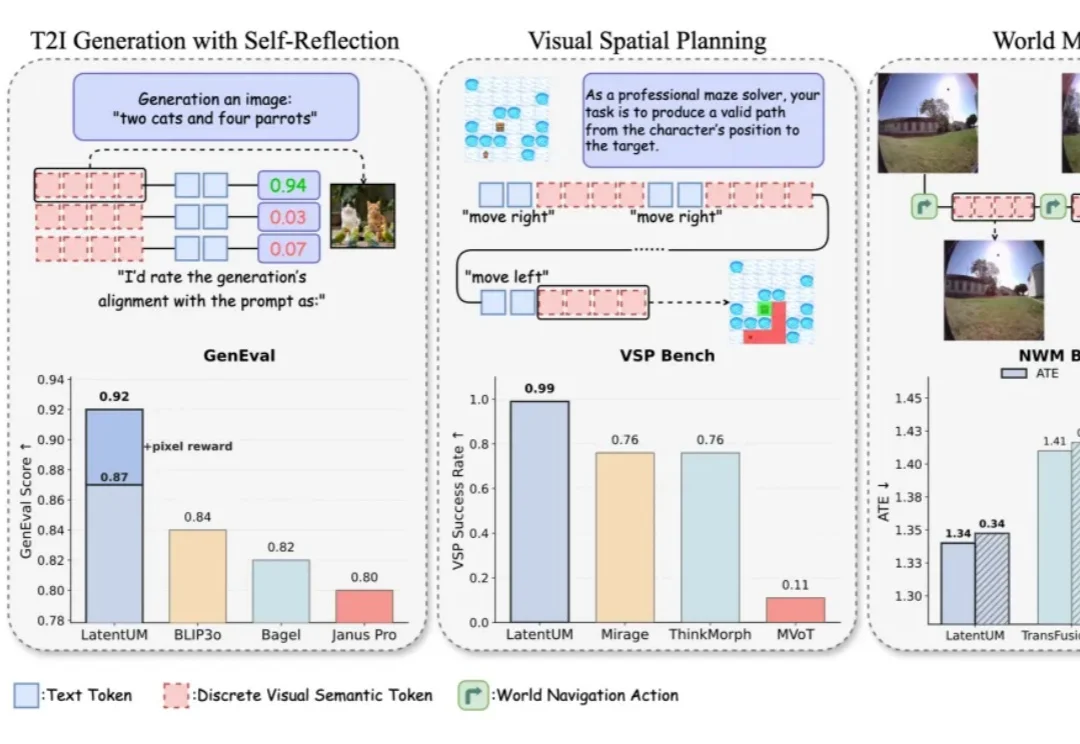
近日,上海人工智能实验室联合南京大学、香港中文大学及上海交通大学,将OpenClaw的成功应用于多模态生成领域。他们提出GEMS(Agent-Native Multimodal Generation with Memory and Skills),激发小模型潜力,甚至让6B小模型在部分任务超越了Nano Banana 2。
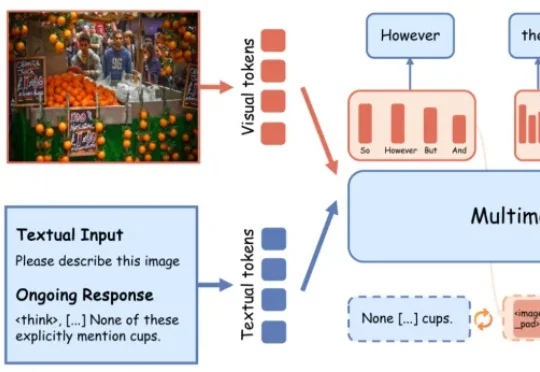
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。
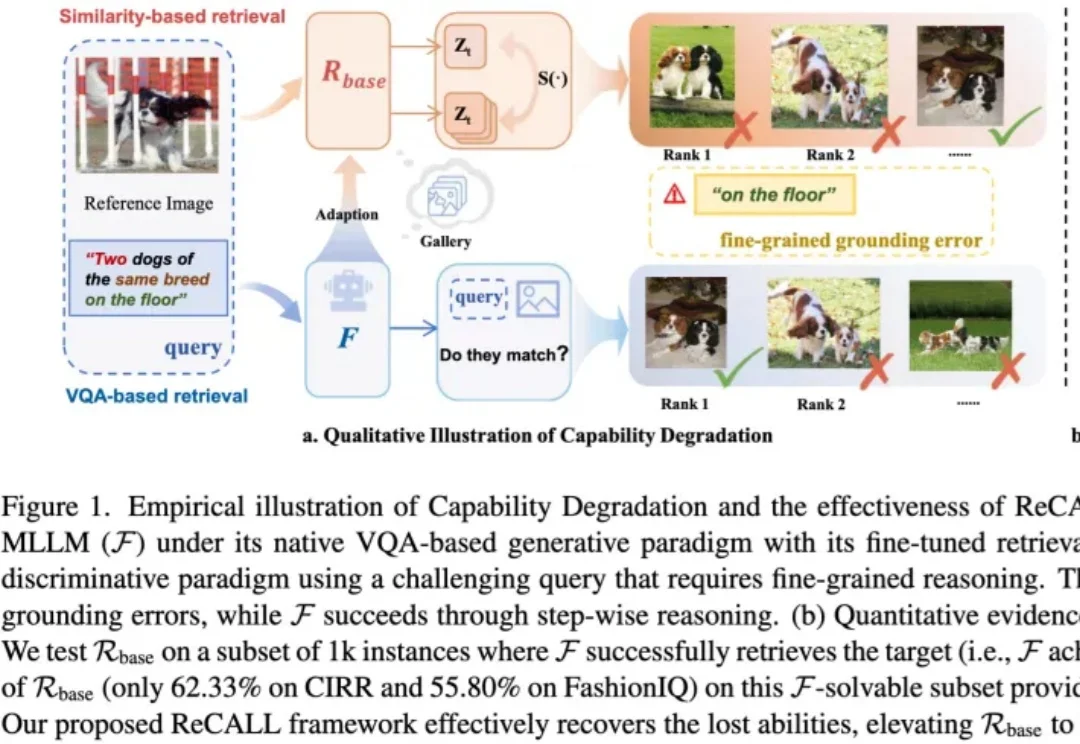
生成式模型当检索器大材小用效果还不好?
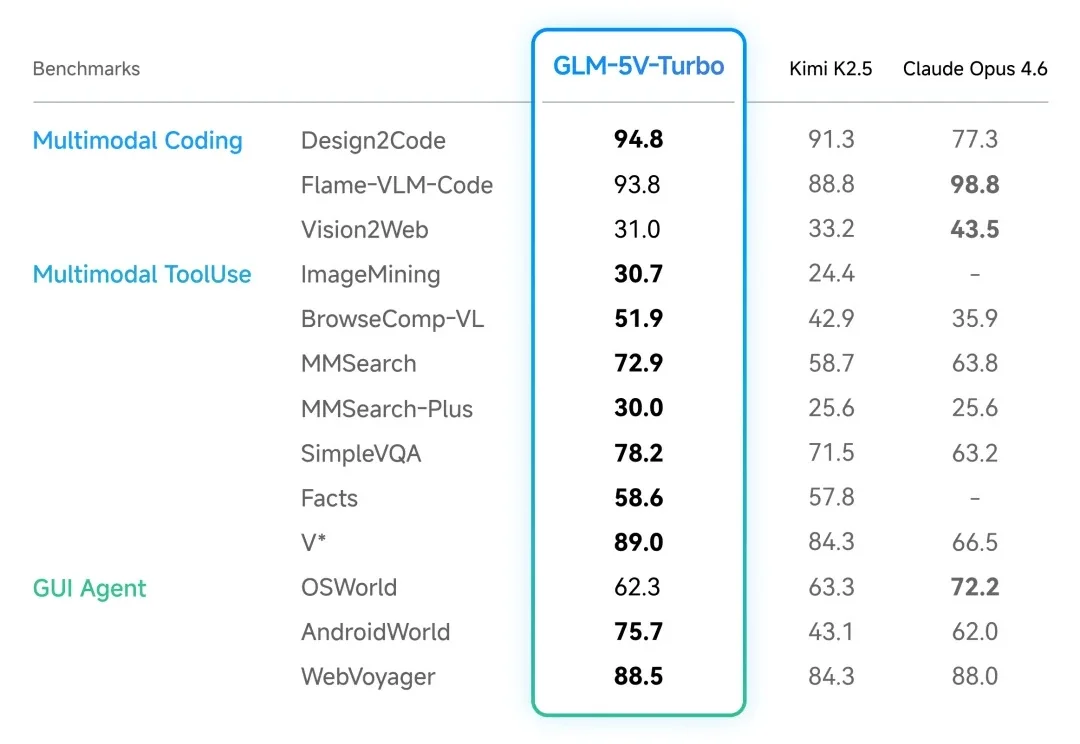
