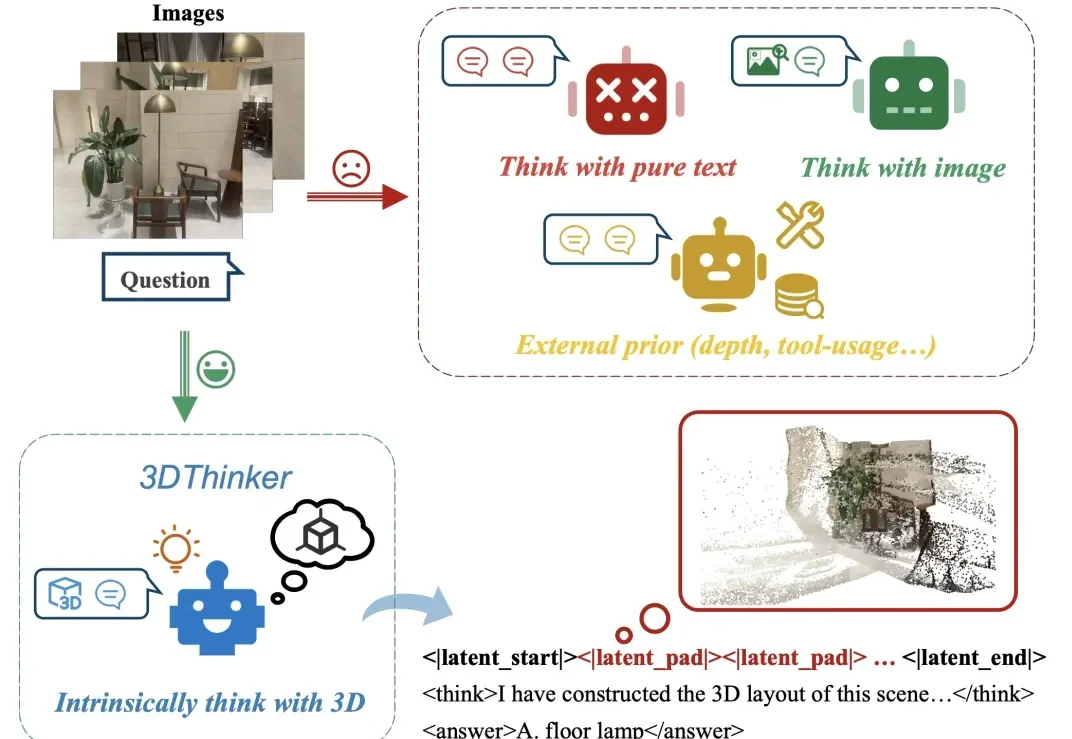
CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作
CVPR 2026|清华联合美团推出3DThinker,首个用3D意象思考的工作大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。
来自主题: AI技术研报
9495 点击 2026-03-11 09:25
