
全球首个多模态创意营销 Claw 来了,好创意比以前更值钱了
全球首个多模态创意营销 Claw 来了,好创意比以前更值钱了恰好最近,我留意到常用的一个视频生成工具 Vidu,上线了 ViduClaw 「V 龙」——全球首个多模态创意营销 Claw。虽然此前已有不少 AI 厂商推出了自家的「Claw」,但作为视频模型厂商,而且做得这么完整的,Vidu 是我见到的业内头一个。
来自主题: AI资讯
9323 点击 2026-03-28 20:44
 搜索
搜索
恰好最近,我留意到常用的一个视频生成工具 Vidu,上线了 ViduClaw 「V 龙」——全球首个多模态创意营销 Claw。虽然此前已有不少 AI 厂商推出了自家的「Claw」,但作为视频模型厂商,而且做得这么完整的,Vidu 是我见到的业内头一个。
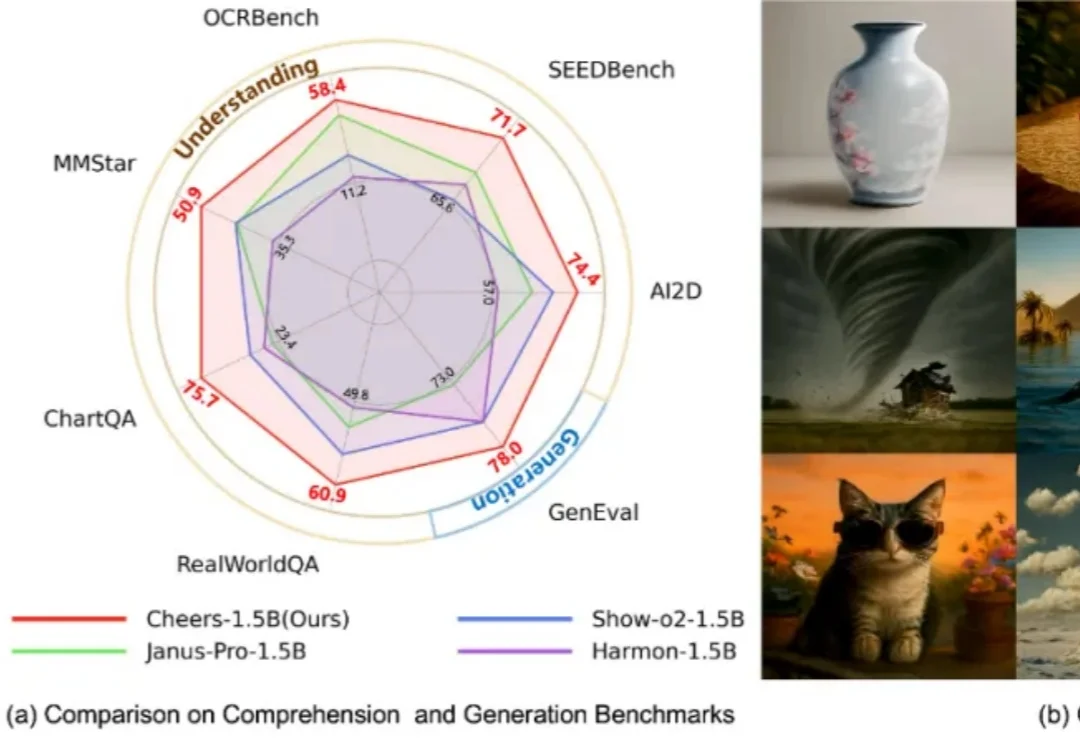
过去几年,多模态模型在理解任务上快速演进,图像问答、OCR、视觉推理、跨模态对话等能力不断提升;与此同时,图像生成模型也在视觉质量、指令遵循和细节表达上持续突破。下一步一个自然的问题是:能否用同一个模型,同时做好理解与生成?这正是统一多模态模型(Unified Multimodal Models, UMMs)正在回答的问题。
