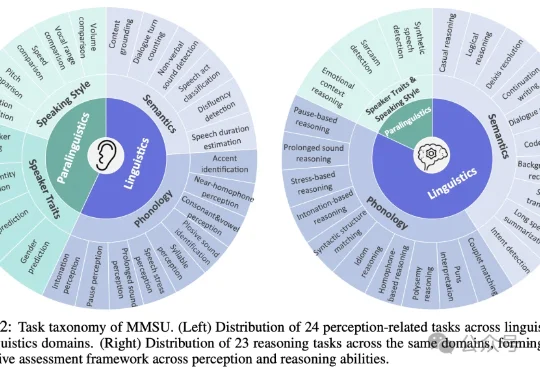
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26
大模型真听懂了吗?最全综合性口语感知与推理基准 | ICLR'26随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
来自主题: AI技术研报
11104 点击 2026-02-24 15:35
 搜索
搜索
随着多模态大模型能力不断扩展,语音大模型(SpeechLLMs) 已从语音识别走向复杂语音交互。然而,当模型逐渐进入真实口语交互场景,一个更基础的问题浮现出来:我们是否真正定义清楚了「语音理解」的能力边界?
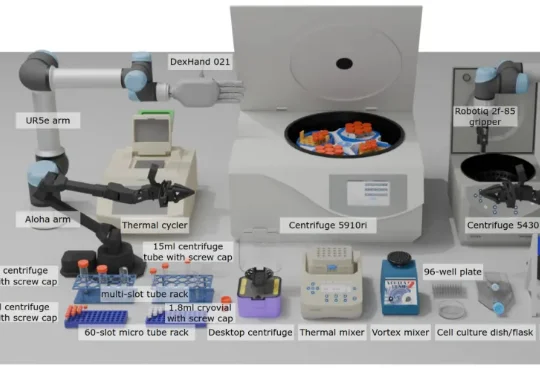
现有 VLA 模型的研究和基准测试多局限于家庭场景(如整理餐桌、折叠衣物),缺乏对专业科学场景(尤其是生物实验室)的适配。生物实验室具有实验流程结构化、操作精度要求高、多模态交互复杂(透明容器、数字界面)等特点,是评估 VLA 模型精准操作、视觉推理和指令遵循能力的理想场景之一。

千问 3.5 总参数量仅 3970 亿,激活参数更是只有 170 亿,不到上一代万亿参数模型 Qwen3-Max 的四分之一,性能大幅提升、还顺带实现了原生多模态能力的代际跃迁。

没有让我们等待多久,阿里刚刚正式发布并开源了 Qwen3.5 系列模型,页面显示有两款模型,分别为最新大语言模型的 Qwen3.5-Plus,以及定位为开源系列旗舰的 Qwen3.5-397B-A17B。两者均支持文本处理与多模态任务。

结果今天就等到豆包全家族了。Seedance 2.0都把贾樟柯干Fomo了,现在又上了个最全面的多模态Agent模型,还有人管管字节吗?Seed团队跳动得停不下来了💃烧的全是火山引擎上的Tokens,同时火山引擎上已经有豆包2.0系列的API了。
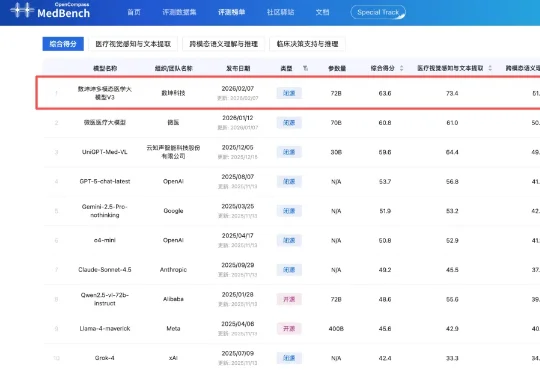
2月7日,中文医疗大模型评测平台MedBench公布最新多模态大模型评测榜单,数坤科技的数坤坤多模态医学大模型V3以63.6分拿下第一。在榜单中,V3的表现超过微医、云知声旗下医疗行业大模型,以及OpenAI、谷歌、阿里千问旗下通用大模型。
这个国产开源模型,把多模态玩出了“魔法”感。

梦瑶 发自 凹非寺 量子位 | 公众号 QbitAI 不是,谁也没跟我说今年的AI春节大战搞得这么猛猛猛啊!?! 年还没到呢,可灵就超绝不经意甩出一个「过大年计划」:推出可灵3.0多模态全家桶。 让每
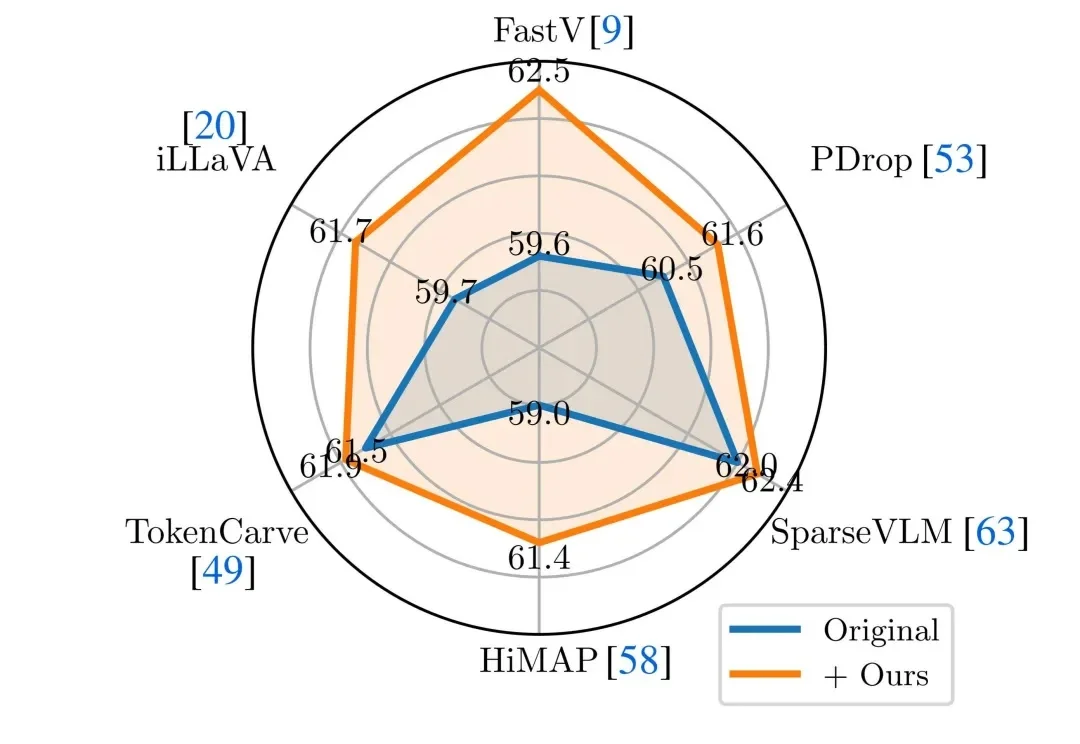
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
今天,北京多模态生成技术创企生数科技宣布完成超过6亿元人民币A+轮融资。生数科技还披露,2025年该公司实现用户和收入超10倍增长,用户和业务覆盖全球200多个国家和地区。