 搜索
搜索
大家是否有这样的感觉?给定几张场景中拍摄的图片,往往能够在脑海中想象出这个场景的三维布局,然而当前的多模态大模型还停留于纯文本或者 2D 视觉的推理表示,限制了图像中隐含几何结构的表达能力。

NUS、ZJU、UW、Stanford、CUHK 联合提出 「ThinkMorph」,主张让文字与图像在统一架构里「原生协作」、「共同演化」,而不是像当下大多数多模态模型那样,看完图像就闭上眼睛,后续完全靠文字链条推进。仅用 2.4 万条数据微调 7B 统一模型,视觉推理平均提升 34.74%,多项任务比肩甚至超越 GPT-4o 和 Gemini 2.5 Flash。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。
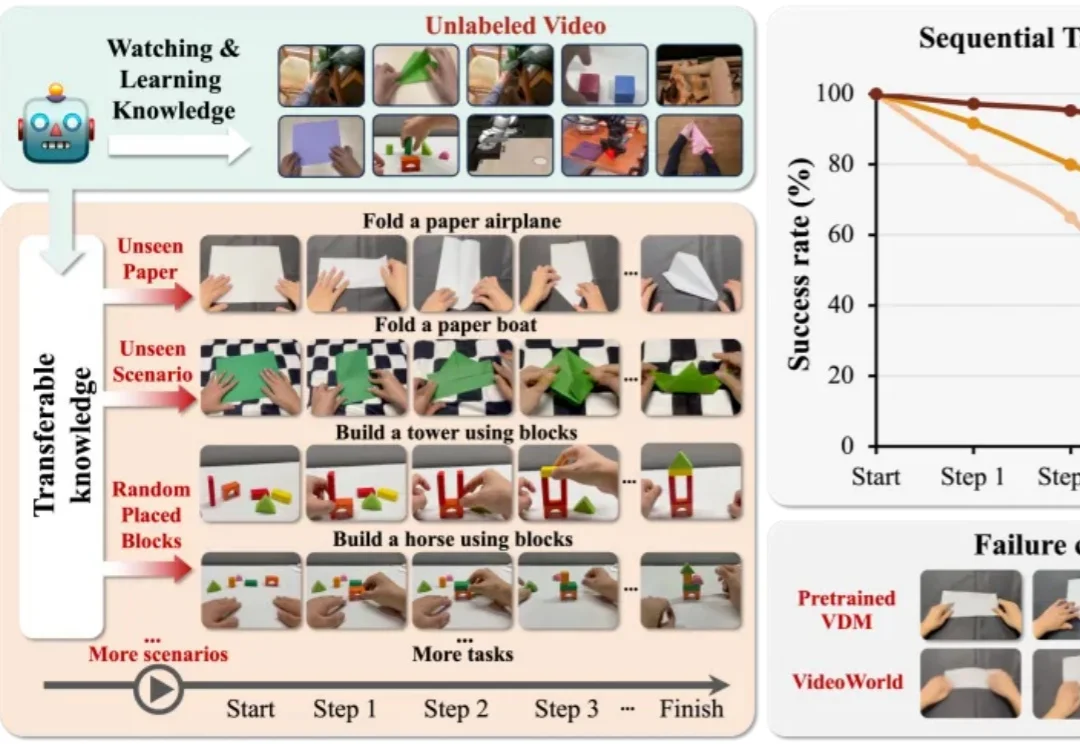
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