一家企业花了七周时间部署 AI:第 1 周精准回答行业分析问题,团队欢呼;第 3 周反复回答相同的错误结论,因为它“忘了”上周的修正;第 5 周在董事会汇报中引用了已被否定的数据,造成决策偏差;第 7 周项目暂停,“AI 不可信”成为共识。问题不在于 AI 不够聪明,而在于它每次醒来都是一张白纸。

36氪获悉,以AI为核心的数字内容公司珀乐互动科技(下称“珀乐互动”)已完成天使轮融资,金额为数千万元人民币。本轮投资由星连资本领投、春华创投跟投,资金将重点用于技术研发、团队扩充与IP商业化开发,全面加速公司多模态泛娱乐生态的战略布局。
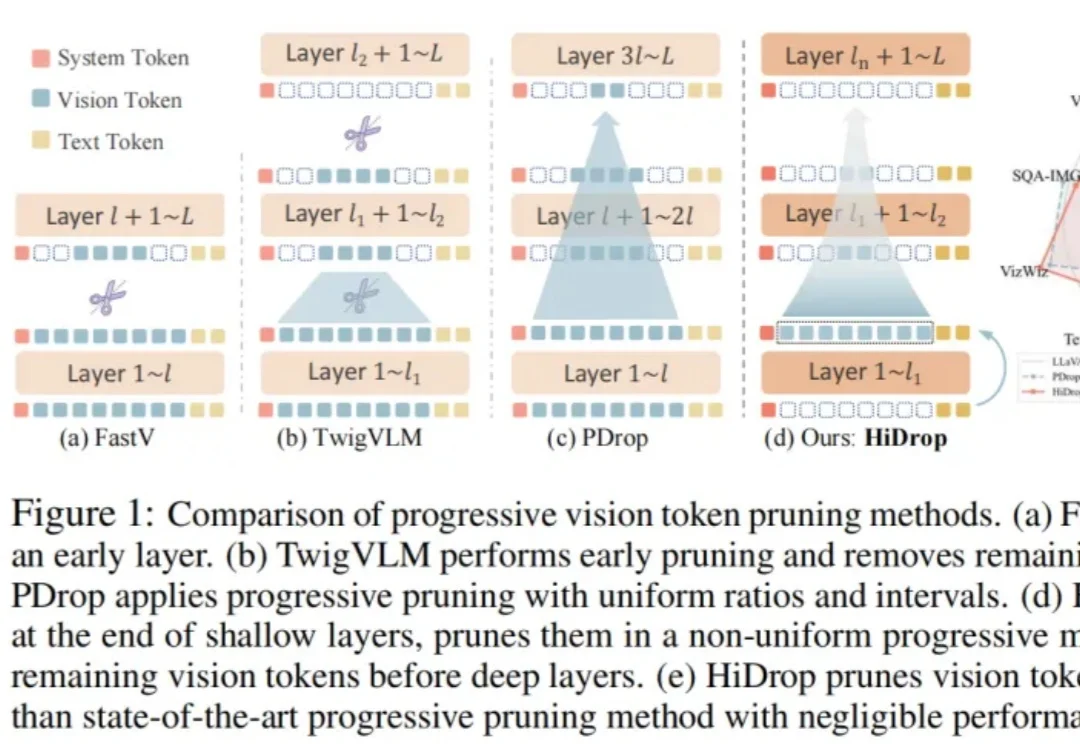
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
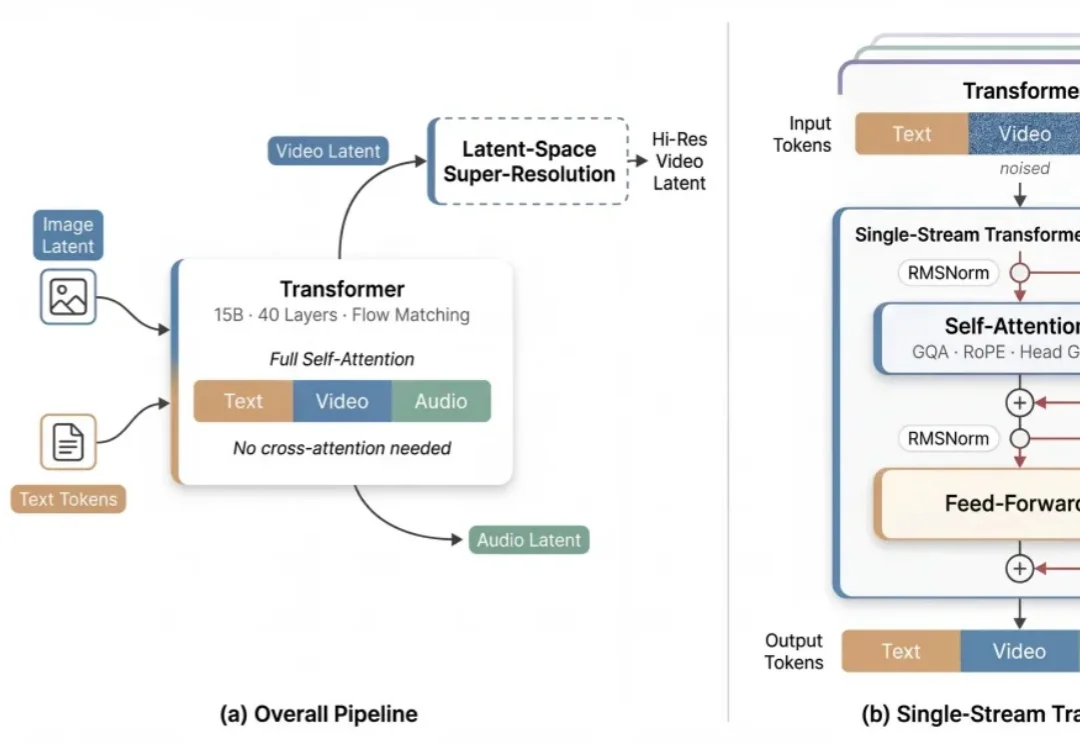
开源多模态生成领域,迎来架构级的底层突破。

一张蓝锥嘴雀的图片,你能认出它是“鸟”,但能认出它是“鸟纲-雀形目-唐纳雀科-锥嘴雀属-蓝锥嘴雀”吗?

