
给GUI Agent装上「世界模型」:阿里通义用混合数据+统一思维链,让模型学会预判屏幕变化
给GUI Agent装上「世界模型」:阿里通义用混合数据+统一思维链,让模型学会预判屏幕变化伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。
来自主题: AI技术研报
9676 点击 2026-03-04 13:43
 搜索
搜索
伴随多模态大模型的发展,GUI Agent正成为人机交互的新范式。

没有图片,也能预训练多模态大模型?在多模态大模型(MLLM)的研发中,行业内长期遵循着一个昂贵的共识:没有图文对(Image-Text Pairs),就没有多模态能力。

我天!感觉 Seed 1.8 发布还没多久,没想到 Doubao-Seed-2.0 这么快就杀到了…今天发都算是晚讯了。据官方介绍,这次 Seed 2.0 多模态理解能力全面升级,还强化了 LLM 与 Agent 能力,模型在真实长链路任务中可以稳定推进。

DeepSeek V4下周登场:原生多模态,绕过英伟达,针对国产芯片深度优化。华尔街最怕的那条逻辑可能又要重演:算力霸权松动,美股先颤抖。

Meta联合多所高校发布首个可规模化自动生成第一视角音视频理解数据的引擎EgoAVU ,让多模态大模型首次真正「听懂世界」。
VUI Labs(宇生月伴)宣布完成数千万元天使+轮融资。本轮投资由同创伟业领投、老股东靖亚资本、小苗朗程持续加注,心流资本FlowCapital担任长期财务顾问。公司半年累计获得近亿元投资,所募资金
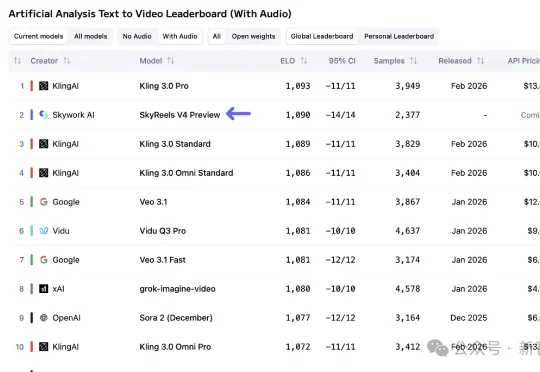
当Seedance 2.0刷屏全网时,一匹中国黑马已悄然冲上全球AI视频榜第二。昆仑天工SkyReels-V4强势杀入顶级牌桌,多模态输入、音画同步直出影院级大片,实力惊艳超群!
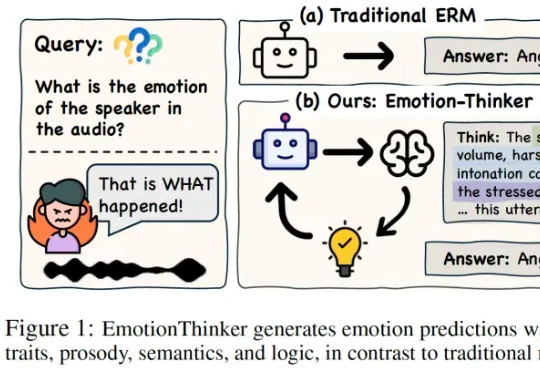
SpeechLLM 是否具备像人类一样解释 “为什么” 做出情绪判断的能力?为此,研究团队提出了EmotionThinker—— 首个面向可解释情感推理(Explainable Emotion Reasoning)的强化学习框架,尝试将 SER 从 “分类任务” 提升为 “多模态证据驱动的推理任务”。
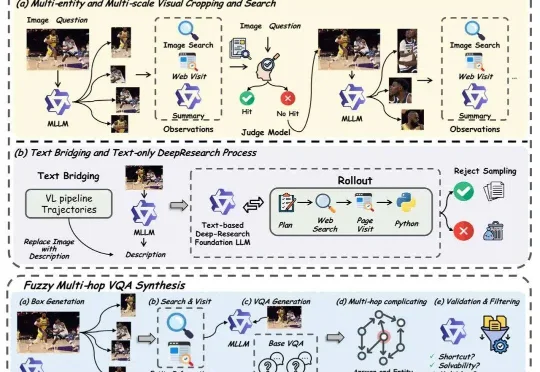
DeepResearch 的价值在于把「查资料」变成「做研究」:不是搜到一条就回答,而是会连续多轮地提出问题、去不同地方找证据、互相对照核实、再把信息整理成结构清晰的结论。这样做能显著降低「凭感觉瞎编
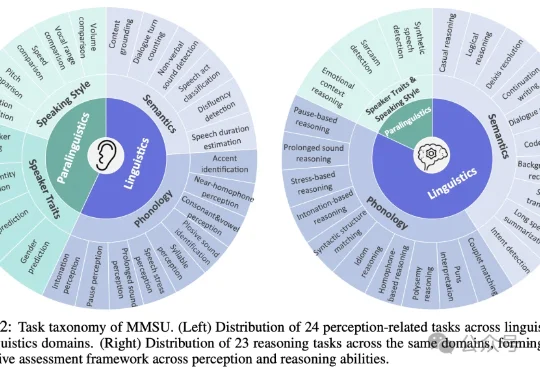
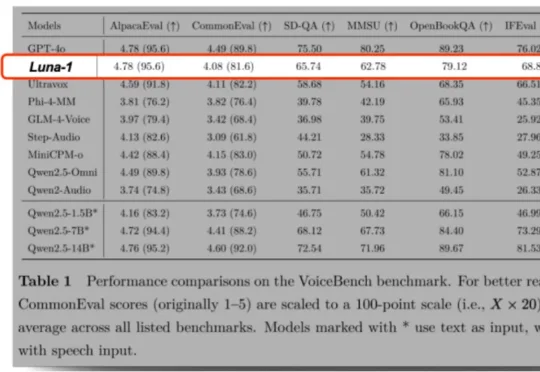
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?