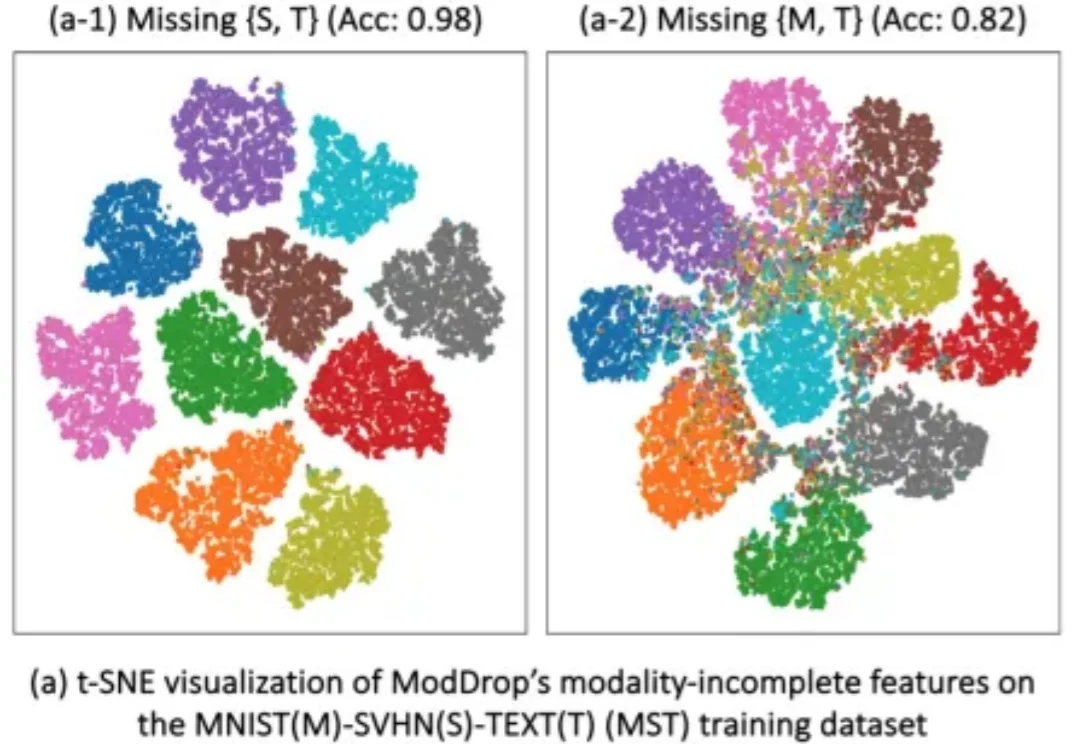
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
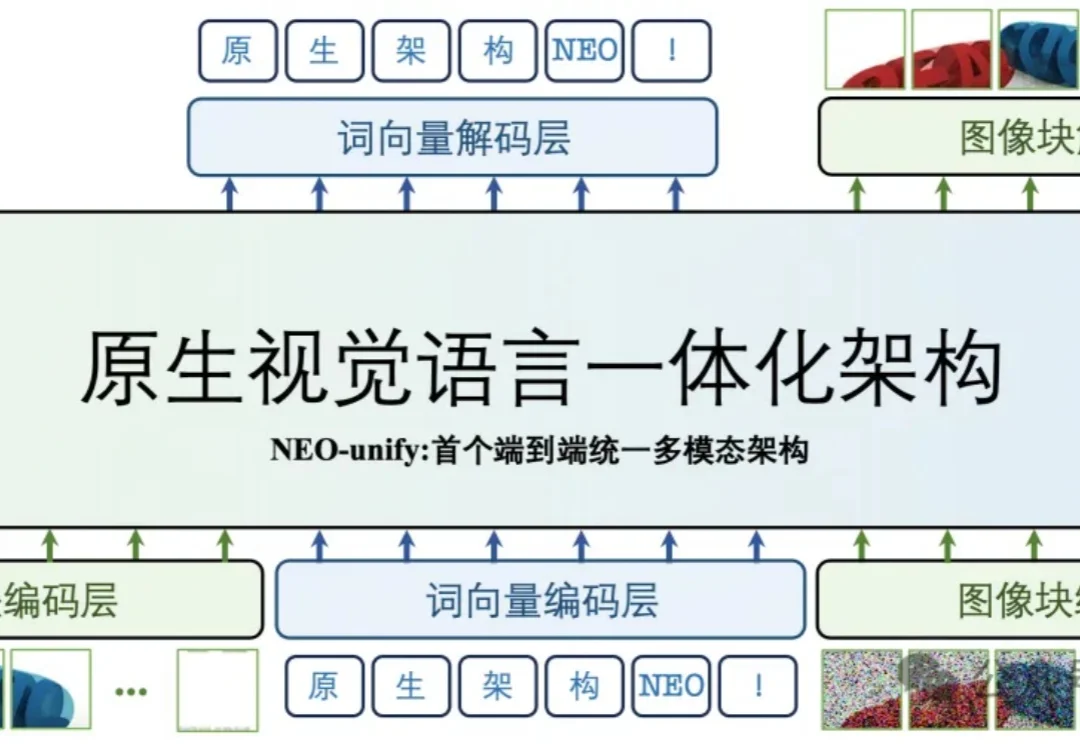
多模态大模型的研发范式,正在被彻底重构。
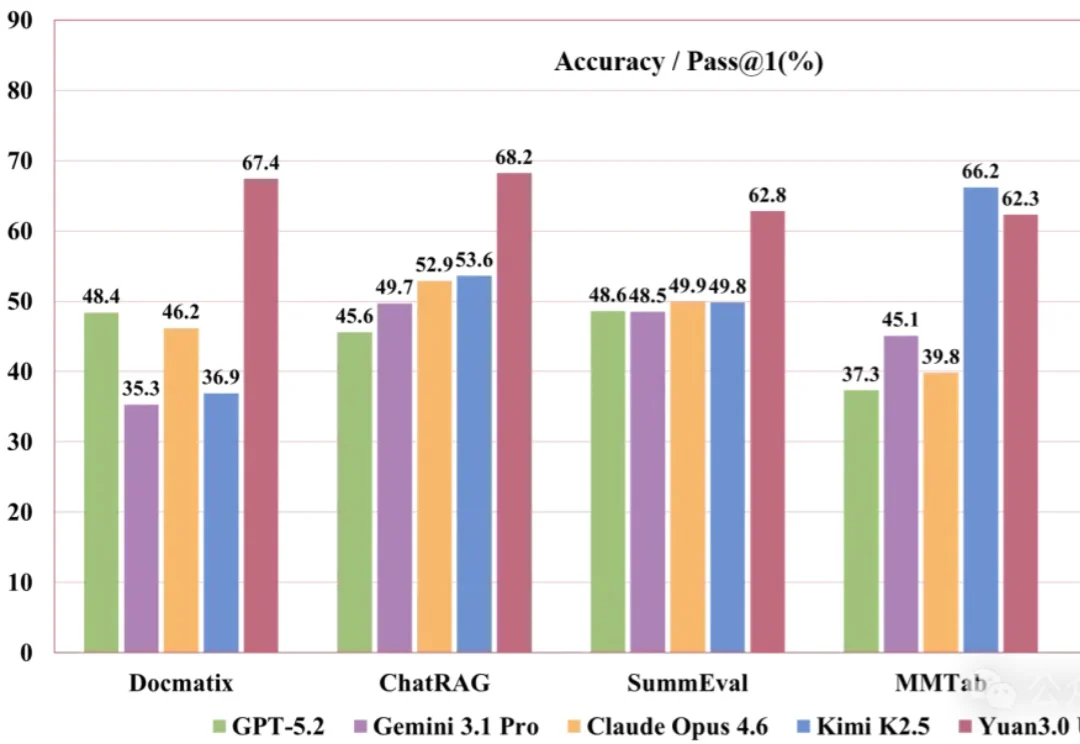