多模态大模型,到底有多“嘴硬”? 浙江大学联合阿里巴巴、香港城市大

今天,机器之心获悉,腾讯 TEG 技术工程事业群组织架构发生了部分调整,AI Lab 被撤销,蒋杰不再担任 AI Lab 主任,但其他管理职责不变。此次调整过后,原 AI Lab 部分人员调整至混元团队向姚顺雨汇报。产学研合作中心保留。多模态部负责人向 TEG 总裁卢山汇报。
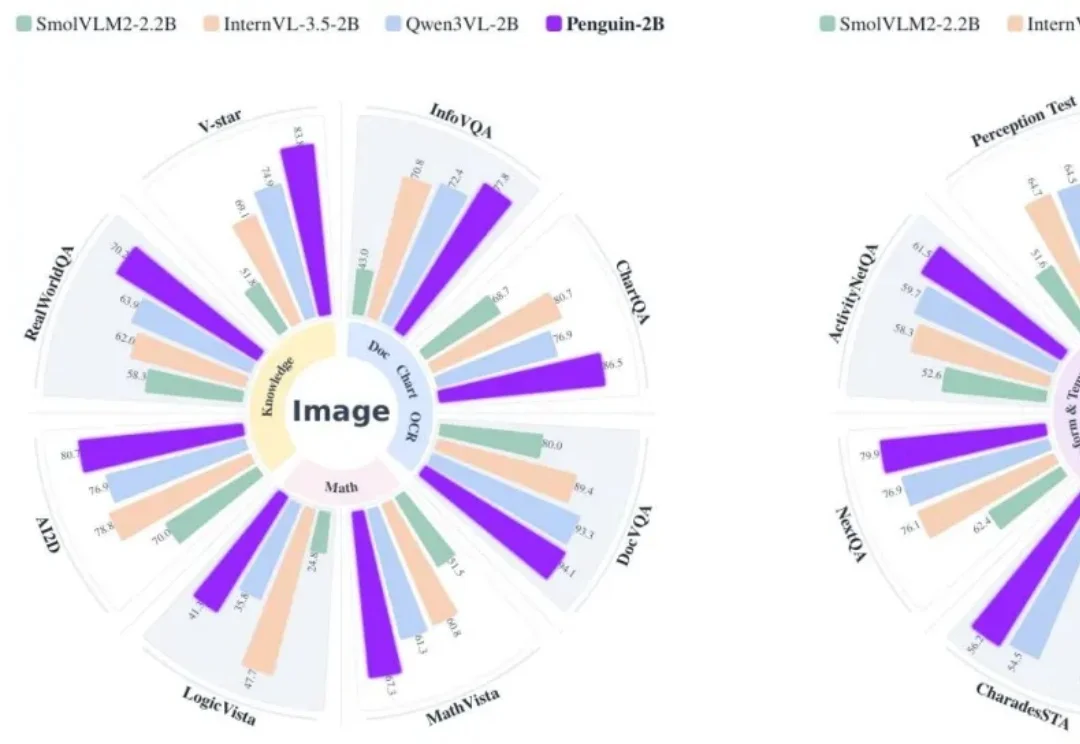
打破多模态视觉+语言拼接套路!