今天,智谱发布 GLM-5V-Turbo,定位「面向视觉编程的多模态 Coding 基座模型」。一句话概括:在 GLM-5-Turbo 的编程和龙虾能力基座上,加入了原生的视觉理解和推理能力
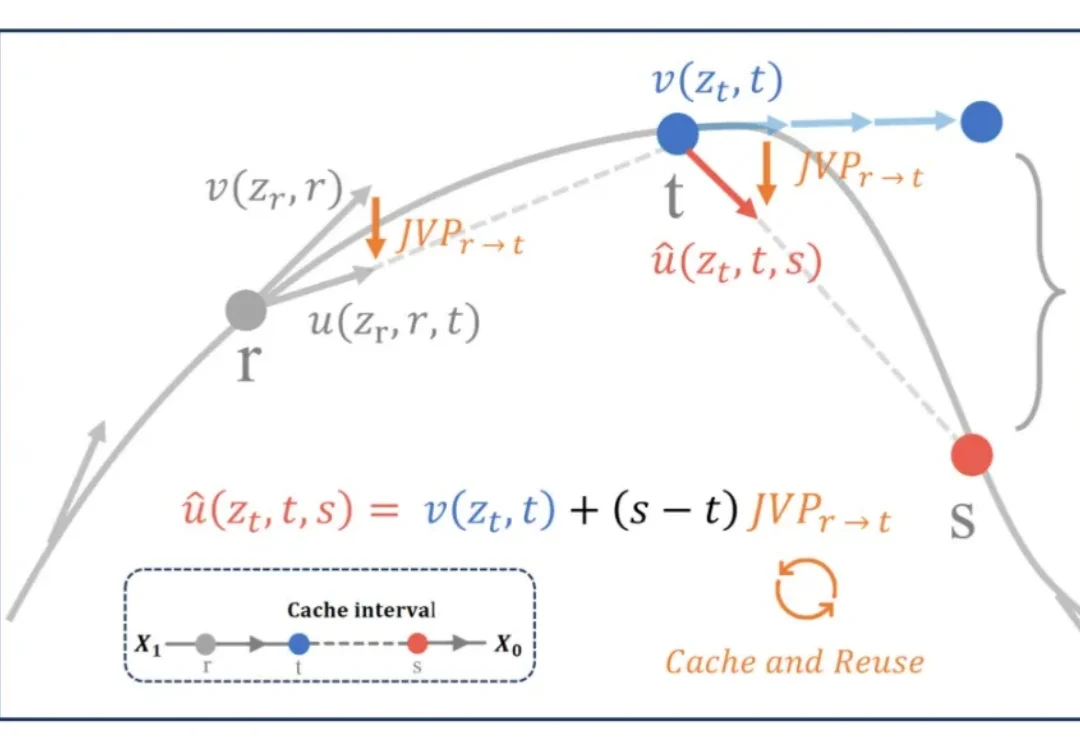
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。

林俊旸离职了,但 Qwen 不能停。最近 Qwen3.5-Omni 发布,一个原生全模态大模型,文本、图片、音频、视频的理解与生成,集于一身。 这不是第一个试图「什么都做」的模型。过去两年,多模态是所

全球首个1毫秒级人体动作捕捉系统FlashCap,通过闪烁LED与事件相机结合,实现1000Hz超高帧率捕捉。无需昂贵设备或强光环境,低成本穿戴服即可精准捕捉极速动作。团队同步开源715万帧的FlashMotion数据集与多模态模型ResPose,显著提升运动分析精度,推动体育、VR与机器人领域迈向高动态智能新阶段。

本文综合北京大学王选计算机研究所发布的 ProactiveVideoQA 和 MMDuet2 两篇论文,介绍视频多模态大模型如何实现 “主动交互”—— 在视频播放过程中自主决定何时发起回复,而非等待用户提问。ProactiveVideoQA 提出评估指标和 benchmark,MMDuet2 则通过强化学习训练方法实现了 SOTA 性能,无需精确的回复时间标注即可训练出及时、准确的主动交互模型。

国产大模型阵营再添硬核选手,智谱开放平台GLM5.1正式上线,推理、代码、智能体能力拉满,还为新用户准备了2000万Tokens免费体验包,覆盖多模型使用额度,有效期3个月。不管是日常编程开发、智能体搭建,还是多模态内容创作,这个免费额度都能轻松拿捏,新手也能零门槛上手,这波福利可别错过。