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
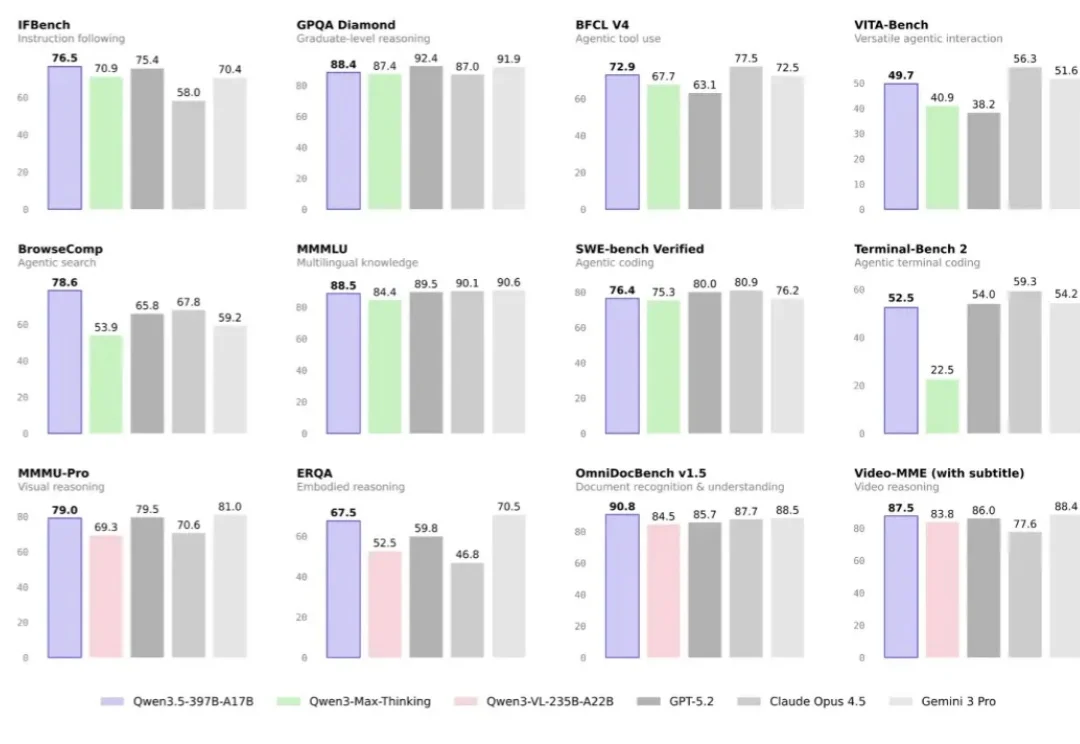
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。
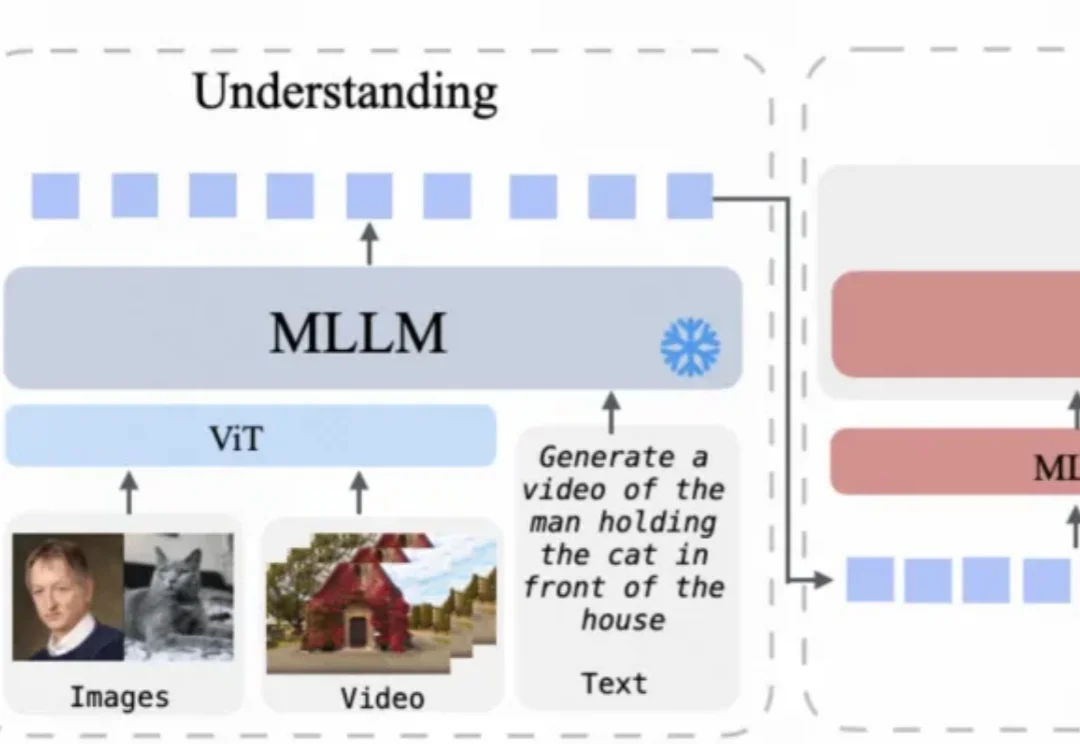
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。